Il y a un moment dans chaque projet de classification où vous voyez le modèle se tromper avec assurance. Pas un cas difficile. Pas un cas limite ambigu. Quelque chose qu'un humain résoudrait en une demi-seconde sans réfléchir.
Vous vérifiez le prompt. La classe est définie. La définition est précise. Le modèle l'a lue, comprise, et a quand même fait le mauvais choix. Vous ajoutez une phrase de clarification. Peut-être une exception. Peut-être une clause « ne pas confondre avec » ou « IMPORTANT ». Ça marche pour ce cas. Puis un nouvel échec arrive, structurellement identique au précédent mais juste assez différent pour que votre correctif le manque.
C'est le tapis roulant du prompt engineering. Nous y sommes passés. Nous avons ajouté des centaines de lignes d'instructions de classification, regardé la précision grimper puis plafonner. Les cas limites continuaient de s'accumuler et les prompts devenaient si longs que le modèle commençait à ignorer des parties importantes.
À un moment donné, nous nous sommes arrêtés et avons posé une question différente : et si décrire les classes n'était pas du tout la bonne approche ?
La réponse est devenue HoloRecall. Un système qui enseigne aux classificateurs par l'exemple plutôt que par l'explication. Au lieu d'écrire des définitions toujours plus longues, nous montrons au modèle à quoi ressemble chaque classe.
C'est ainsi que les humains apprennent réellement les types de documents. Pensez à l'intégration d'un nouvel analyste pour classer des documents bancaires. Vous ne lui donnez pas un manuel définissant « Relevé bancaire » par rapport à « Synthèse de compte » en termes abstraits. Vous l'asseyez avec des exemples : « Ceci est un relevé bancaire. Vois le tableau des transactions, chaque ligne a une date, une description et un montant. Solde courant sur la droite. Ceci est une synthèse de compte, pas de transactions individuelles, juste des soldes groupés par type de compte, peut-être un camembert. Les deux viennent de la même banque. Les deux ont des numéros de compte et des montants en dollars/euros. Mais regarde la structure. Tu apprendras à les reconnaître. »
C'est ce que HoloRecall fait pour votre classificateur.
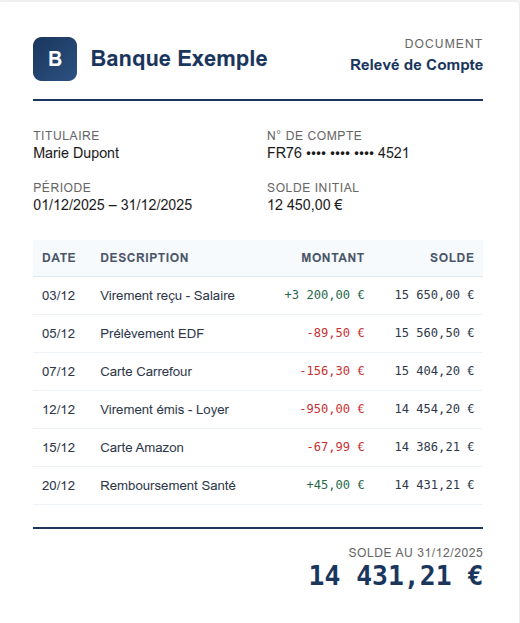

Relevé bancaire : Détail au niveau des transactions, solde courant.
Synthèse de compte : Soldes agrégés, pas de transactions individuelles.
Ce qu'ils partagent : Numéros de compte, dates, soldes — souvent de la même banque. Le chevauchement sémantique est élevé. La similarité visuelle est faible.
Le tapis roulant du prompt engineering
Soyons précis sur ce qui ne va pas.
Vous classez des documents financiers. Vous avez une catégorie appelée « Relevé bancaire » et une autre appelée « Synthèse de compte ». Les deux peuvent contenir des numéros de compte, des soldes, des listes de transactions. Le chevauchement sémantique est réel. Vous écrivez donc des définitions minutieuses : les relevés bancaires montrent le détail des transactions avec dates et montants ; les synthèses de compte agrègent les soldes entre les comptes sans transactions individuelles.
Ça marche. La plupart du temps.
Puis une banque envoie un « Relevé de compte » formaté comme une synthèse mais contenant des transactions. Puis une autre banque envoie une « Synthèse mensuelle » qui est en fait un relevé complet. Puis une troisième banque envoie quelque chose de véritablement ambigu, même pour des humains — et votre classificateur choisit avec assurance, et se trompe.
