Un revisore apre il tuo file di esportazione, trova un saldo di chiusura di 47.500 € e recupera il PDF di origine. Pagina 3, angolo in basso a destra: 47.000 €. Numero diverso. "Da dove arriva la differenza? Chi l'ha modificata?"
Se il tuo sistema di estrazione non riesce a rispondere a questa domanda in meno di un minuto, hai un problema. Non un problema del tipo "dovremmo probabilmente documentarlo meglio". Un problema di conformità. Il tipo di problema in cui qualcuno chiede di vedere la documentazione cartacea e ti rendi conto che non esiste.
I processi manuali hanno risolto questo aspetto. Post-it, iniziali, barrature, firme datate a margine. Quando Maria in contabilità corregge una cifra, lascia una prova. Quando la tua pipeline di estrazione AI corregge una cifra, semplicemente... sovrascrive.
I dati sono corretti. Manca la fiducia.
La realtà della compliance
I settori regolamentati non hanno solo bisogno di numeri corretti. Hanno bisogno di provenienza. Non "siamo abbastanza sicuri che sia giusto", ma "ecco il pixel esatto a pagina 83, ecco chi l'ha validato, ecco il timestamp".
Servizi finanziari, assicurazioni, studi contabili: vivono tutti nel territorio dell'audit. La domanda non è solo "qual è il valore?". È "come siamo arrivati a questo valore?". E quella seconda domanda deve sopravvivere a un esaminatore scettico che presume tu abbia commesso un errore fino a prova contraria.
L'ironia è che l'automazione avrebbe dovuto ridurre il rischio. Meno tocchi umani, meno errori di trascrizione, più coerenza. Tutto vero. Ma l'automazione ha anche creato una nuova categoria di modifiche invisibili. Il motore OCR interpreta silenziosamente un "7" sbavato come un "1". Il livello di normalizzazione inverte un saldo negativo in positivo perché è così che la banca rappresenta gli addebiti. Il modello di estrazione sceglie uno dei due totali possibili perché la pagina aveva intestazioni duplicate.
Ognuna di queste è una decisione. Ognuna di queste cambia l'output. E a meno che tu non le stia tracciando, la tua traccia di audit ha dei buchi che non puoi vedere.
Che aspetto hanno davvero le mutazioni
Prima di guardare le mutazioni in sé, vale la pena chiedersi: come finiscono gli umani a modificare i dati estratti in primo luogo?
In Holofin, tutto inizia con la validazione. Dopo l'estrazione, le regole aziendali vengono eseguite automaticamente sui dati. Per gli estratti conto bancari, ciò significa equazioni di bilancio: il saldo iniziale più gli accrediti meno gli addebiti è uguale al saldo finale? Se i numeri non si riconciliano entro 0,02 €, il sistema lo segnala prima che chiunque esporti qualcosa.
Quella segnalazione è ciò che attira l'attenzione umana. Aprono il documento fianco a fianco con il PDF di origine e trovano il problema: una transazione mancante, una cifra letta male, un duplicato che ha gonfiato il totale. Senza validazione, l'errore viaggia silenziosamente nei sistemi a valle. Con essa, la revisione è mirata: non stai chiedendo a qualcuno di ricontrollare 200 transazioni, gli stai indicando "pagina 12, gli accrediti non tornano, ecco dove guardare".
L'umano apporta una correzione. Quella correzione è una mutazione. E ogni mutazione viene registrata con piena attribuzione, perché questa è la traccia di audit:
Un utente aggiunge una transazione mancante.
L'OCR ha perso una voce sbiadita: forse la stampante stava finendo il toner, forse la scansione era angolata male. L'utente vede il vuoto nel riepilogo di validazione, apre il PDF di origine, trova la riga e aggiunge la transazione manualmente. Cosa viene registrato?
Chi l'ha aggiunta, quando, quali valori ha inserito e, aspetto critico, da quale pagina e coordinate proviene la transazione. L'utente sta asserendo "questi dati esistono nel documento di origine in questa posizione". Quell'asserzione deve essere verificabile.
