Es gibt in jedem Klassifizierungsprojekt diesen Moment, in dem man beobachtet, wie das Modell selbstbewusst etwas falsch macht. Kein schwieriger Fall. Kein mehrdeutiger Grenzfall. Etwas, das ein Mensch in einer halben Sekunde lösen würde, ohne nachzudenken.
Sie überprüfen den Prompt. Die Klasse ist definiert. Die Definition ist genau. Das Modell hat es gelesen, verstanden und sich trotzdem falsch entschieden. Sie fügen einen klärenden Satz hinzu. Vielleicht eine Ausnahme. Vielleicht eine „nicht verwechseln mit“- oder „WICHTIG“-Klausel. Für diesen Fall funktioniert es. Dann taucht ein neuer Fehler auf, strukturell identisch mit dem letzten, aber gerade so anders, dass Ihr Patch ihn verpasst hat.
Das ist die Tretmühle des Prompt Engineering. Wir waren auch schon dort. Wir haben Hunderte Zeilen an Klassifizierungsanweisungen hinzugefügt und zugesehen, wie die Genauigkeit stieg und dann ein Plateau erreichte. Randfälle häuften sich, und die Prompts wurden so lang, dass das Modell begann, wichtige Teile zu ignorieren.
Irgendwann hielten wir inne und stellten eine andere Frage: Was, wenn das Beschreiben von Klassen überhaupt nicht der richtige Ansatz ist?
Die Antwort wurde HoloRecall. Ein System, das Classifier durch Beispiele lehrt, statt durch Erklärungen. Anstatt immer längere Definitionen zu schreiben, zeigen wir dem Modell, wie jede Klasse aussieht.
So lernen Menschen tatsächlich Dokumententypen. Denken Sie an das Onboarding eines neuen Analysten zur Klassifizierung von Bankdokumenten. Sie geben ihm kein Handbuch, das „Kontoauszug“ gegen „Kontoübersicht“ in abstrakten Begriffen definiert. Sie setzen sich mit Beispielen zu ihm: „Das ist ein Kontoauszug. Sieh dir die Transaktionstabelle an, jede Zeile hat ein Datum, eine Beschreibung und einen Betrag. Laufender Saldo auf der rechten Seite. Das ist eine Kontoübersicht, keine einzelnen Transaktionen, nur Salden gruppiert nach Kontotyp, vielleicht ein Tortendiagramm. Beide kommen von derselben Bank. Beide haben Kontonummern und Dollar-/Euro-Beträge. Aber schau dir die Struktur an. Du wirst lernen, sie zu erkennen.“
Genau das tut HoloRecall für Ihren Classifier.
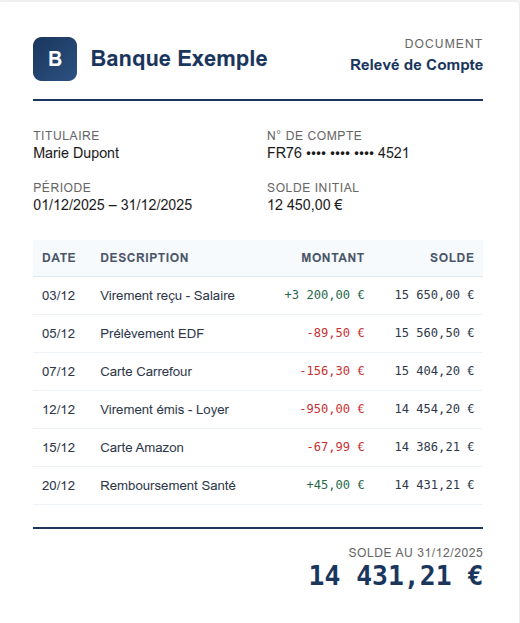

Kontoauszug: Details auf Transaktionsebene, laufender Saldo.
Kontoübersicht: Aggregierte Salden, keine einzelnen Transaktionen.
Was sie gemeinsam haben: Kontonummern, Daten, Salden – oft von derselben Bank. Die semantische Überlappung ist hoch. Die visuelle Ähnlichkeit ist gering.
Die Tretmühle des Prompt Engineering
Lassen Sie uns konkret werden, was schiefläuft.
Sie klassifizieren Finanzdokumente. Sie haben eine Kategorie namens „Kontoauszug“ und eine andere namens „Kontoübersicht“. Beide können Kontonummern, Salden und Transaktionslisten enthalten. Die semantische Überlappung ist real. Also schreiben Sie sorgfältige Definitionen: Kontoauszüge zeigen Details auf Transaktionsebene mit Daten und Beträgen; Kontoübersichten aggregieren Salden über Konten hinweg ohne einzelne Transaktionen.
