C'è un momento in ogni progetto di classificazione in cui osservi il modello sbagliare con sicurezza. Non un caso difficile. Non un caso limite ambiguo. Qualcosa che un umano risolverebbe in mezzo secondo senza pensare.
Controlli il prompt. La classe è definita. La definizione è accurata. Il modello l'ha letta, capita, e ha comunque scelto male. Aggiungi una frase chiarificatrice. Forse un'eccezione. Forse una clausola "non confondere con" o "IMPORTANTE". Funziona per quel caso. Poi arriva un nuovo fallimento, strutturalmente identico all'ultimo ma appena diverso abbastanza da sfuggire alla tua patch.
Questo è il tapis roulant del prompt engineering. Ci siamo passati. Abbiamo aggiunto centinaia di righe di istruzioni di classificazione, guardato l'accuratezza salire e poi stabilizzarsi. I casi limite continuavano ad accumularsi e i prompt diventavano così lunghi che il modello iniziava a ignorare parti importanti.
A un certo punto ci siamo fermati e ci siamo posti una domanda diversa: e se descrivere le classi non fosse affatto l'approccio giusto?
La risposta è diventata HoloRecall. Un sistema che insegna ai classificatori attraverso esempi piuttosto che spiegazioni. Invece di scrivere definizioni sempre più lunghe, mostriamo al modello che aspetto ha ogni classe.
È così che gli umani imparano davvero i tipi di documento. Pensa all'onboarding di un nuovo analista per classificare documenti bancari. Non gli dai un manuale che definisce "Estratto Conto" rispetto a "Riepilogo Conto" in termini astratti. Ti siedi con loro con degli esempi: "Questo è un estratto conto. Vedi la tabella delle transazioni, ogni riga ha una data, una descrizione e un importo. Saldo progressivo sulla destra. Questo è un riepilogo conto, niente transazioni individuali, solo saldi raggruppati per tipo di conto, forse un grafico a torta. Entrambi provengono dalla stessa banca. Entrambi hanno numeri di conto e importi in dollari/euro. Ma guarda la struttura. Imparerai a riconoscerli."
Questo è ciò che HoloRecall fa per il tuo classificatore.
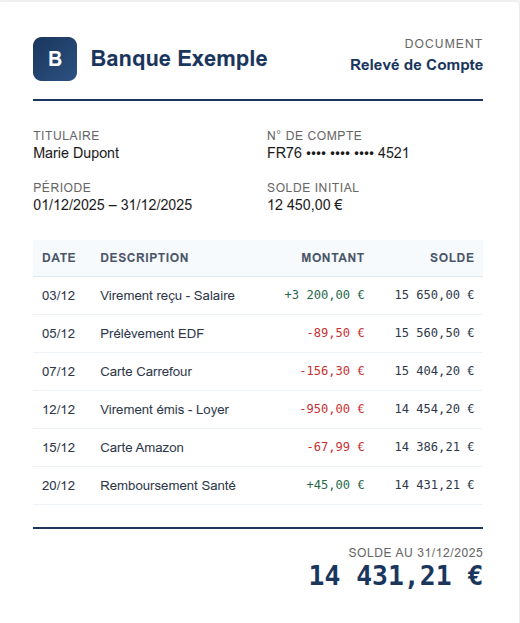

Estratto conto: Dettaglio a livello di transazione, saldo progressivo.
Riepilogo conto: Saldi aggregati, nessuna transazione individuale.
Cosa condividono: Numeri di conto, date, saldi—spesso dalla stessa banca. La sovrapposizione semantica è alta. La somiglianza visiva è bassa.
Il tapis roulant del prompt engineering
Siamo specifici su cosa va storto.
Stai classificando documenti finanziari. Hai una categoria chiamata "Estratto Conto" e un'altra chiamata "Riepilogo Conto". Entrambe possono contenere numeri di conto, saldi, liste di transazioni. La sovrapposizione semantica è reale. Quindi scrivi definizioni attente: gli estratti conto mostrano dettagli a livello di transazione con date e importi; i riepiloghi conto aggregano i saldi tra i conti senza transazioni individuali.
Funziona. Per lo più.
Poi una banca invia un "Rendiconto" formattato come un riepilogo ma contenente transazioni. Poi un'altra banca invia un "Riepilogo Mensile" che è in realtà un estratto conto completo. Poi una terza banca invia qualcosa che è genuinamente ambiguo anche per gli umani—e il tuo classificatore sceglie con sicurezza e sbaglia.
