Un auditor abre tu archivo de exportación, encuentra un saldo de cierre de 47.500 € y saca el PDF de origen. Página 3, esquina inferior derecha: 47.000 €. Un número diferente. "¿De dónde viene la diferencia? ¿Quién lo cambió?"
Si tu sistema de extracción no puede responder a esa pregunta en menos de un minuto, tienes un problema. No un problema de "probablemente deberíamos documentar esto mejor". Un problema de cumplimiento (compliance). Del tipo en el que alguien pide ver el rastro documental y te das cuenta de que no existe.
Los procesos manuales tienen esto resuelto. Notas adhesivas, iniciales, tachaduras, firmas con fecha en el margen. Cuando María en contabilidad corrige una cifra, deja evidencia. Cuando tu pipeline de extracción por IA corrige una cifra, simplemente... sobrescribe.
Los datos son correctos. Falta la confianza.
La realidad del cumplimiento
Las industrias reguladas no solo necesitan números correctos. Necesitan procedencia (provenance). No un "estamos bastante seguros de que esto está bien", sino "aquí está el píxel exacto en la página 83, aquí está quién lo validó, aquí está la marca de tiempo".
Servicios financieros, seguros, empresas de contabilidad: todos viven en territorio de auditoría. La pregunta no es solo "¿cuál es el valor?". Es "¿cómo llegamos a este valor?". Y esa segunda pregunta tiene que sobrevivir a un examinador escéptico que asume que cometiste un error hasta que se demuestre lo contrario.
La ironía es que se suponía que la automatización reduciría el riesgo. Menos toques humanos, menos errores de transcripción, más consistencia. Todo cierto. Pero la automatización también creó una nueva categoría de cambios invisibles. El motor OCR interpreta silenciosamente un "7" manchado como un "1". La capa de normalización invierte un saldo negativo a positivo porque así es como el banco representa los débitos. El modelo de extracción elige uno de dos totales posibles porque la página tenía encabezados duplicados.