Chaque échec vous apprend quelque chose. Vous encodez cette leçon dans le prompt. Le prompt grandit. Vous ajoutez des exemples dans les instructions : « Un Relevé bancaire ressemble typiquement à X. Une Synthèse de compte ressemble typiquement à Y. » Mais « typiquement » fait beaucoup de travail, et les exceptions continuent d'apparaître.
Le problème fondamental n'est pas que le modèle est stupide. C'est que le langage est un encodage inefficace pour les motifs visuels. Vous essayez de décrire, avec des mots, des différences que les humains perçoivent instantanément par la mise en page, la structure et l'arrangement spatial.
Les prompts capturent bien la sémantique. Ils capturent mal la structure visuelle.
Le problème des classes multiples
Cela empire à mesure que les taxonomies grandissent.
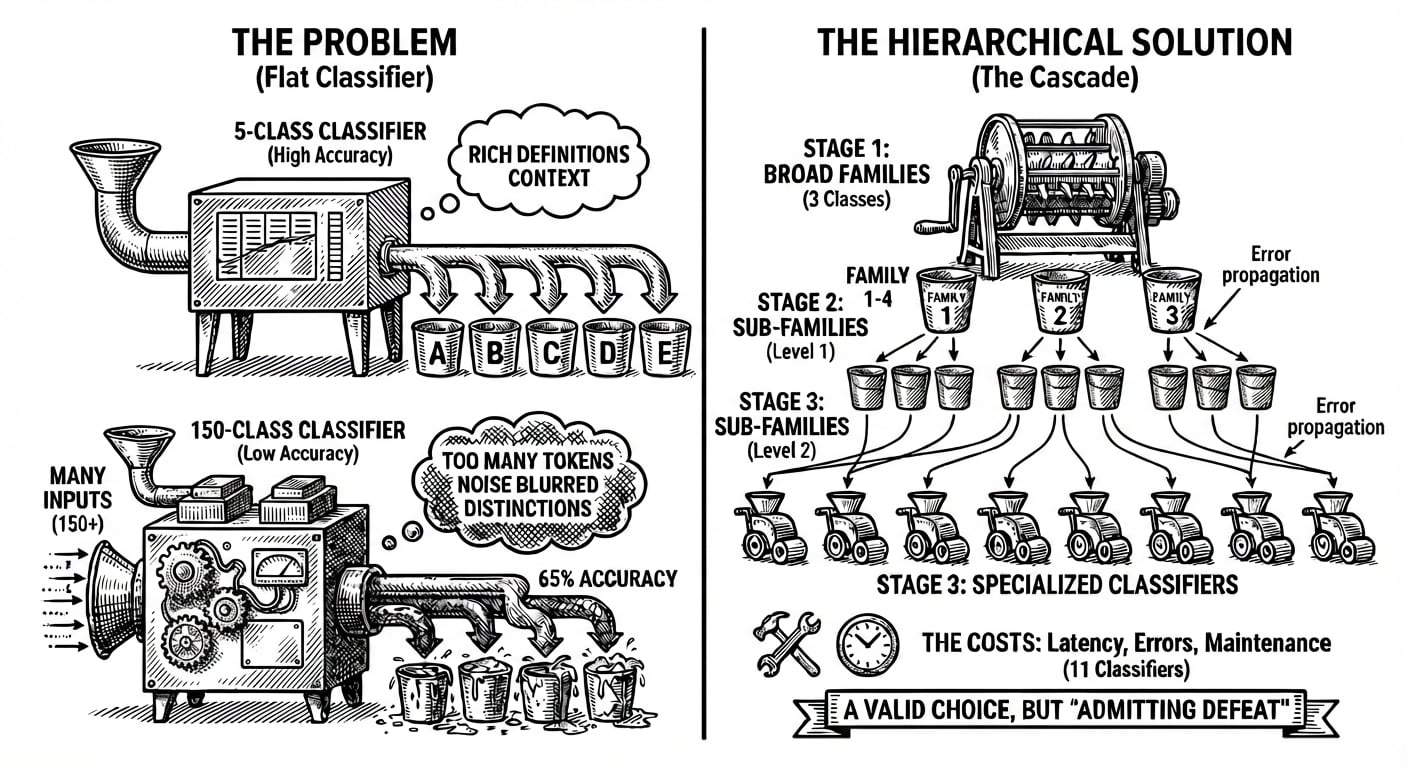
Un classificateur avec six catégories peut inclure des définitions riches pour chacune. Le modèle a beaucoup de contexte pour comprendre ce qui rend chaque classe distincte. Mais que se passe-t-il quand vous avez 50 catégories ? Ou 150 ? Ou 300 ?