Ogni fallimento ti insegna qualcosa. Codifichi quella lezione nel prompt. Il prompt cresce. Aggiungi esempi nelle istruzioni: "Un Estratto Conto tipicamente appare come X. Un Riepilogo Conto tipicamente appare come Y". Ma "tipicamente" sta facendo molto lavoro, e le eccezioni continuano ad apparire.
Il problema fondamentale non è che il modello sia stupido. È che il linguaggio è una codifica inefficiente per i pattern visivi. Stai cercando di descrivere, a parole, differenze che gli umani percepiscono istantaneamente attraverso il layout, la struttura e la disposizione spaziale.
I prompt catturano bene la semantica. Catturano male la struttura visiva.
Il problema delle molte classi
Questo peggiora man mano che le tassonomie crescono.
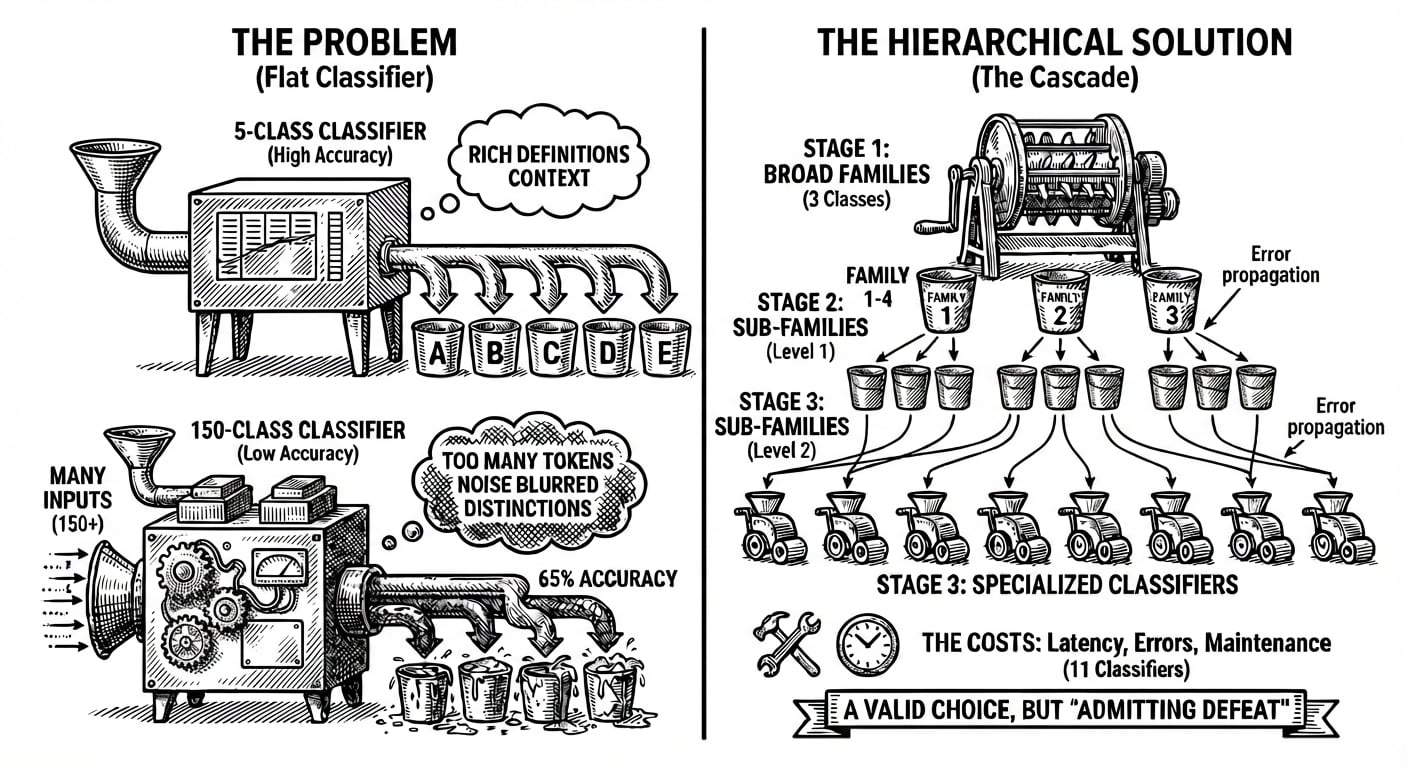
Un classificatore con sei categorie può includere ricche definizioni per ciascuna. Il modello ha molto contesto per capire cosa rende distinta ogni classe. Ma cosa succede quando hai 50 categorie? O 150? O 300?