Es funktioniert. Meistens.
Dann schickt eine Bank einen „Kontoauszug“, der wie eine Zusammenfassung formatiert ist, aber Transaktionen enthält. Dann schickt eine andere Bank eine „Monatliche Zusammenfassung“, die eigentlich ein vollständiger Auszug ist. Dann schickt eine dritte Bank etwas, das selbst für Menschen wirklich mehrdeutig ist – und Ihr Classifier entscheidet sich selbstbewusst und falsch.
Jeder Fehler lehrt Sie etwas. Sie kodieren diese Lektion im Prompt. Der Prompt wächst. Sie fügen Beispiele in den Anweisungen hinzu: „Ein Kontoauszug sieht typischerweise wie X aus. Eine Kontoübersicht sieht typischerweise wie Y aus.“ Aber „typischerweise“ leistet hier Schwerstarbeit, und Ausnahmen tauchen immer wieder auf.
Das grundlegende Problem ist nicht, dass das Modell dumm ist. Es liegt daran, dass Sprache eine ineffiziente Kodierung für visuelle Muster ist. Sie versuchen, in Worten Unterschiede zu beschreiben, die Menschen durch Layout, Struktur und räumliche Anordnung sofort wahrnehmen.
Prompts erfassen Semantik gut. Visuelle Strukturen erfassen sie schlecht.
Das Problem der vielen Klassen
Das wird schlimmer, wenn Taxonomien wachsen.
Ein Classifier mit sechs Kategorien kann reichhaltige Definitionen für jede einzelne enthalten. Das Modell hat genügend Kontext, um zu verstehen, was jede Klasse unterscheidet. Aber was passiert, wenn Sie 50 Kategorien haben? Oder 150? Oder 300?
Jede Definition verbraucht Token. Jedes Token konkurriert um die Aufmerksamkeit des Modells. Irgendwann fügen Sie keine Klarheit mehr hinzu, sondern Rauschen. Das Modell muss so viele Klassenbeschreibungen im Kontext halten, dass die Unterscheidungen zwischen ihnen verschwimmen.
Das ist eine bewiesene Tatsache. Als Forscher die Klassifizierungsgenauigkeit über Datensätze unterschiedlicher Komplexität hinweg testeten, zeigte sich ein klares Muster: Modelle erreichten über 94 % Genauigkeit bei einer Sentiment-Aufgabe mit sechs Klassen, fielen aber auf etwa 65 % bei einer App-Kategorisierungsaufgabe mit 119 Klassen. Dasselbe zugrundeliegende Modell. Derselbe Trainingsansatz. Der Unterschied war die Größe der Taxonomie.
Die offensichtliche Lösung ist Hierarchie. Anstatt dass ein Classifier zwischen 150 Klassen wählt, bauen Sie eine Kaskade: Zuerst in 10 breite Familien klassifizieren, dann an einen spezialisierten Classifier für jede Familie weiterleiten. Das funktioniert. Wir haben diese Systeme gebaut und in der Praxis signifikante Genauigkeitsgewinne gesehen. Tatsächlich führt Holofin diesen Ansatz als Teil unseres kommenden Workflows-Features ein (achten Sie bald auf einen eigenen Artikel).
Aber sie haben ihren Preis. Jede Stufe führt Latenz ein. Jede Stufe kann Fehler weitergeben. Wenn der erste Classifier ein Dokument der falschen Familie zuordnet, kann keine noch so hohe Präzision in der zweiten Stufe es retten. Und die Wartung wird zum Kopfschmerz: Jetzt tunen Sie 11 Classifier statt einem, jeder mit seinem eigenen Prompt, seinen eigenen Randfällen, seinen eigenen Fehlermodi.
Hierarchische Klassifizierung ist eine valide technische Entscheidung. Es ist in gewissem Sinne aber auch ein Eingeständnis der Niederlage gegenüber dem Prompt-Engineering-Problem.
Wir wollten etwas anderes. Etwas, das skaliert, ohne Prompts zu vervielfachen.
Warum Reasoning hier nicht hilft
Bei Aufgaben wie Mathematik und Code-Generierung hilft Chain-of-Thought Reasoning. Klassifizierung funktioniert so nicht. Neuere Forschungen – und unsere eigenen Ergebnisse – haben gezeigt, dass das Hinzufügen von Reasoning-Schritten entweder keinen Unterschied machte oder die Leistung aktiv beeinträchtigte. Wenn Modelle „nachdenken“, bevor sie klassifizieren, sank die Genauigkeit. Wenn sie zuerst die Klasse ausgaben und danach erklärten, stieg die Genauigkeit.
