Hay un momento en todo proyecto de clasificación donde ves al modelo equivocarse con total confianza. No es un caso difícil. No es un caso límite ambiguo. Es algo que un humano resolvería en medio segundo sin pensarlo.
Revisas el prompt. La clase está definida. La definición es precisa. El modelo la leyó, la entendió y aun así eligió mal. Añades una frase aclaratoria. Quizás una excepción. Quizás una cláusula de "no confundir con" o "IMPORTANTE". Funciona para ese caso. Luego llega un nuevo fallo, estructuralmente idéntico al anterior pero lo suficientemente diferente como para que tu parche no lo cubriera.
Esta es la cinta de correr de la ingeniería de prompts. Hemos estado ahí. Hemos añadido cientos de líneas de instrucciones de clasificación, viendo cómo la precisión subía y luego se estancaba. Los casos límite se seguían acumulando y los prompts se volvieron tan largos que el modelo empezó a ignorar partes importantes.
En algún momento nos detuvimos y planteamos una pregunta diferente: ¿y si describir las clases no es el enfoque correcto en absoluto?
La respuesta se convirtió en HoloRecall. Un sistema que enseña a los clasificadores mediante ejemplos en lugar de explicaciones. En lugar de escribir definiciones cada vez más largas, mostramos al modelo cómo se ve cada clase.
Así es como los humanos aprenden realmente los tipos de documentos. Piensa en la incorporación de un nuevo analista para clasificar documentos bancarios. No le das un manual que defina "Extracto Bancario" frente a "Resumen de Cuenta" en términos abstractos. Te sientas con él con ejemplos: "Esto es un extracto bancario. Mira la tabla de transacciones, cada fila tiene fecha, descripción y monto. Saldo acumulado a la derecha. Esto es un resumen de cuenta, sin transacciones individuales, solo saldos agrupados por tipo de cuenta, quizás un gráfico circular. Ambos vienen del mismo banco. Ambos tienen números de cuenta y montos en dólares/euros. Pero mira la estructura. Aprenderás a reconocerlos".
Eso es lo que hace HoloRecall por tu clasificador.
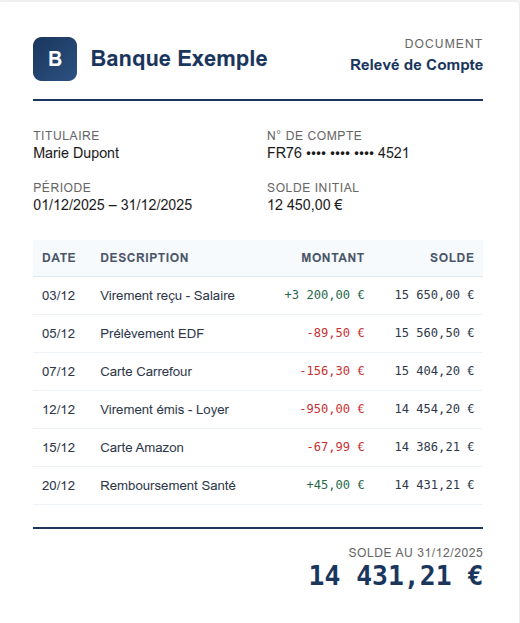

Bank statement: Detalle a nivel de transacción, saldo acumulado.
Account summary: Saldos agregados, sin transacciones individuales.
What they share: Números de cuenta, fechas, saldos—a menudo del mismo banco. La superposición semántica es alta. La similitud visual es baja.
La cinta de correr de la ingeniería de prompts
Seamos específicos sobre qué sale mal.
Estás clasificando documentos financieros. Tienes una categoría llamada "Bank Statement" y otra llamada "Account Summary". Ambas pueden contener números de cuenta, saldos, listas de transacciones. La superposición semántica es real. Así que escribes definiciones cuidadosas: los extractos bancarios muestran detalles a nivel de transacción con fechas y montos; los resúmenes de cuenta agregan saldos entre cuentas sin transacciones individuales.
Funciona. Mayormente.
Entonces un banco envía un "Estado de Cuenta" que está formateado como un resumen pero contiene transacciones. Luego otro banco envía un "Resumen Mensual" que es en realidad un extracto completo. Luego un tercer banco envía algo que es genuinamente ambiguo incluso para los humanos—y tu clasificador elige con confianza y se equivoca.
