Una auditora abre el resultado de tu extracción de un balance general. El modelo reporta una precisión de celdas del 99.2%. Impresionante. Luego, suma la columna de activos a mano, como hacen los auditores, y el resultado es un número desfasado por una fila. Los activos ya no equivalen a los pasivos más el patrimonio. El estado financiero no cuadra.
El 0.8% en el que el modelo se equivocó no fue un error tipográfico en una nota al pie. Fue el total.
Este es el escándalo silencioso de la extracción de tablas en finanzas. Lo sabemos de primera mano, porque construimos nuestros primeros pipelines para perseguir exactamente estas puntuaciones: benchmarks que califican una tabla como una cuadrícula de strings, mientras que la única pregunta que realmente le importa a un lector financiero se queda sin hacer. ¿Los números siguen cuadrando? Las métricas que ganan los leaderboards son, matemáticamente, ciegas a los errores que acaban con carreras.
Lo que los benchmarks realmente miden
Si has buscado un modelo de extracción de tablas, has visto las puntuaciones. TEDS. Cell-match accuracy. Grid similarity. Todas se reducen a la misma idea: alinear la tabla predicha con la tabla ground truth, recorrer las celdas y contar cuántas coinciden.
TEDS (Tree-Edit-Distance Similarity) es la más popular. Convierte cada tabla en un árbol de filas y celdas y mide cuántas ediciones se necesitan para convertir un árbol en el otro. Menos ediciones, mayor puntuación. Es una métrica genuinamente inteligente, y fue construida para responder a una pregunta genuinamente útil: ¿es esta aproximadamente la tabla correcta, con aproximadamente la forma y el texto correctos?
Esa pregunta está bien para una revisión bibliográfica o un scrape de Wikipedia. Es la pregunta equivocada para un estado de flujos de efectivo.
Porque así es como cada una de estas métricas trata a un número: como un string. La celda 1,234.56 es, para el evaluador, seis glifos en una caja. No tiene idea de que se supone que esta caja es la suma de las cuatro cajas de arriba. No tiene idea de que el valor en la fila etiquetada como "Total assets" es fundamental de una manera en que el valor en "Misc. accruals" no lo es. Cada celda vale la misma fracción de la puntuación, y la puntuación es un promedio.
En finanzas, los errores nunca se distribuyen uniformemente. Y el promedio oculta exactamente el lugar donde necesitas mirar.
Cuatro formas en las que una puntuación del 99% aún te entrega números incorrectos
Aquí están los modos de fallo que una métrica de similitud de strings no puede ver. Cada uno de estos obtiene una puntuación hermosa y te arruina el día.
1. La columna que se deslizó
Una tabla financiera de múltiples columnas tiene "2023" y "2022" lado a lado. El extractor lee la geometría ligeramente mal y desplaza cada valor en la columna del año anterior una celda hacia abajo. Ahora cada cifra de 2022 se atribuye a la partida incorrecta.
Para una métrica de coincidencia de celdas, casi no pasó nada. Los mismos strings están presentes, en casi las mismas celdas. TEDS apenas se inmuta. Para un lector, cada uno de los números del año anterior es incorrecto, y el análisis de varianza construido sobre ellos es ficción.
El estado financiero de origen
El tipo de estado financiero que realmente se le entrega a un extractor: una celda de encabezado fusionada a través de ambas columnas de años, una columna de notas, filas de sección de ancho completo, subelementos indentados y líneas de puntos. Obvio para un humano, un campo minado para un parser que decide qué número pertenece a qué fila y año. Cada cifra aquí es correcta.