Cada una de estas es una decisión. Cada una cambia el resultado (output). Y a menos que las estés rastreando, tu rastro de auditoría tiene agujeros que no puedes ver.
Cómo se ven realmente las mutaciones
Antes de mirar las mutaciones en sí, vale la pena preguntar: ¿cómo terminan los humanos editando datos extraídos en primer lugar?
En Holofin, comienza con la validación. Después de la extracción, las reglas de negocio se ejecutan automáticamente contra los datos. Para los extractos bancarios, eso significa ecuaciones de saldo: ¿el saldo inicial más los créditos menos los débitos es igual al saldo de cierre? Si los números no cuadran con un margen de 0,02 €, el sistema lo marca antes de que nadie exporte nada.
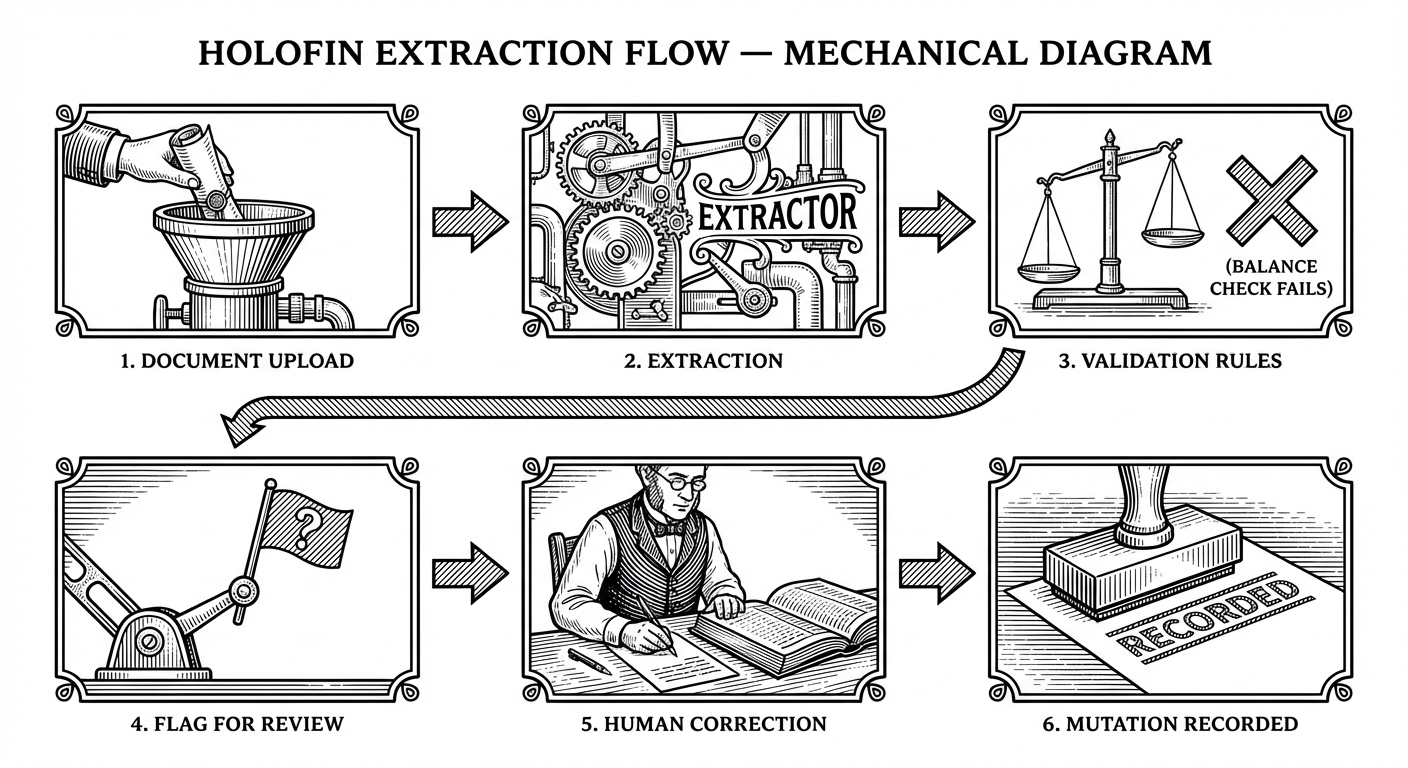
Esa alerta es lo que atrae a un humano. Abren el documento lado a lado con el PDF de origen y encuentran el problema: una transacción perdida, un dígito mal leído, un duplicado que infló el total. Sin validación, el error viaja silenciosamente a los sistemas posteriores (downstream). Con ella, la revisión es dirigida: no le pides a alguien que vuelva a verificar 200 transacciones, le indicas "página 12, los créditos no cuadran, aquí es donde debes mirar".
El humano hace una corrección. Esa corrección es una mutación. Y cada mutación se registra con atribución completa, porque este es el rastro de auditoría:
Un usuario añade una transacción faltante.
El OCR omitió una línea tenue: tal vez la impresora se estaba quedando sin tóner, tal vez el escaneo estaba en un mal ángulo. El usuario ve el hueco en el resumen de validación, abre el PDF de origen, encuentra la línea y añade la transacción manualmente. ¿Qué se registra?
Quién la añadió, cuándo, qué valores introdujo y, fundamentalmente, de qué página y coordenadas proviene la transacción. El usuario está afirmando "estos datos existen en el documento de origen en esta ubicación". Esa afirmación debe ser auditable.
Un usuario corrige un error de OCR.