Cada fallo te enseña algo. Codificas esa lección en el prompt. El prompt crece. Añades ejemplos en las instrucciones: "Un Bank Statement típicamente se ve como X. Un Account Summary típicamente se ve como Y". Pero "típicamente" está haciendo mucho trabajo, y las excepciones siguen apareciendo.
El problema fundamental no es que el modelo sea estúpido. Es que el lenguaje es una codificación ineficiente para patrones visuales. Estás tratando de describir, con palabras, diferencias que los humanos perciben instantáneamente a través del diseño, la estructura y la disposición espacial.
Los prompts capturan bien la semántica. Capturan mal la estructura visual.
El problema de las muchas clases
Esto empeora a medida que crecen las taxonomías.
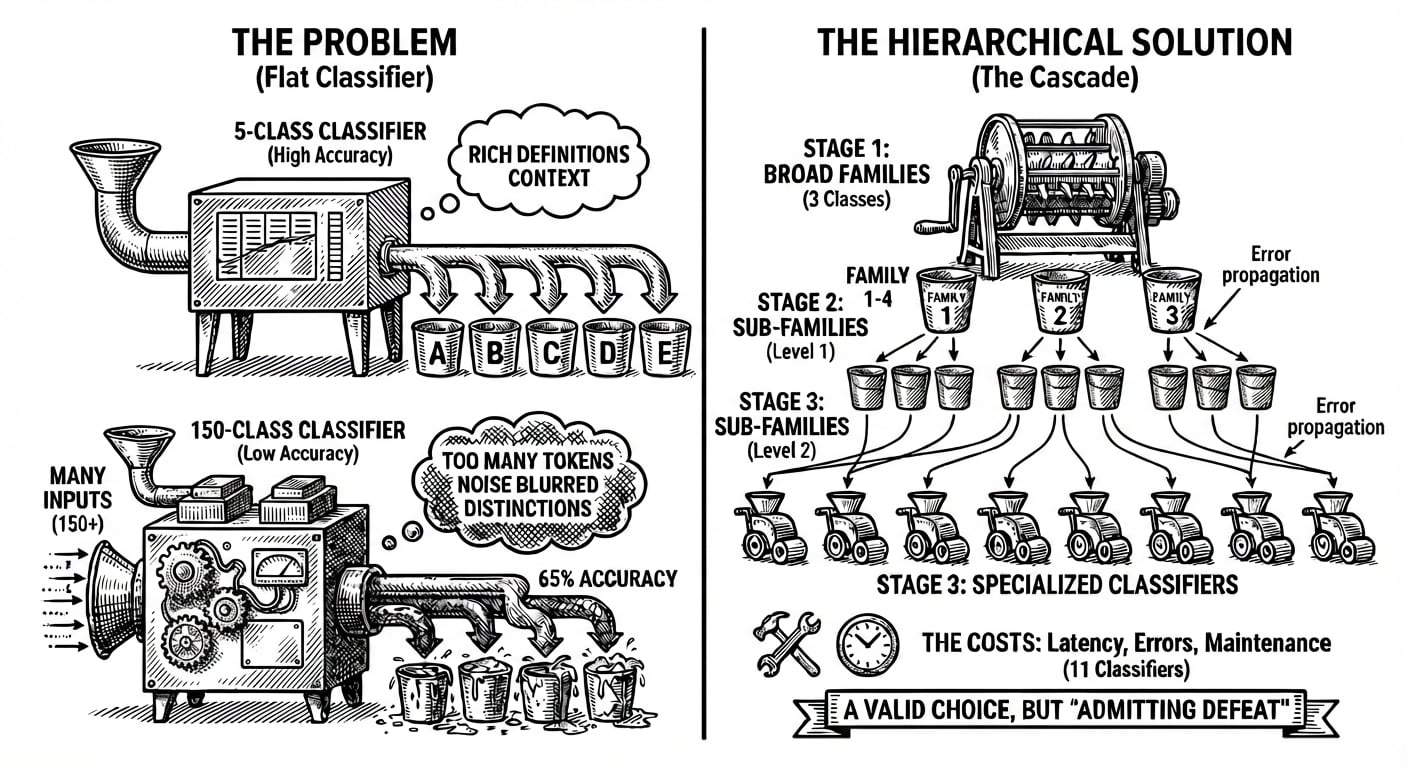
Un clasificador con seis categorías puede incluir definiciones ricas para cada una. El modelo tiene mucho contexto para entender qué hace distinta a cada clase. Pero, ¿qué pasa cuando tienes 50 categorías? ¿O 150? ¿O 300?