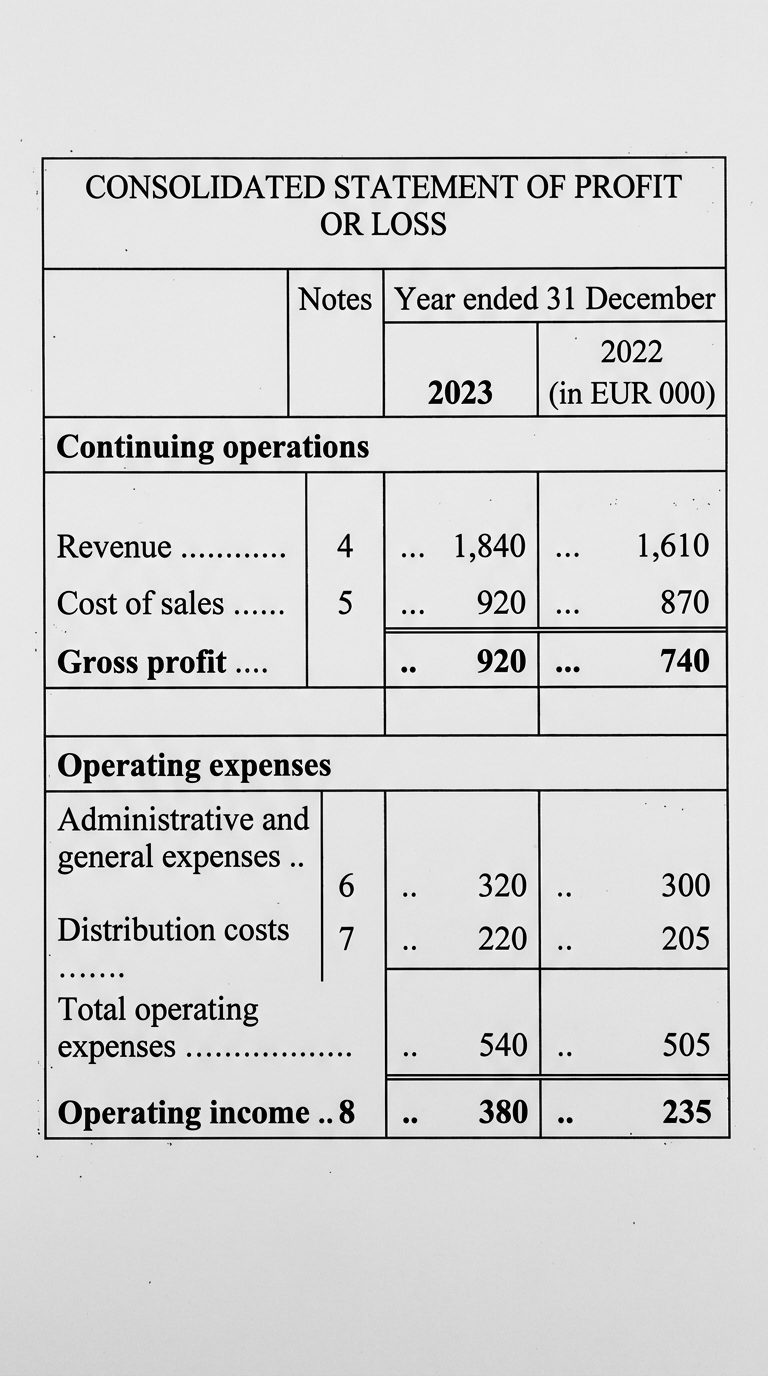
La columna que se deslizó
La columna de 2023 se extrajo bien. Cada valor en la columna de 2022 aterrizó una fila demasiado abajo, por lo que cada cifra del año anterior ahora se encuentra en la línea equivocada. La etiqueta te dice de quién es el número que realmente aterrizó en esa celda.
| Partida (Line item) | 2022 — en el documento | 2022 — extraído |
|---|---|---|
| Revenue | 1,610 | —valor omitido |
| Cost of sales | 870 | 1,610de Revenue |
| Gross profit | 740 | 870de Cost of sales |
| Opex | 505 | 740de Gross profit |
| Operating income | 235 | 505de Opex |
2. El decimal que se movió
Un estado financiero alemán escribe 1.234,56. El modelo, entrenado en un mundo de comas para los miles, lo "corrige" amablemente a 1,234.56, o peor aún, elimina los separadores y devuelve 123456.
Todos los dígitos están ahí. La similitud de strings está encantada. El valor está desfasado por un factor de cien. Cambia a un estado financiero francés, donde el separador de miles es un espacio, y el mismo modelo divide un número en tres.
El locale no es formato. El locale es aritmética. Una coma en el lugar equivocado no es una elección de estilo, es un número diferente.