Chaque définition consomme des tokens. Chaque token est en compétition pour l'attention du modèle. À un certain point, vous n'ajoutez pas de clarté, vous ajoutez du bruit. Le modèle doit garder tant de descriptions de classes en contexte que les distinctions entre elles deviennent floues.
C'est un fait qui a été prouvé. Lorsque des chercheurs ont testé la précision de classification sur des jeux de données de complexité variable, un schéma clair a émergé : les modèles atteignaient plus de 94 % de précision sur une tâche de sentiment à six classes mais chutaient à environ 65 % sur une tâche de catégorisation d'applications à 119 classes. Même modèle sous-jacent. Même approche d'entraînement. La différence était la taille de la taxonomie.
La solution évidente est la hiérarchie. Au lieu d'un classificateur choisissant parmi 150 classes, vous construisez une cascade : d'abord classer en 10 grandes familles, puis router vers un classificateur spécialisé pour chaque famille. Cela fonctionne. Nous avons construit ces systèmes et vu des gains de précision significatifs en pratique. En fait, Holofin introduit cette approche dans le cadre de notre fonctionnalité Workflows à venir (surveillez l'article dédié bientôt).
Mais ils ont un coût. Chaque étape introduit de la latence. Chaque étape peut propager des erreurs. Si le premier classificateur assigne un document à la mauvaise famille, aucune précision dans la seconde étape ne le sauvera. Et la maintenance devient un casse-tête : vous réglez maintenant 11 classificateurs au lieu d'un, chacun avec son propre prompt, ses propres cas limites, ses propres modes d'échec.
La classification hiérarchique est un choix d'ingénierie valide. C'est aussi, en un sens, admettre la défaite face au problème du prompt engineering.
Nous voulions quelque chose de différent. Quelque chose qui passe à l'échelle sans multiplier les prompts.
Pourquoi le raisonnement n'aide pas ici
Dans des tâches comme les mathématiques et la génération de code, le raisonnement par chaîne de pensée (chain-of-thought) aide. La classification ne fonctionne pas ainsi. Des recherches récentes — et nos propres résultats — ont montré que l'ajout d'étapes de raisonnement ne faisait aucune différence ou nuisait activement à la performance. Quand les modèles « réfléchissent » avant de classer, la précision chute. Quand ils sortent la classe d'abord et expliquent après, la précision augmente.
C'est logique quand on considère comment les humains classent les documents. Vous ne raisonnez pas pour reconnaître une facture. Vous y jetez un coup d'œil et vous savez. La reconnaissance est rapide, automatique — c'est de la correspondance de motifs, pas de la délibération.
La classification a besoin d'exposition aux motifs, pas d'explications élaborées.
Similarité visuelle ≠ similarité sémantique
La recherche traditionnelle (retrieval) se base sur le sens. Cela fonctionne pour la recherche et les questions-réponses. Cela échoue pour la classification de documents.
Rappelez-vous le relevé bancaire et la synthèse de compte de tout à l'heure ? Les deux contiennent des numéros de compte, des dates, des soldes. Les deux viennent de la même banque. Sémantiquement, ils se chevauchent fortement. Mais visuellement, ils sont distincts : tableaux de transactions contre synthèses agrégées, soldes courants contre totaux groupés.
Pour les documents, la mise en page est le signal le plus fiable. La structure reste stable entre les instances du même type. Le contenu textuel varie. Décrire des classes dans des prompts revient à expliquer à quoi ressemble un visage au lieu de montrer une photographie.
HoloRecall : une mémoire pour votre classificateur
HoloRecall donne aux classificateurs un contexte supplémentaire : aux côtés des descriptions de ce que chaque classe signifie, des exemples de ce à quoi chaque classe ressemble.