Cada definición consume tokens. Cada token compite por la atención del modelo. En algún punto, no estás añadiendo claridad, estás añadiendo ruido. El modelo tiene que mantener tantas descripciones de clases en contexto que las distinciones entre ellas se desdibujan.
Este es un hecho que ha sido probado. Cuando los investigadores probaron la precisión de clasificación a través de conjuntos de datos de complejidad variable, surgió un patrón claro: los modelos lograron más del 94% de precisión en una tarea de sentimiento de seis clases, pero cayeron a alrededor del 65% en una tarea de categorización de aplicaciones de 119 clases. El mismo modelo subyacente. El mismo enfoque de entrenamiento. La diferencia fue el tamaño de la taxonomía.
La solución obvia es la jerarquía. En lugar de un clasificador eligiendo entre 150 clases, construyes una cascada: primero clasificas en 10 familias amplias, luego enrutas a un clasificador especializado para cada familia. Esto funciona. Hemos construido estos sistemas y visto ganancias significativas de precisión en la práctica. De hecho, Holofin está introduciendo este enfoque como parte de nuestra próxima función Workflows (espera un artículo dedicado pronto).
Pero conllevan costos. Cada etapa introduce latencia. Cada etapa puede propagar errores. Si el primer clasificador asigna un documento a la familia equivocada, ninguna cantidad de precisión en la segunda etapa lo salvará. Y el mantenimiento se convierte en un dolor de cabeza: ahora estás ajustando 11 clasificadores en lugar de uno, cada uno con su propio prompt, sus propios casos límite, sus propios modos de fallo.
La clasificación jerárquica es una elección de ingeniería válida. También es, en cierto sentido, admitir la derrota ante el problema de la ingeniería de prompts.
Queríamos algo diferente. Algo que escalara sin multiplicar los prompts.
Por qué el razonamiento no ayuda aquí
En tareas como matemáticas y generación de código, el razonamiento chain-of-thought ayuda. La clasificación no funciona así. Investigaciones recientes —y nuestros propios resultados— encontraron que añadir pasos de razonamiento o no hacía diferencia o perjudicaba activamente el rendimiento. Cuando los modelos "piensan" antes de clasificar, la precisión cae. Cuando emiten la clase primero y explican después, la precisión sube.
Esto tiene sentido cuando consideras cómo los humanos clasifican documentos. No razonas tu camino para reconocer una factura. La miras y lo sabes. El reconocimiento es rápido, automático: coincidencia de patrones, no deliberación.
La clasificación necesita exposición a patrones, no explicaciones elaboradas.
Similitud visual ≠ similitud semántica
La recuperación tradicional busca coincidencias en el significado. Esto funciona para búsqueda y preguntas y respuestas. Falla para la clasificación de documentos.
¿Recuerdas el extracto bancario y el resumen de cuenta de antes? Ambos contienen números de cuenta, fechas, saldos. Ambos vienen del mismo banco. Semánticamente, se superponen fuertemente. Pero visualmente, son distintos: tablas de transacciones frente a resúmenes agregados, saldos acumulados frente a totales agrupados.
Para los documentos, el diseño es la señal más fiable. La estructura se mantiene estable entre instancias del mismo tipo. El contenido del texto varía. Describir clases en prompts es como explicar cómo se ve una cara en lugar de mostrar una fotografía.
HoloRecall: memoria para tu clasificador
HoloRecall da a los clasificadores contexto adicional: junto con descripciones de lo que significa cada clase, ejemplos de cómo se ve cada clase.