Ogni definizione consuma token. Ogni token compete per l'attenzione del modello. A un certo punto, non stai aggiungendo chiarezza, stai aggiungendo rumore. Il modello deve tenere così tante descrizioni di classe nel contesto che le distinzioni tra loro si confondono.
Questo è un fatto che è stato provato. Quando i ricercatori hanno testato l'accuratezza della classificazione su dataset di varia complessità, è emerso un modello chiaro: i modelli raggiungevano oltre il 94% di accuratezza su un compito di sentiment a sei classi, ma scendevano a circa il 65% su un compito di categorizzazione app a 119 classi. Stesso modello sottostante. Stesso approccio di training. La differenza era la dimensione della tassonomia.
La soluzione ovvia è la gerarchia. Invece di un classificatore che sceglie tra 150 classi, costruisci una cascata: prima classifichi in 10 ampie famiglie, poi instradi a un classificatore specializzato per ogni famiglia. Questo funziona. Abbiamo costruito questi sistemi e visto guadagni significativi di accuratezza nella pratica. Infatti, Holofin sta introducendo questo approccio come parte della nostra imminente funzionalità Workflows (aspettatevi un articolo dedicato a breve).
Ma comportano dei costi. Ogni stadio introduce latenza. Ogni stadio può propagare errori. Se il primo classificatore assegna un documento alla famiglia sbagliata, nessuna quantità di precisione nel secondo stadio lo salverà. E la manutenzione diventa un mal di testa: ora stai calibrando 11 classificatori invece di uno, ognuno con il proprio prompt, i propri casi limite, le proprie modalità di fallimento.
La classificazione gerarchica è una scelta ingegneristica valida. È anche, in un certo senso, ammettere la sconfitta al problema del prompt engineering.
Volevamo qualcosa di diverso. Qualcosa che scalasse senza moltiplicare i prompt.
Perché il ragionamento qui non aiuta
In compiti come la matematica e la generazione di codice, il ragionamento chain-of-thought aiuta. La classificazione non funziona in questo modo. Ricerche recenti—e i nostri stessi risultati—hanno scoperto che aggiungere passaggi di ragionamento non faceva alcuna differenza o danneggiava attivamente le prestazioni. Quando i modelli "pensano" prima di classificare, l'accuratezza cala. Quando emettono prima la classe e spiegano dopo, l'accuratezza sale.
Questo ha senso se si considera come gli umani classificano i documenti. Non usi il ragionamento per riconoscere una fattura. Le dai un'occhiata e lo sai. Il riconoscimento è veloce, automatico—pattern matching, non deliberazione.
La classificazione ha bisogno di esposizione ai pattern, non di spiegazioni elaborate.
Somiglianza visiva ≠ somiglianza semantica
Il retrieval tradizionale fa match sul significato. Questo funziona per la ricerca e il question-answering. Fallisce per la classificazione dei documenti.
Ricordi l'estratto conto e il riepilogo conto di prima? Entrambi contengono numeri di conto, date, saldi. Entrambi provengono dalla stessa banca. Semanticamente, si sovrappongono pesantemente. Ma visivamente, sono distinti: tabelle di transazioni contro riepiloghi aggregati, saldi progressivi contro totali raggruppati.
Per i documenti, il layout è il segnale più affidabile. La struttura rimane stabile tra le istanze dello stesso tipo. Il contenuto testuale varia. Descrivere le classi nei prompt è come spiegare che aspetto ha un volto invece di mostrare una fotografia.
HoloRecall: memoria per il tuo classificatore
HoloRecall dà ai classificatori un contesto aggiuntivo: accanto alle descrizioni di cosa significa ogni classe, esempi di che aspetto ha ogni classe.