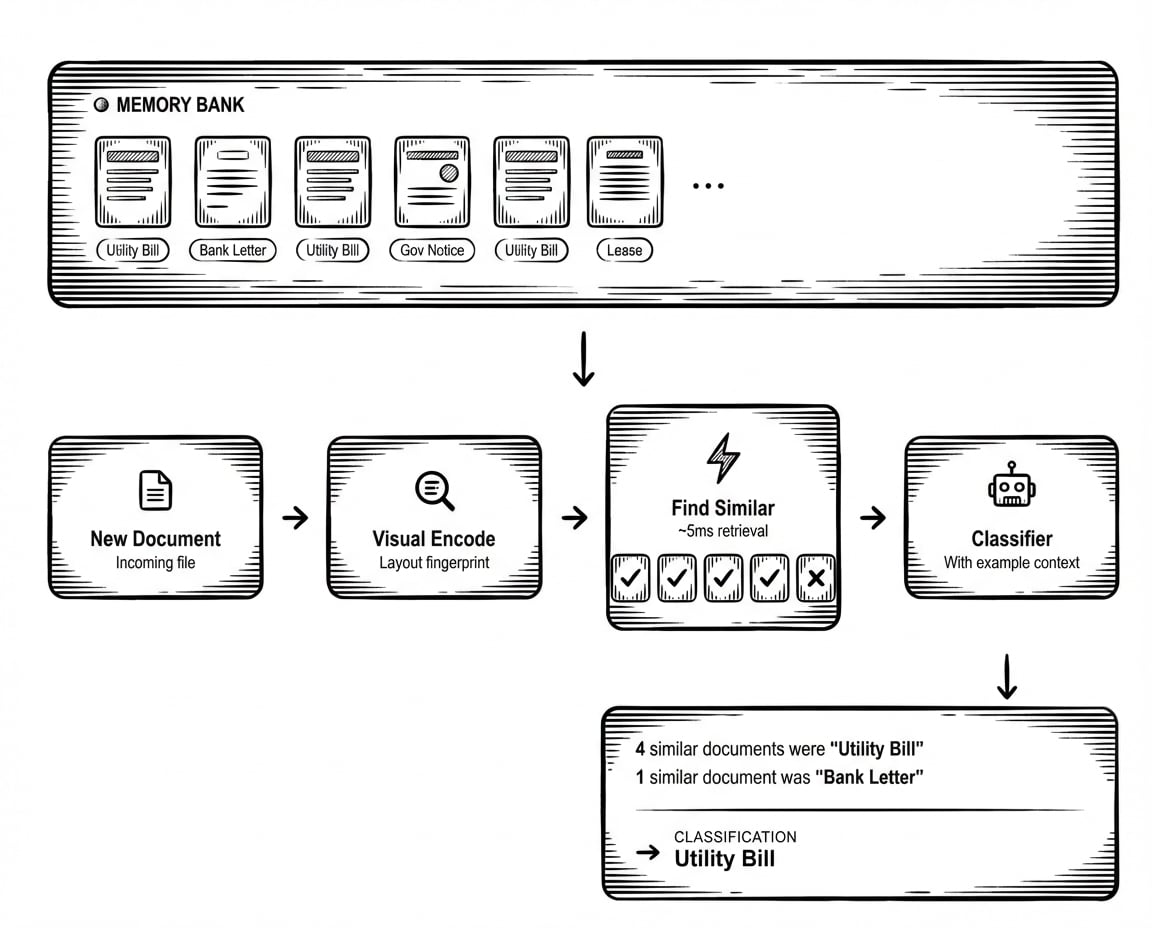
L'idée est simple. Chaque fois que vous validez une classification (en confirmant que le modèle a vu juste, ou en corrigeant quand il s'est trompé), ce document devient un exemple de référence. Quand un nouveau document arrive, HoloRecall trouve les exemples les plus visuellement similaires dans cette banque de mémoire et les injecte dans le contexte du classificateur.
Au lieu que le prompt dise « une facture est un document commercial demandant le paiement de biens ou services », le contexte inclut désormais : « Voici cinq documents avec des mises en page similaires. Quatre ont été classés comme Facture. Un a été classé comme Reçu. » Le modèle voit des exemples réels, pas des définitions abstraites.
Comment fonctionne la boucle d'apprentissage :
Quand un utilisateur valide ou corrige une classification, le document est encodé en une représentation visuelle, une empreinte qui capture sa mise en page structurelle, pas seulement son contenu textuel. Cette empreinte va dans une banque de mémoire spécifique à ce classificateur. Pas de réentraînement nécessaire. Pas de changement de prompt. Le système se souvient simplement de ce qu'il a vu.
Comment fonctionne la récupération :
Quand un nouveau document arrive, il reçoit le même encodage visuel. HoloRecall cherche dans la banque de mémoire des documents avec des empreintes structurelles similaires. Cela se produit en quelques millisecondes, assez rapidement pour ne pas impacter significativement la latence de classification. Les exemples les plus similaires, avec leurs étiquettes validées, sont récupérés et ajoutés au contexte du classificateur.
Pourquoi cela passe à l'échelle :
Ajouter une nouvelle classe bénéficie toujours d'une bonne définition de prompt, mais maintenant vous pouvez la compléter avec des exemples. À mesure que votre banque de mémoire grandit, votre classificateur voit plus de motifs, gère plus de cas limites, reconnaît plus de variations. Le système devient plus intelligent passivement, par l'usage normal, sans changement de code.
C'est l'avantage cumulatif : chaque document que vous traitez et validez rend la prochaine classification légèrement plus informée. Votre classificateur développe une mémoire institutionnelle.