Das ergibt Sinn, wenn man bedenkt, wie Menschen Dokumente klassifizieren. Sie argumentieren sich nicht zur Erkenntnis, dass es sich um eine Rechnung handelt. Sie werfen einen Blick darauf und wissen es. Erkennung ist schnell, automatisch – Musterabgleich, keine Überlegung.
Klassifizierung benötigt Exposition gegenüber Mustern, keine ausführlichen Erklärungen.
Visuelle Ähnlichkeit ≠ semantische Ähnlichkeit
Traditionelles Retrieval gleicht nach Bedeutung ab. Das funktioniert für Suche und Frage-Antwort-Systeme. Bei der Dokumentenklassifizierung versagt es.
Erinnern Sie sich an den Kontoauszug und die Kontoübersicht von vorhin? Beide enthalten Kontonummern, Daten, Salden. Beide kommen von derselben Bank. Semantisch überlappen sie sich stark. Aber visuell sind sie verschieden: Transaktionstabellen versus aggregierte Zusammenfassungen, laufende Salden versus gruppierte Summen.
Bei Dokumenten ist das Layout das zuverlässigere Signal. Die Struktur bleibt über Instanzen desselben Typs hinweg stabil. Der Textinhalt variiert. Klassen in Prompts zu beschreiben ist wie zu erklären, wie ein Gesicht aussieht, anstatt ein Foto zu zeigen.
HoloRecall: Ein Gedächtnis für Ihren Classifier
HoloRecall gibt Classifiern zusätzlichen Kontext: neben Beschreibungen dessen, was jede Klasse bedeutet, Beispiele dafür, wie jede Klasse aussieht.
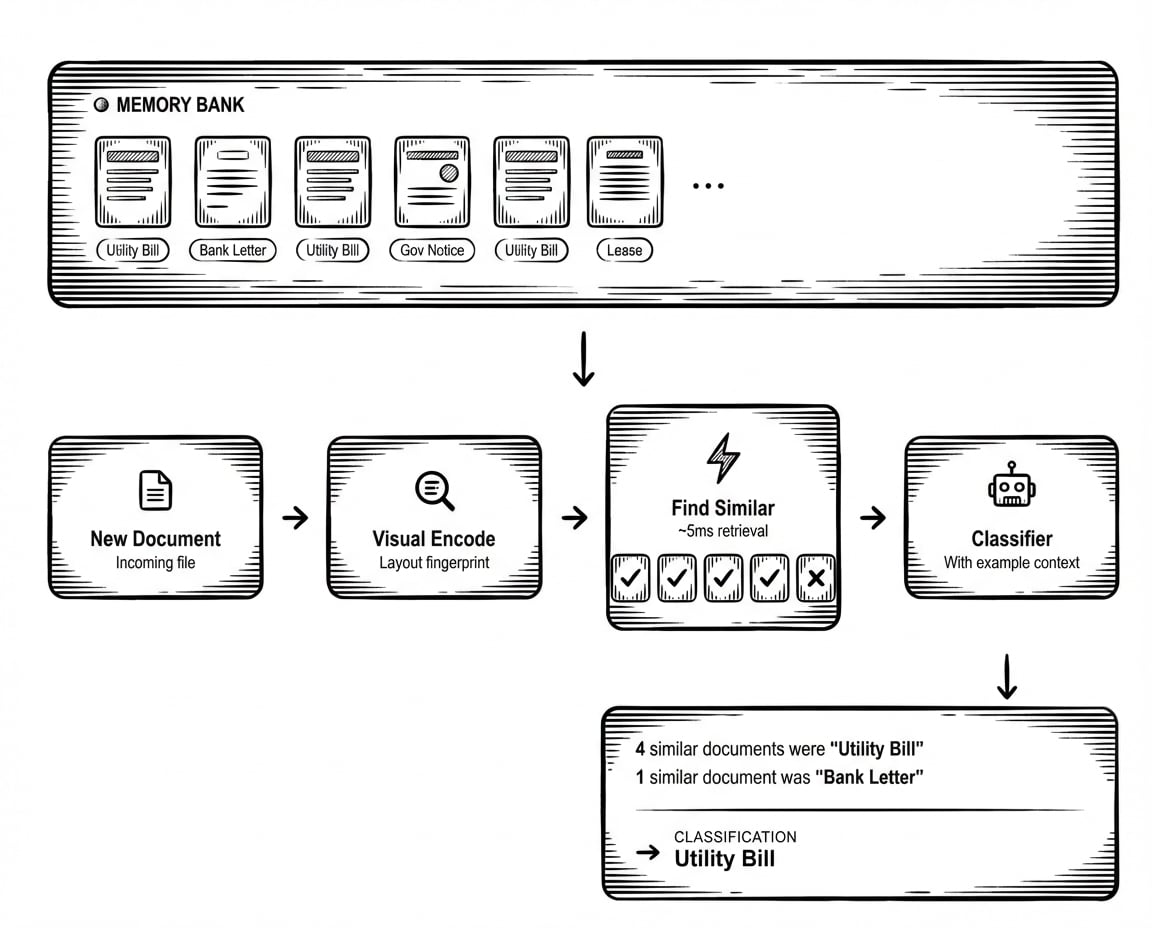
Die Idee ist einfach. Jedes Mal, wenn Sie eine Klassifizierung validieren (bestätigen, dass das Modell richtig lag, oder korrigieren, wenn es falsch lag), wird dieses Dokument zu einem Referenzbeispiel. Wenn ein neues Dokument eintrifft, findet HoloRecall die visuell ähnlichsten Beispiele aus dieser Memory Bank und fügt sie in den Kontext des Classifiers ein.
Anstatt dass der Prompt sagt: „Eine Rechnung ist ein kommerzielles Dokument, das zur Zahlung für Waren oder Dienstleistungen auffordert“, enthält der Kontext nun: „Hier sind fünf Dokumente mit ähnlichen Layouts. Vier wurden als Rechnung klassifiziert. Eines wurde als Quittung klassifiziert.“ Das Modell sieht tatsächliche Beispiele, keine abstrakten Definitionen.
Wie der Lernkreislauf funktioniert:
Wenn ein Benutzer eine Klassifizierung validiert oder korrigiert, wird das Dokument in eine visuelle Repräsentation kodiert, einen Fingerabdruck, der sein strukturelles Layout erfasst, nicht nur seinen Textinhalt. Dieser Fingerabdruck wandert in eine Memory Bank, die spezifisch für diesen Classifier ist. Kein Neutraining erforderlich. Keine Prompt-Änderungen. Das System erinnert sich einfach daran, was es gesehen hat.
Wie das Retrieval funktioniert:
Wenn ein neues Dokument eintrifft, erhält es dieselbe visuelle Kodierung. HoloRecall durchsucht die Memory Bank nach Dokumenten mit ähnlichen strukturellen Fingerabdrücken. Dies geschieht in Millisekunden, schnell genug, dass es die Klassifizierungslatenz nicht nennenswert beeinflusst. Die ähnlichsten Beispiele werden zusammen mit ihren validierten Labels abgerufen und dem Kontext des Classifiers hinzugefügt.
Warum das skaliert:
Das Hinzufügen einer neuen Klasse profitiert immer noch von einer guten Prompt-Definition, aber jetzt können Sie diese mit Beispielen ergänzen. Wenn Ihre Memory Bank wächst, sieht Ihr Classifier mehr Muster, bewältigt mehr Randfälle, erkennt mehr Variationen. Das System wird passiv intelligenter, durch normale Nutzung, ohne Code-Änderungen.
Das ist der Zinseszins-Vorteil: Jedes Dokument, das Sie verarbeiten und validieren, macht die nächste Klassifizierung etwas informierter. Ihr Classifier entwickelt ein institutionelles Gedächtnis.
Wo dies Dinge verändert
HoloRecall ist kein Ersatz für gute Prompts. Eine gut definierte Klassifizierungstaxonomie mit klaren, abgegrenzten Kategorien wird immer das Fundament sein. Aber es gibt spezifische Situationen, in denen ein Gedächtnis Hebelwirkung bietet, die Prompts nicht leisten können.
Randfälle, die sich der Beschreibung entziehen. Manche Dokumententypen sind in Worten wirklich schwer zu definieren. Der Unterschied zwischen einer „Proforma-Rechnung“ und einer „Handelsrechnung“ kann subtile Layout-Hinweise haben, die Sie erkennen, wenn Sie sie sehen, aber nur schwer artikulieren können. Anstatt immer kompliziertere Definitionen zu schreiben, zeigen Sie Beispiele und lassen die visuelle Ähnlichkeit die Arbeit machen.