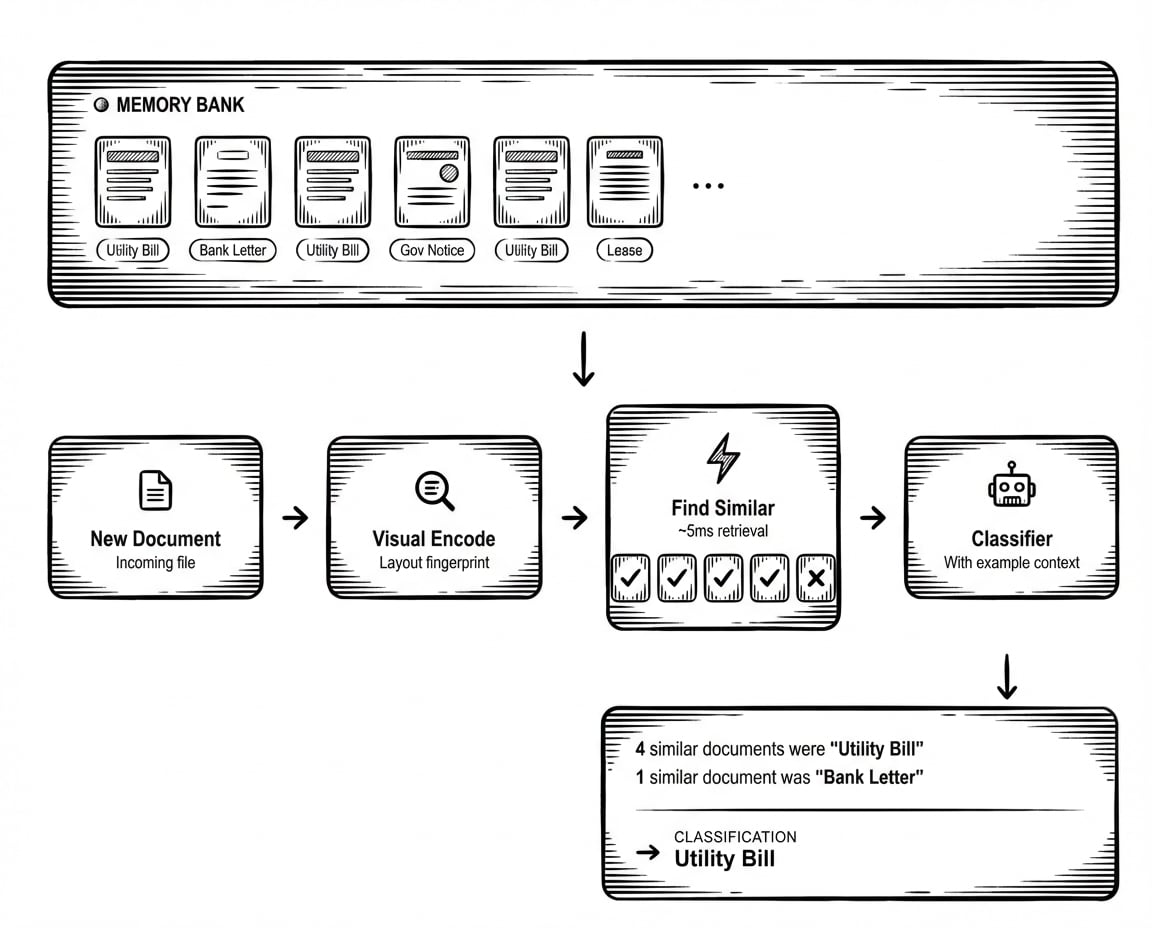
L'idea è semplice. Ogni volta che validi una classificazione (confermando che il modello ha fatto bene, o correggendo quando ha sbagliato) quel documento diventa un esempio di riferimento. Quando arriva un nuovo documento, HoloRecall trova gli esempi visivamente più simili da questa banca di memoria e li inietta nel contesto del classificatore.
Invece del prompt che dice "una fattura è un documento commerciale che richiede il pagamento per beni o servizi", il contesto ora include: "Ecco cinque documenti con layout simili. Quattro sono stati classificati come Fattura. Uno è stato classificato come Ricevuta". Il modello vede esempi reali, non definizioni astratte.
Come funziona il ciclo di apprendimento:
Quando un utente valida o corregge una classificazione, il documento viene codificato in una rappresentazione visiva, un'impronta digitale che cattura il suo layout strutturale, non solo il suo contenuto testuale. Questa impronta finisce in una banca di memoria specifica per quel classificatore. Nessun retraining richiesto. Nessun cambio di prompt. Il sistema ricorda semplicemente ciò che ha visto.
Come funziona il retrieval:
Quando arriva un nuovo documento, ottiene la stessa codifica visiva. HoloRecall cerca nella banca di memoria documenti con impronte strutturali simili. Questo avviene in millisecondi, abbastanza velocemente da non impattare in modo significativo sulla latenza di classificazione. Gli esempi più simili, insieme alle loro etichette validate, vengono recuperati e aggiunti al contesto del classificatore.
Perché questo scala:
Aggiungere una nuova classe beneficia ancora di una buona definizione nel prompt, ma ora puoi integrarla con esempi. Man mano che la tua banca di memoria cresce, il tuo classificatore vede più pattern, gestisce più casi limite, riconosce più variazioni. Il sistema diventa più intelligente passivamente, attraverso il normale utilizzo, senza modifiche al codice.