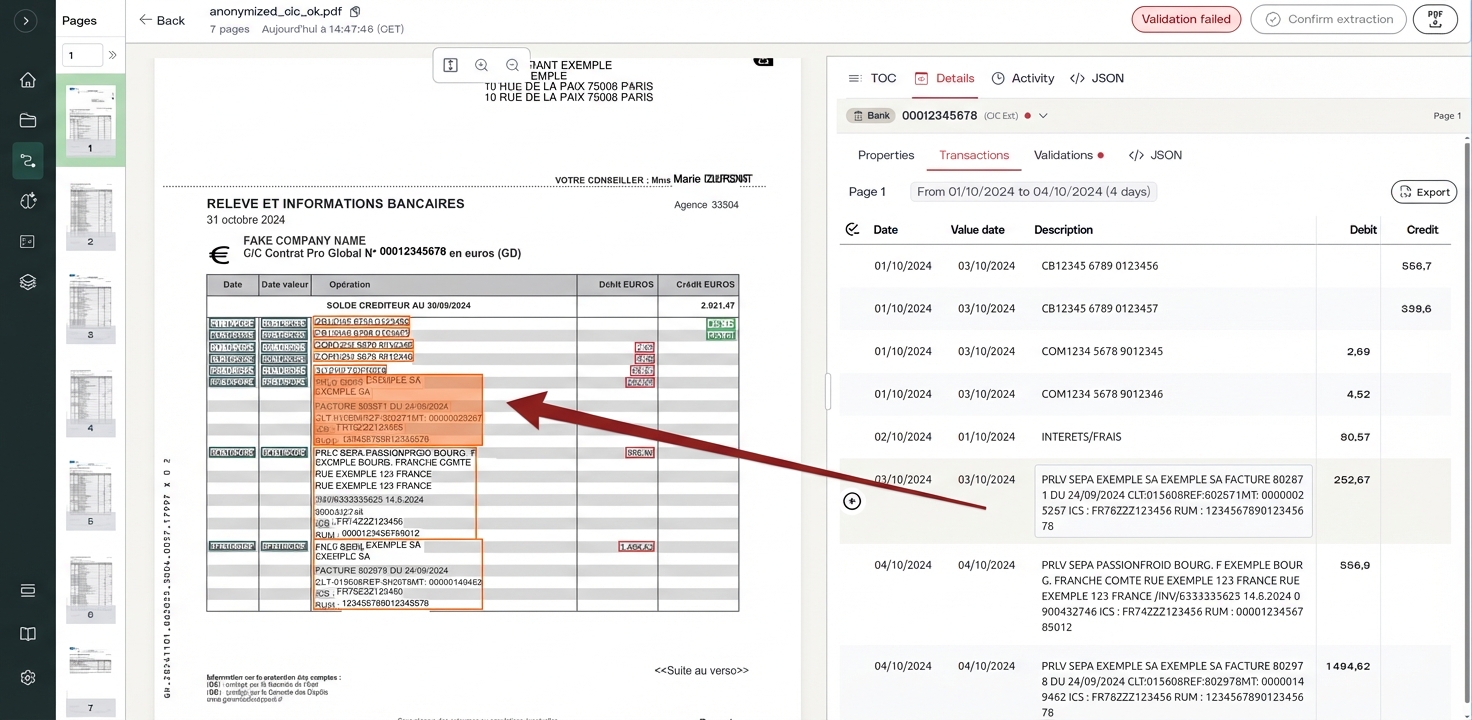
Un utente corregge un errore OCR.
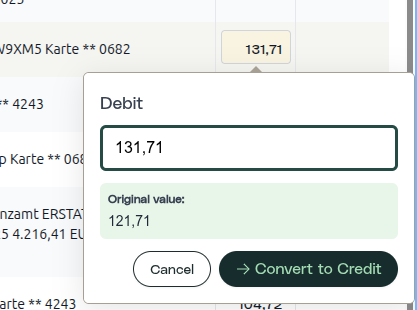
1.238,45 € è stato estratto come 1.236,45 €. Su una scansione di bassa qualità, l'OCR ha letto un 8 come un 6. La validazione ha segnalato una discrepanza di saldo di 2 €. L'utente apre il PDF di origine, individua la cifra sbavata, la corregge. Cosa viene registrato?