Là où cela change la donne
HoloRecall ne remplace pas les bons prompts. Une taxonomie de classification bien définie avec des catégories claires et distinctes sera toujours la fondation. Mais il y a des situations spécifiques où la mémoire fournit un levier que les prompts ne peuvent pas offrir.
Les cas limites qui résistent à la description. Certains types de documents sont véritablement difficiles à définir avec des mots. La différence entre une « facture proforma » et une « facture commerciale » peut avoir des indices de mise en page subtils que vous reconnaissez quand vous les voyez mais peinez à articuler. Au lieu d'écrire des définitions toujours plus alambiquées, vous montrez des exemples et laissez la similarité visuelle faire le travail.
Les taxonomies à haute cardinalité. Quand vous avez des dizaines ou des centaines de classes, la mémoire fournit une alternative évolutive au gonflement du prompt. Vous n'avez pas besoin de faire tenir 200 définitions de classes dans le contexte. Vous récupérez les exemples pertinents basés sur la similarité visuelle, fournissant un contexte ciblé plutôt qu'une documentation exhaustive.
Les mises en page spécifiques aux fournisseurs. De nombreux problèmes de classification ont une longue traîne de formats spécifiques aux fournisseurs. Les relevés de la Banque A sont différents de ceux de la Banque B. Les connaissements du Transporteur X ont des structures différentes de ceux du Transporteur Y. La mémoire apprend ces motifs spécifiques aux fournisseurs automatiquement à mesure que vous traitez des documents de chaque source.
Commencer
HoloRecall est disponible dès aujourd'hui pour les classificateurs dans Holofin.
Pour l'activer :
Naviguez vers la page de configuration de votre classificateur. Dans les onglets, localisez HoloRecall. Activez-le pour commencer à construire une banque de mémoire à partir de vos classifications précédemment validées. Vous pouvez aussi ajouter manuellement des exemples représentatifs pour chaque classe directement dans la configuration. Une fois activé, HoloRecall commence immédiatement à apprendre de votre jeu de données.
Construire une bonne banque de mémoire :
La qualité de la mémoire dépend de la qualité des exemples. Commencez par synchroniser des exemples de vos jeux d'évaluation, ceux-ci sont déjà validés et représentatifs. À mesure que vous traitez des documents et corrigez des erreurs, ces corrections deviennent de nouveaux exemples. Avec le temps, la banque de mémoire accumule une couverture de votre paysage documentaire.
Quand l'utiliser :
Comme nous l'avons démontré, HoloRecall aide le plus quand vous avez une variation visuelle au sein des classes, quand votre taxonomie est large, ou quand vous atteignez des plateaux de précision que le raffinement du prompt ne peut résoudre. Si votre classification fonctionne déjà bien avec une petite taxonomie bien définie, la fonctionnalité HoloRecall ajoute moins de valeur. Commencez par vos cas problématiques.
Conclusion
Nous avons longtemps cru qu'une meilleure classification nécessitait de meilleures instructions. Des définitions plus précises. Plus de gestion des cas limites. Un prompt engineering plus minutieux.
Cette croyance n'était pas fausse, exactement. Les prompts comptent. Mais ils ont des limites. Des limites qui deviennent visibles quand les taxonomies grandissent, quand les motifs visuels divergent des descriptions sémantiques.
HoloRecall vient d'une approche différente : Nous avons arrêté d'essayer de décrire chaque cas limite. Nous avons commencé à nous en souvenir.
Articles connexes
Quand les documents contre-attaquent
Page 1 : Résumé du compte, deux colonnes. Page 15 : Même compte, trois colonnes, noms d'en-tête différents. Page 47 : Un scan avec une tache de café. Page 89 : La page des totaux, qui fait référence à des transactions que vous avez extraites il y a 70 pages.

La piste d'audit invisible
Un auditeur ouvre votre fichier d'export, trouve un solde de clôture de 47 500 € et sort le PDF source. Page 3, coin inférieur droit : 47 000 €. Un chiffre différent. « D'où vient la différence ? Qui l'a modifié ? »

Votre LLM n'est pas un pipeline de documents
Il y a un moment dans chaque projet d'IA où la démo semble si parfaite que votre cerveau commence silencieusement à supprimer du code. Vous regardez un modèle « lire » un relevé bancaire et vous vous dites : ça y est. On peut sauter l'OCR. On peut sauter l'analyse de la mise en page. Peut-être qu'on peut sauter la moitié du pipeline. Dans la version cinéma, quelqu'un appuie sur Entrée et du JSON coule en cascade depuis le cloud.