Questo è il vantaggio composto: ogni documento che processi e validi rende la prossima classificazione leggermente più informata. Il tuo classificatore sviluppa una memoria istituzionale.
Dove questo cambia le cose
HoloRecall non è un sostituto per dei buoni prompt. Una tassonomia di classificazione ben definita con categorie chiare e distinte sarà sempre la fondazione. Ma ci sono situazioni specifiche in cui la memoria fornisce una leva che i prompt non possono dare.
Casi limite che resistono alla descrizione. Alcuni tipi di documenti sono genuinamente difficili da definire a parole. La differenza tra una "fattura proforma" e una "fattura commerciale" potrebbe avere sottili indizi di layout che riconosci quando li vedi ma fatichi ad articolare. Invece di scrivere definizioni sempre più contorte, mostri esempi e lasci che la somiglianza visiva faccia il lavoro.
Tassonomie ad alta cardinalità. Quando hai dozzine o centinaia di classi, la memoria fornisce un'alternativa scalabile al gonfiore dei prompt. Non hai bisogno di inserire 200 definizioni di classe nel contesto. Recuperi gli esempi rilevanti basati sulla somiglianza visiva, fornendo un contesto mirato piuttosto che una documentazione esaustiva.
Layout specifici del fornitore. Molti problemi di classificazione hanno una lunga coda di formati specifici per fornitore. Gli estratti conto della Banca A appaiono diversi da quelli della Banca B. Le polizze di carico del Vettore X hanno strutture diverse da quelle del Vettore Y. La memoria impara questi pattern specifici del fornitore automaticamente mentre processi i documenti da ogni fonte.
Per iniziare
HoloRecall è disponibile oggi per i classificatori in Holofin.
Per abilitarlo:
Naviga alla pagina di configurazione del tuo classificatore. Nella navigazione a schede, individua HoloRecall. Attivalo per iniziare a costruire una banca di memoria dalle tue classificazioni precedentemente validate. Puoi anche aggiungere manualmente esempi rappresentativi per ogni classe direttamente nella configurazione. Una volta abilitato, HoloRecall inizia immediatamente a imparare dal tuo dataset.
Costruire una buona banca di memoria:
La qualità della memoria dipende dalla qualità degli esempi. Inizia sincronizzando gli esempi dai tuoi set di valutazione, questi sono già validati e rappresentativi. Mentre processi i documenti e correggi gli errori, quelle correzioni diventano nuovi esempi. Nel tempo, la banca di memoria accumula copertura del tuo panorama documentale.
Quando usarlo:
Come abbiamo dimostrato, HoloRecall aiuta maggiormente quando hai variazioni visive all'interno delle classi, quando la tua tassonomia è grande, o quando stai colpendo plateau di accuratezza che il raffinamento dei prompt non può risolvere. Se la tua classificazione sta già performando bene con una tassonomia piccola e ben definita, la funzionalità HoloRecall aggiunge meno valore. Inizia con i tuoi casi problematici.
Chiusura
Abbiamo passato molto tempo a credere che una migliore classificazione richiedesse migliori istruzioni. Definizioni più precise. Più gestione dei casi limite. Prompt engineering più attento.
Quella convinzione non era sbagliata, esattamente. I prompt contano. Ma hanno dei limiti. Limiti che diventano visibili quando le tassonomie crescono, quando i pattern visivi divergono dalle descrizioni semantiche.
HoloRecall nasce da un approccio diverso: Abbiamo smesso di cercare di descrivere ogni caso limite. Abbiamo iniziato a ricordarli.
Articoli correlati

Quando i documenti si ribellano
Pagina 1: Riepilogo conto, due colonne. Pagina 15: Stesso conto, tre colonne, nomi delle intestazioni diversi. Pagina 47: Una scansione con una macchia di caffè. Pagina 89: La pagina dei totali, che fa riferimento a transazioni estratte 70 pagine fa.

La traccia di audit invisibile
Un revisore apre il tuo file di esportazione, trova un saldo di chiusura di 47.500 € e recupera il PDF di origine. Pagina 3, angolo in basso a destra: 47.000 €. Numero diverso. "Da dove arriva la differenza? Chi l'ha modificata?"

Il tuo LLM non è una pipeline documentale
C'è un momento in ogni progetto AI in cui la demo sembra così buona che il tuo cervello inizia silenziosamente a cancellare codice. Guardi un modello "leggere" un estratto conto e pensi: ci siamo. Possiamo saltare l'OCR. Possiamo saltare il parsing del layout. Forse possiamo saltare metà della pipeline. Nella versione cinematografica, qualcuno preme Invio e una cascata di JSON scende dal cloud.