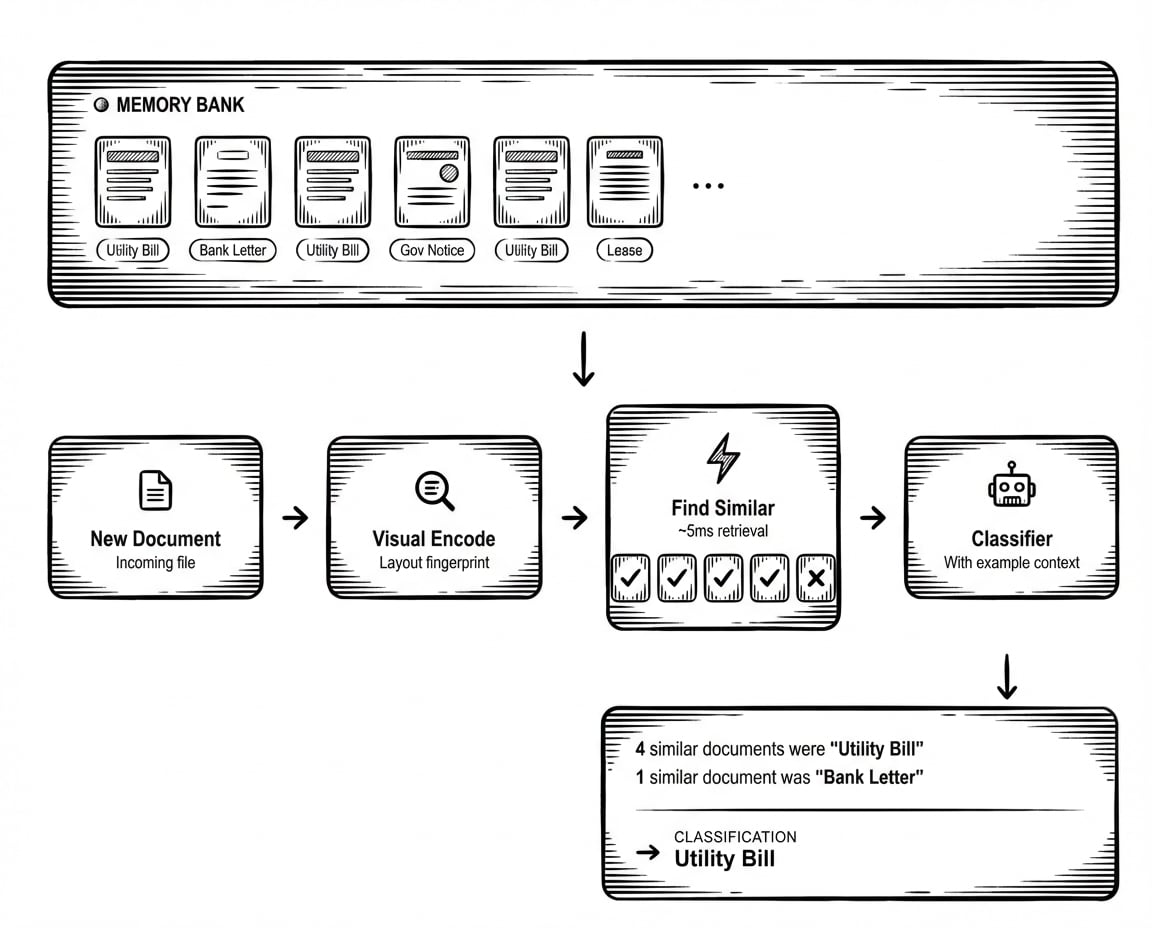
La idea es simple. Cada vez que validas una clasificación (confirmando que el modelo acertó, o corrigiendo cuando se equivocó), ese documento se convierte en un ejemplo de referencia. Cuando llega un nuevo documento, HoloRecall encuentra los ejemplos visualmente más similares de este banco de memoria y los inyecta en el contexto del clasificador.
En lugar de que el prompt diga "una factura es un documento comercial que solicita el pago de bienes o servicios", el contexto ahora incluye: "Aquí hay cinco documentos con diseños similares. Cuatro fueron clasificados como Invoice. Uno fue clasificado como Receipt". El modelo ve ejemplos reales, no definiciones abstractas.
Cómo funciona el ciclo de aprendizaje:
Cuando un usuario valida o corrige una clasificación, el documento se codifica en una representación visual, una huella digital que captura su diseño estructural, no solo su contenido de texto. Esta huella digital va a un banco de memoria específico para ese clasificador. No requiere reentrenamiento. Sin cambios en el prompt. El sistema simplemente recuerda lo que ha visto.
Cómo funciona la recuperación:
Cuando llega un nuevo documento, obtiene la misma codificación visual. HoloRecall busca en el banco de memoria documentos con huellas estructurales similares. Esto sucede en milisegundos, lo suficientemente rápido como para no impactar significativamente la latencia de clasificación. Los ejemplos más similares, junto con sus etiquetas validadas, se recuperan y se añaden al contexto del clasificador.
Por qué esto escala:
Añadir una nueva clase todavía se beneficia de una buena definición en el prompt, pero ahora puedes complementarla con ejemplos. A medida que tu banco de memoria crece, tu clasificador ve más patrones, maneja más casos límite, reconoce más variaciones. El sistema se vuelve más inteligente pasivamente, a través del uso normal, sin cambios de código.