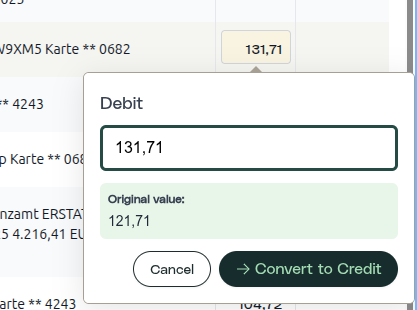
1.238,45 € se extrajeron como 1.236,45 €. En un mal escaneo, el OCR leyó un 8 como un 6. La validación marcó un desajuste de saldo de 2 €. El usuario abre el PDF de origen, detecta el dígito manchado, lo arregla. ¿Qué se registra?
Valor original. Nuevo valor. Usuario. Marca de tiempo. Y el cuadro delimitador (bounding box) del texto de origen, para que un auditor pueda verificar visualmente la corrección contra el documento original.
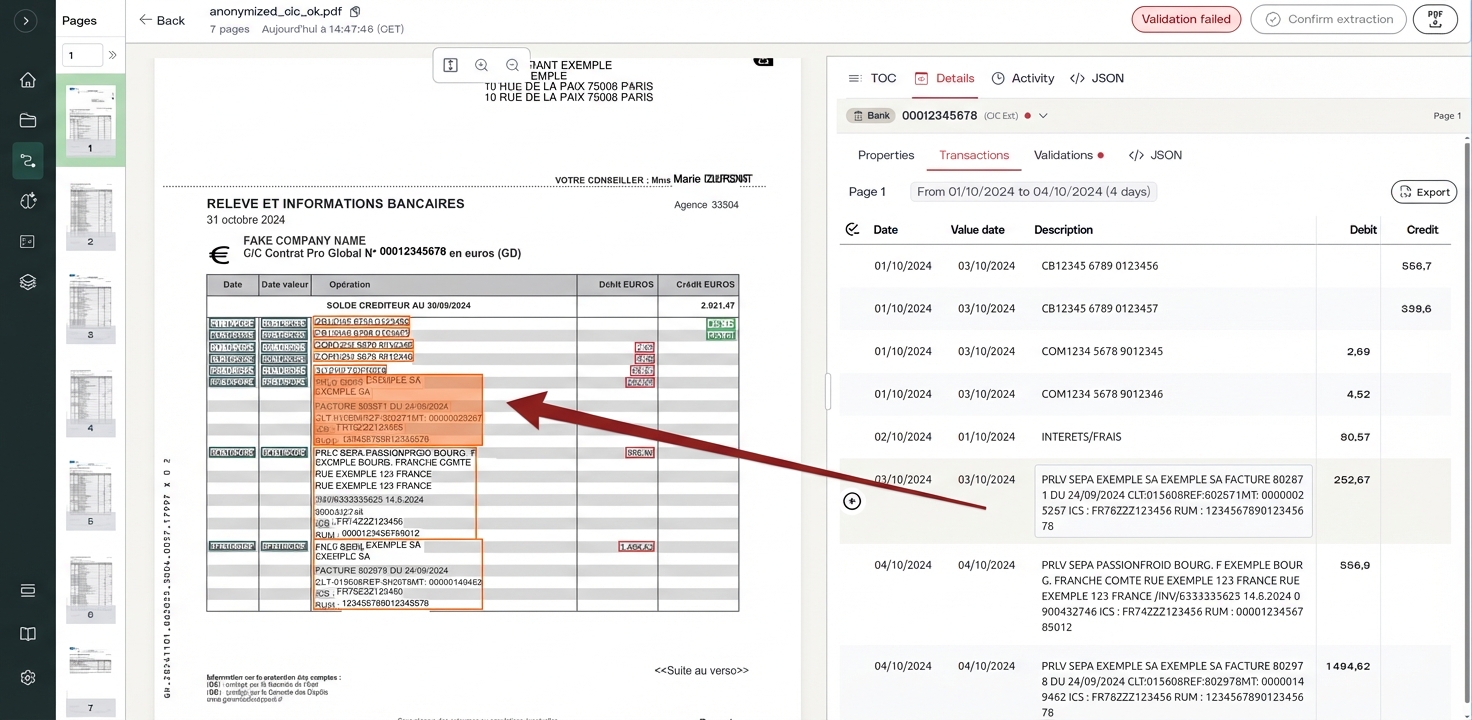
Cada número tiene una dirección
La mayoría de los sistemas de extracción te dan un valor. Un buen sistema de extracción te da un valor y su ubicación exacta en el documento de origen.