Valore originale. Nuovo valore. Utente. Timestamp. E il bounding box del testo di origine, in modo che un revisore possa verificare visivamente la correzione rispetto al documento originale.
Ogni numero ha un indirizzo
La maggior parte dei sistemi di estrazione ti fornisce un valore. Un buon sistema di estrazione ti fornisce un valore e la sua posizione esatta sul documento di origine.
In Holofin, ogni campo estratto porta con sé un bounding box: un insieme di coordinate che segnano il rettangolo preciso sulla pagina dove i dati sono stati letti. Non "pagina 3", ma "pagina 3, 72% dal bordo sinistro, 45% dall'alto, questo esatto gruppo di pixel".
Questo non è un dettaglio diagnostico carino. È la fondazione dell'intera traccia di audit.
Quando un revisore mette in dubbio un numero, non dici semplicemente "veniva dal PDF". Glielo mostri. Il documento di origine si apre con l'area rilevante evidenziata. Il valore estratto si trova accanto all'originale. Il revisore può vedere, con i propri occhi, che il sistema ha letto la cosa giusta o capire esattamente perché un umano l'ha corretta.

Questo collegamento spaziale cattura anche una categoria di fallimenti silenziosi che l'estrazione basata solo sul testo perde completamente. Valori mappati alla colonna sbagliata perché la tabella non aveva griglie. Un totale estratto da una riga di subtotale perché il layout è cambiato a metà pagina. Un'intestazione che copre due colonne, facendo slittare ogni valore sottostante di una cella a destra. Senza coordinate, questi errori producono output dall'aspetto plausibile che superano ogni controllo basato sul testo. Con le coordinate, puoi verificare che il numero etichettato come "saldo di chiusura" provenga effettivamente dalla posizione del saldo di chiusura sulla pagina.
Il bounding box trasforma "fidati di me" in "guarda tu stesso".
Questo collegamento spaziale persiste attraverso ogni cambiamento. Correzioni, cancellazioni, ripristini: ogni mutazione mantiene le sue coordinate di origine. Nulla viene distrutto. Tutto risale ai pixel da cui è venuto.
Quando chiama il revisore
Torniamo a quel revisore con il saldo non corrispondente.
Con una corretta traccia delle mutazioni, la risposta è immediata:
"L'IA ha estratto 47.000 € da pagina 3. Il 15 gennaio alle 14:32, Marie Dubois lo ha corretto a 47.500 €: la pagina 47 contiene una voce di rettifica manuale che l'estrazione iniziale ha perso a causa di una formattazione non standard. Ecco il documento di origine con entrambe le posizioni evidenziate e il record della correzione con timestamp."
Confrontalo con: "Fammi controllare con il team e ti faccio sapere."
La prima risposta costruisce fiducia. La seconda innesca un'indagine più approfondita.
Due visioni della stessa verità
L'intera traccia emerge in due posti: la UI e l'API.
Nella UI di Holofin, ogni estrazione ha un registro delle attività. Gli utenti vedono ogni correzione mentre è avvenuta: chi ha cambiato cosa, quando e da quale valore a quale. È la storia del documento, raccontata cronologicamente. Quando un membro del team apre un'estrazione su cui ha lavorato qualcun altro, può ricostruire ogni decisione senza fare una singola domanda.