Taxonomien mit hoher Kardinalität. Wenn Sie Dutzende oder Hunderte von Klassen haben, bietet ein Gedächtnis eine skalierbare Alternative zum Prompt-Bloat. Sie müssen keine 200 Klassenbeschreibungen in den Kontext quetschen. Sie rufen die relevanten Beispiele basierend auf visueller Ähnlichkeit ab und bieten gezielten Kontext statt erschöpfender Dokumentation.
Anbieterspezifische Layouts. Viele Klassifizierungsprobleme haben einen „Long Tail“ anbieterspezifischer Formate. Die Auszüge von Bank A sehen anders aus als die von Bank B. Die Frachtbriefe von Spediteur X haben andere Strukturen als die von Spediteur Y. Das Gedächtnis lernt diese anbieterspezifischen Muster automatisch, während Sie Dokumente von jeder Quelle verarbeiten.
Erste Schritte
HoloRecall ist heute für Classifier in Holofin verfügbar.
So aktivieren Sie es:
Navigieren Sie zur Konfigurationsseite Ihres Classifiers. Suchen Sie in der Tab-Navigation nach HoloRecall. Schalten Sie es ein, um mit dem Aufbau einer Memory Bank aus Ihren zuvor validierten Klassifizierungen zu beginnen. Sie können auch manuell repräsentative Beispiele für jede Klasse direkt in der Konfiguration hinzufügen. Sobald aktiviert, beginnt HoloRecall sofort, aus Ihrem Datensatz zu lernen.
Aufbau einer guten Memory Bank:
Die Qualität des Gedächtnisses hängt von der Qualität der Beispiele ab. Beginnen Sie mit der Synchronisierung von Beispielen aus Ihren Evaluierungssets; diese sind bereits validiert und repräsentativ. Wenn Sie Dokumente verarbeiten und Fehler korrigieren, werden diese Korrekturen zu neuen Beispielen. Mit der Zeit akkumuliert die Memory Bank eine Abdeckung Ihrer Dokumentenlandschaft.
Wann man es nutzen sollte:
Wie wir gezeigt haben, hilft HoloRecall am meisten, wenn Sie visuelle Variationen innerhalb von Klassen haben, wenn Ihre Taxonomie groß ist oder wenn Sie Genauigkeitsplateaus erreichen, die durch Prompt-Verfeinerung nicht gelöst werden können. Wenn Ihre Klassifizierung bereits gut mit einer kleinen, gut definierten Taxonomie funktioniert, bietet das HoloRecall-Feature weniger Mehrwert. Beginnen Sie mit Ihren Problemfällen.
Schlusswort
Wir haben lange geglaubt, dass bessere Klassifizierung bessere Anweisungen erfordert. Präzisere Definitionen. Mehr Randfallbehandlung. Sorgfältigeres Prompt Engineering.
Dieser Glaube war nicht falsch, genau genommen. Prompts sind wichtig. Aber sie haben Grenzen. Grenzen, die sichtbar werden, wenn Taxonomien wachsen, wenn visuelle Muster von semantischen Beschreibungen abweichen.
HoloRecall entspringt einem anderen Ansatz: Wir haben aufgehört zu versuchen, jeden Randfall zu beschreiben. Wir haben angefangen, uns an sie zu erinnern.
Verwandte Artikel
Wenn Dokumente zurückschlagen
Seite 1: Kontoübersicht, zwei Spalten. Seite 15: Dasselbe Konto, drei Spalten, andere Überschriften. Seite 47: Ein Scan mit einem Kaffeefleck. Seite 89: Die Seite mit den Summen, die sich auf Transaktionen beziehen, die Sie vor 70 Seiten extrahiert haben.

Der unsichtbare Audit-Trail
Ein Wirtschaftsprüfer öffnet Ihre Exportdatei, findet einen Endsaldo von 47.500 € und ruft das Quell-PDF auf. Seite 3, unten rechts: 47.000 €. Eine andere Zahl. "Woher kommt die Differenz? Wer hat das geändert?"

Dein LLM ist keine Dokumenten-Pipeline
Es gibt in jedem KI-Projekt diesen Moment, in dem die Demo so gut aussieht, dass dein Gehirn leise anfängt, Code zu löschen. Du siehst zu, wie ein Modell einen Kontoauszug "liest", und denkst: das ist es. Wir können OCR überspringen. Wir können das Layout-Parsing überspringen. Vielleicht können wir die halbe Pipeline überspringen. In der Filmversion drückt jemand Enter und JSON fällt wie ein Wasserfall aus der Cloud.