En Holofin, cada campo extraído lleva un bounding box: un conjunto de coordenadas que marcan el rectángulo preciso en la página donde se leyeron los datos. No "página 3", sino "página 3, 72% desde el borde izquierdo, 45% hacia abajo, este grupo exacto de píxeles".
Esto no es un bonito detalle de diagnóstico. Es la base de todo el rastro de auditoría.
Cuando un auditor cuestiona un número, no solo dices "salió del PDF". Se lo muestras. El documento de origen se abre con el área relevante resaltada. El valor extraído se sitúa junto al original. El auditor puede ver, con sus propios ojos, que el sistema leyó lo correcto o entender exactamente por qué un humano lo corrigió.

Este vínculo espacial también detecta una categoría de fallos silenciosos que la extracción basada solo en texto pasa por alto por completo. Valores asignados a la columna incorrecta porque la tabla no tenía líneas de cuadrícula. Un total extraído de una fila de subtotal porque el diseño cambió a mitad de página. Un encabezado que abarca dos columnas, haciendo que cada valor debajo de él se desplace una celda a la derecha. Sin coordenadas, estos errores producen resultados de apariencia plausible que pasan todas las comprobaciones basadas en texto. Con coordenadas, puedes verificar que el número etiquetado como "saldo de cierre" realmente provino de la posición del saldo de cierre en la página.
El bounding box convierte el "confía en mí" en "míralo tú mismo".
Este vínculo espacial persiste a través de cada cambio. Correcciones, eliminaciones, restauraciones: cada mutación mantiene sus coordenadas de origen. Nada se destruye. Todo se remonta a los píxeles de los que provino.
Cuando llama el auditor
Volvamos a ese auditor con el saldo que no cuadra.
Con un rastro de mutación adecuado, la respuesta es inmediata:
"La IA extrajo 47.000 € de la página 3. El 15 de enero a las 14:32, Marie Dubois lo corrigió a 47.500 €: la página 47 contiene una entrada de ajuste manual que la extracción inicial omitió debido a un formato no estándar. Aquí está el documento de origen con ambas ubicaciones resaltadas y el registro de corrección con marca de tiempo."
Compara eso con: "Déjame consultarlo con el equipo y te digo algo".
La primera respuesta genera confianza. La segunda desencadena una investigación más profunda.
Dos visiones de la misma verdad
Todo este rastro aparece en dos lugares: la UI y la API.
En la UI de Holofin, cada extracción tiene un registro de actividad. Los usuarios ven cada corrección tal como sucedió: quién cambió qué, cuándo y de qué valor a cuál. Es la historia del documento, contada cronológicamente. Cuando un miembro del equipo abre una extracción en la que trabajó otra persona, puede reconstruir cada decisión sin hacer una sola pregunta.