Esta es la ventaja compuesta: cada documento que procesas y validas hace que la siguiente clasificación esté ligeramente más informada. Tu clasificador desarrolla memoria institucional.
Dónde cambia esto las cosas
HoloRecall no es un reemplazo para los buenos prompts. Una taxonomía de clasificación bien definida con categorías claras y distintas siempre será la base. Pero hay situaciones específicas donde la memoria proporciona una ventaja que los prompts no pueden.
Casos límite que se resisten a la descripción. Algunos tipos de documentos son genuinamente difíciles de definir con palabras. La diferencia entre una "factura proforma" y una "factura comercial" puede tener señales de diseño sutiles que reconoces cuando las ves pero te cuesta articular. En lugar de escribir definiciones cada vez más enrevesadas, muestras ejemplos y dejas que la similitud visual haga el trabajo.
Taxonomías de alta cardinalidad. Cuando tienes docenas o cientos de clases, la memoria proporciona una alternativa escalable a la saturación del prompt. No necesitas meter 200 definiciones de clases en el contexto. Recuperas los ejemplos relevantes basados en la similitud visual, proporcionando contexto dirigido en lugar de documentación exhaustiva.
Diseños específicos de proveedores. Muchos problemas de clasificación tienen una larga cola de formatos específicos de proveedores. Los extractos del Banco A se ven diferentes a los del Banco B. Los conocimientos de embarque del Transportista X tienen estructuras diferentes a los del Transportista Y. La memoria aprende estos patrones específicos de proveedores automáticamente a medida que procesas documentos de cada fuente.
Empezando
HoloRecall está disponible hoy para clasificadores en Holofin.
Para habilitarlo:
Navega a la página de configuración de tu clasificador. En la navegación de pestañas, localiza HoloRecall. Actívalo para comenzar a construir un banco de memoria a partir de tus clasificaciones validadas previamente. También puedes añadir manualmente ejemplos representativos para cada clase directamente en la configuración. Una vez habilitado, HoloRecall comienza inmediatamente a aprender de tu conjunto de datos.
Construyendo un buen banco de memoria:
La calidad de la memoria depende de la calidad de los ejemplos. Comienza sincronizando ejemplos de tus conjuntos de evaluación, estos ya están validados y son representativos. A medida que procesas documentos y corriges errores, esas correcciones se convierten en nuevos ejemplos. Con el tiempo, el banco de memoria acumula cobertura de tu panorama documental.
Cuándo usarlo:
Como demostramos, HoloRecall ayuda más cuando tienes variación visual dentro de las clases, cuando tu taxonomía es grande, o cuando estás alcanzando mesetas de precisión que el refinamiento del prompt no puede resolver. Si tu clasificación ya está funcionando bien con una taxonomía pequeña y bien definida, la función HoloRecall añade menos valor. Empieza con tus casos problemáticos.
Cierre
Pasamos mucho tiempo creyendo que una mejor clasificación requería mejores instrucciones. Definiciones más precisas. Más manejo de casos límite. Una ingeniería de prompts más cuidadosa.
Esa creencia no estaba equivocada, exactamente. Los prompts importan. Pero tienen límites. Límites que se vuelven visibles cuando las taxonomías crecen, cuando los patrones visuales divergen de las descripciones semánticas.
HoloRecall proviene de un enfoque diferente: Dejamos de intentar describir cada caso límite. Empezamos a recordarlos.
Artículos relacionados
Cuando los documentos contraatacan
Página 1: Resumen de cuenta, dos columnas. Página 15: Misma cuenta, tres columnas, nombres de encabezado diferentes. Página 47: Un escaneo con una mancha de café. Página 89: La página de totales, que hace referencia a transacciones que extrajiste hace 70 páginas.

El rastro de auditoría invisible
Un auditor abre tu archivo de exportación, encuentra un saldo de cierre de 47.500 € y saca el PDF de origen. Página 3, esquina inferior derecha: 47.000 €. Un número diferente. "¿De dónde viene la diferencia? ¿Quién lo cambió?"

Tu LLM no es un pipeline de documentos
Hay un momento en todo proyecto de IA donde la demo se ve tan bien que tu cerebro empieza a borrar código silenciosamente. Ves un modelo "leer" un extracto bancario y piensas: esto es. Podemos saltarnos el OCR. Podemos saltarnos el análisis de layout. Quizás podemos saltarnos la mitad del pipeline. En la versión de película, alguien presiona Enter y cae una cascada de JSON desde la nube.