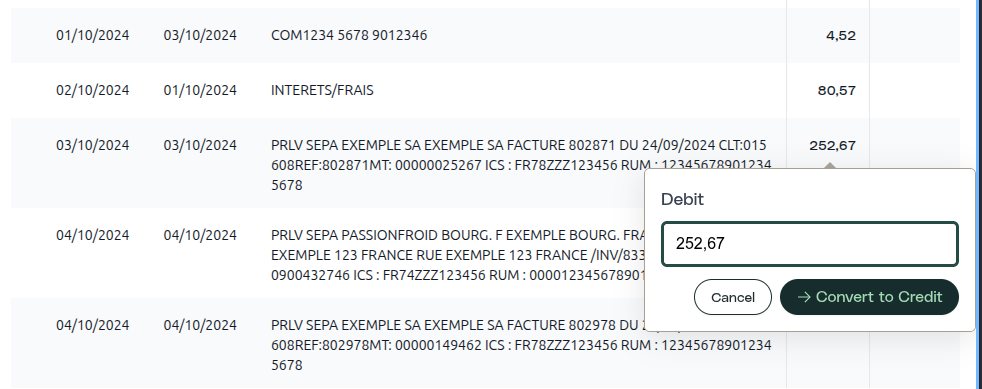
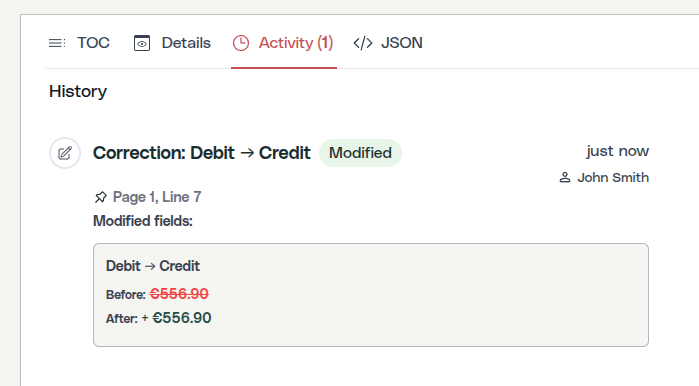
Nell'esportazione API, gli stessi dati arrivano strutturati. Ogni esportazione di documento include la sua cronologia delle mutazioni insieme ai dati estratti: tipo di mutazione, utente, timestamp, valori prima/dopo, coordinate di origine. I tuoi sistemi a valle non ricevono solo numeri; ricevono numeri con provenienza. Una piattaforma contabile che consuma l'API può mostrare ai propri revisori esattamente dove ha avuto origine ogni cifra e chi l'ha validata.
Questo è importante perché i revisori non lavorano tutti nello stesso strumento. Alcuni controlleranno la traccia direttamente in Holofin. Altri la vorranno nel proprio sistema. I dati devono essere portabili.
Siamo stati in abbastanza conversazioni di audit per sapere che: la domanda non è mai "i dati sono corretti?". La domanda è sempre "puoi dimostrarlo?".
Il costo di non avere tutto questo
Costruire tracce di audit richiede sforzo ingegneristico. Ogni tipo di mutazione ha bisogno di uno schema. Ogni cambio di stato ha bisogno di un record. Ogni record deve essere interrogabile, esportabile, conservato per il periodo legalmente richiesto.
L'alternativa è peggiore.
Un rilievo di audit che non riesci a spiegare crea più lavoro di un anno di tracciamento delle mutazioni. Un cliente che perde fiducia nella provenienza dei tuoi dati crea più danni del costo ingegneristico per fare le cose per bene.
Il miglior sistema di estrazione è quello che sa spiegarsi da solo.
I dati sono l'output. La traccia di audit è la fiducia.
Articoli correlati

Quando i documenti si ribellano
Pagina 1: Riepilogo conto, due colonne. Pagina 15: Stesso conto, tre colonne, nomi delle intestazioni diversi. Pagina 47: Una scansione con una macchia di caffè. Pagina 89: La pagina dei totali, che fa riferimento a transazioni estratte 70 pagine fa.

HoloRecall: Mostrare, non raccontare
C'è un momento in ogni progetto di classificazione in cui osservi il modello sbagliare con sicurezza. Non un caso difficile. Non un caso limite ambiguo. Qualcosa che un umano risolverebbe in mezzo secondo senza pensare.

Il tuo LLM non è una pipeline documentale
C'è un momento in ogni progetto AI in cui la demo sembra così buona che il tuo cervello inizia silenziosamente a cancellare codice. Guardi un modello "leggere" un estratto conto e pensi: ci siamo. Possiamo saltare l'OCR. Possiamo saltare il parsing del layout. Forse possiamo saltare metà della pipeline. Nella versione cinematografica, qualcuno preme Invio e una cascata di JSON scende dal cloud.