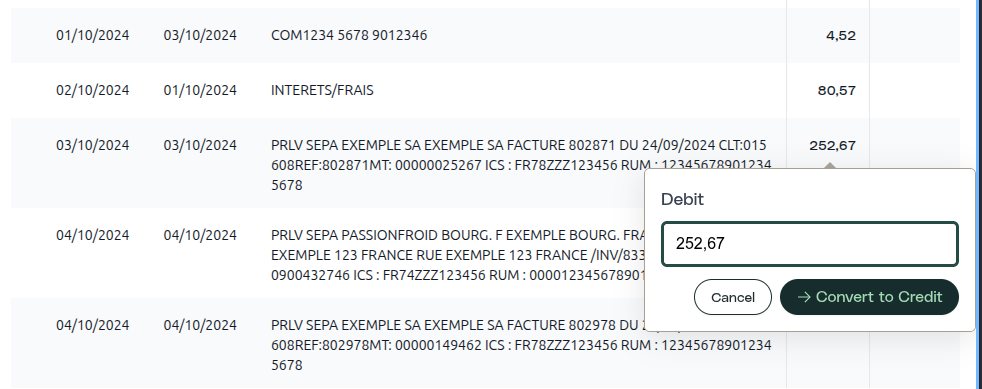
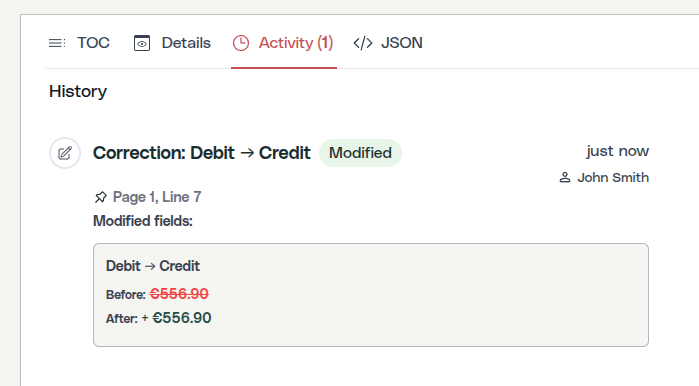
En la exportación de la API, los mismos datos vienen estructurados. Cada exportación de documento incluye su historial de mutaciones junto con los datos extraídos, tipo de mutación, usuario, marca de tiempo, valores antes/después, coordenadas de origen. Tus sistemas posteriores no solo reciben números; reciben números con procedencia. Una plataforma de contabilidad que consuma la API puede mostrar a sus propios auditores exactamente dónde se originó cada cifra y quién la validó.
Esto importa porque no todos los auditores trabajan en la misma herramienta. Algunos verificarán el rastro directamente en Holofin. Otros lo querrán en su propio sistema. Los datos deben ser portables.
Hemos estado en suficientes conversaciones de auditoría para saberlo: la pregunta nunca es "¿son correctos los datos?". La pregunta siempre es "¿puedes demostrarlo?".
El coste de no tener esto
Construir rastros de auditoría requiere esfuerzo de ingeniería. Cada tipo de mutación necesita un esquema. Cada cambio de estado necesita un registro. Cada registro debe ser consultable, exportable y retenido durante el período legalmente requerido.
La alternativa es peor.
Un hallazgo de auditoría que no puedas explicar crea más trabajo que un año de seguimiento de mutaciones. Un cliente que pierde la confianza en la procedencia de tus datos crea más daño que el coste de ingeniería de hacerlo bien.
El mejor sistema de extracción es el que puede explicarse a sí mismo.
Los datos son el resultado. El rastro de auditoría es la confianza.
Artículos relacionados
Cuando los documentos contraatacan
Página 1: Resumen de cuenta, dos columnas. Página 15: Misma cuenta, tres columnas, nombres de encabezado diferentes. Página 47: Un escaneo con una mancha de café. Página 89: La página de totales, que hace referencia a transacciones que extrajiste hace 70 páginas.

HoloRecall: Muestra, no cuentes
Hay un momento en todo proyecto de clasificación donde ves al modelo equivocarse con total confianza. No es un caso difícil. No es un caso límite ambiguo. Es algo que un humano resolvería en medio segundo sin pensarlo.

Tu LLM no es un pipeline de documentos
Hay un momento en todo proyecto de IA donde la demo se ve tan bien que tu cerebro empieza a borrar código silenciosamente. Ves un modelo "leer" un extracto bancario y piensas: esto es. Podemos saltarnos el OCR. Podemos saltarnos el análisis de layout. Quizás podemos saltarnos la mitad del pipeline. En la versión de película, alguien presiona Enter y cae una cascada de JSON desde la nube.