3. El encabezado que se extravió
Los números se extraen perfectamente. Cada dígito es correcto. Pero el encabezado de columna "Restated" (Reexpresado) se fusionó con el de al lado, por lo que ahora no puedes saber qué cifras son la reexpresión y cuáles son las originales. Las celdas coinciden con el ground truth. El significado no sobrevive.
Una tabla donde los números son correctos y los encabezados son incorrectos no es un 95% correcta. Es un montón de dígitos correctos sin idea de lo que cuentan. En finanzas, un número sin su etiqueta no es un dato. Es ruido que resulta ser numérico.
4. El negativo que se volvió positivo
Los contadores escriben los negativos como (1,200). Muchos extractores leen los paréntesis como decoración y devuelven 1,200. Una provisión se convierte en un activo. Una salida de dinero se convierte en una entrada.
Un carácter. El signo del flujo de efectivo. La métrica cuenta los dígitos como una coincidencia y sigue adelante.
Por qué la métrica literalmente no puede ver el problema
Nota el patrón. En cada caso anterior, la tabla está estructuralmente bien y aritméticamente rota. Las filas están ahí, las columnas están ahí, los strings son cercanos. La estructura aprobó. La aritmética falló. Y la puntuación no puede notar la diferencia, porque nunca estuvo midiendo la aritmética en primer lugar.
El documento que el benchmark califica
Una nota de ingresos directamente de un informe: encabezado de año fusionado, una columna de notas, líneas numeradas. Un modelo leerá cada dígito perfectamente y aun así te entregará un total que no cuadra.
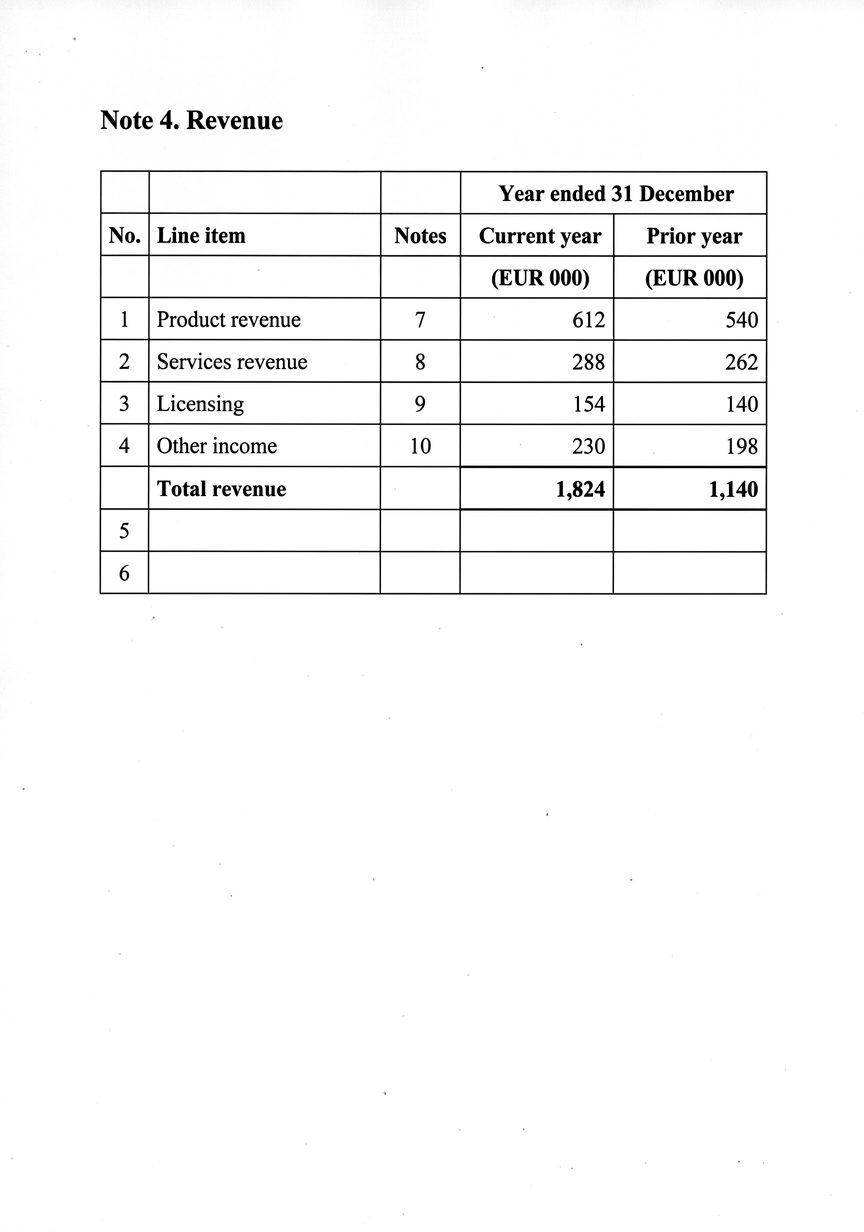
La estructura aprobó. La aritmética falló.
Cada celda coincide con la referencia, por lo que cada una gana su marca verde. Pero suma las cuatro partidas y llegan a 1,284 — no a los 1,824 impresos en la línea de total. Una métrica de strings no tiene forma de ver esa brecha.
| Partida (Line item) | Monto (€000) |
|---|---|
| Product revenue | 612 |
| Services revenue | 288 |
| Licensing | 154 |
| Other income | 230 |
| Suma de las cuatro líneas | 1,284 |
| Total revenue (impreso) | 1,824Δ 540 |
Este no es un problema de ajuste (tuning). No puedes solucionarlo dándole más peso a algunas celdas, porque la métrica no tiene representación de las relaciones que importan. No sabe que una columna debe sumar su total. No sabe que los activos equivalen a los pasivos más el patrimonio. No sabe que el saldo de cierre de este trimestre es el saldo de apertura del próximo trimestre. Para una puntuación de similitud de strings, un balance general y un menú de comida para llevar son el mismo tipo de objeto: una cuadrícula de texto.
La información que hace que una tabla financiera sea financiera, las restricciones entre los números, es exactamente la información que estos benchmarks desechan antes de que siquiera comience la calificación.
Así que obtienes modelos que lideran la tabla de posiciones (leaderboard) y aun así no se les puede confiar un P&L. El leaderboard nunca estuvo probando lo que necesitas.
La métrica que las finanzas realmente necesitan
Aquí está el replanteamiento. Deja de preguntar "qué tan similar es esta tabla a la tabla de referencia". Empieza a preguntar "¿esta tabla cuadra?"
Un estado financiero no es un artefacto difuso que calificas con un porcentaje. Es un sistema de ecuaciones con invariantes conocidas:
- Las partidas suman sus subtotales. Los subtotales suman sus totales.
- En un balance general, los activos equivalen a los pasivos más el patrimonio.
- En datos de partida doble, los débitos equivalen a los créditos.
- Un saldo de cierre en un período equivale al saldo de apertura en el siguiente, en ausencia de una reexpresión explícita.
- Una columna de porcentajes, recalculada a partir de sus columnas de origen, se reproduce a sí misma.
Estas no son heurísticas. Son la definición de un estado financiero correcto. Y te dan algo que una puntuación de similitud nunca podrá: una verificación binaria, interna del documento, que no necesita ningún ground truth en absoluto. La tabla se reconcilia o no lo hace. Cuando no lo hace, no necesitas a un anotador para decirte que algo está mal. La aritmética te lo dice.
En pseudocódigo, la prueba que realmente importa no se parece en nada a una distancia de edición:
# Not: how close are these two grids of strings?
# But: does the extracted table obey its own arithmetic?
def reconciles(table):
for total_row in table.totals():
components = table.rows_feeding(total_row)
if abs(sum(components) - total_row.value) > tolerance:
return Fail(total_row, expected=sum(components), got=total_row.value)
if table.is_balance_sheet():
if abs(table.assets - (table.liabilities + table.equity)) > tolerance:
return Fail("balance sheet does not balance")
return Pass()
La parte hermosa: esta verificación se ejecuta en un solo documento, sin anotación de referencia, en producción, en el estado financiero real que tu cliente acaba de subir. Un benchmark de similitud de celdas solo puede decirte cómo le fue a un modelo en el conjunto de pruebas de otra persona el mes pasado. La reconciliación te dice si este número, el que está a punto de fluir hacia una decisión de crédito, es confiable en este momento.
Dos preguntas, dos métricas
La industria construyó métricas de tablas para responder a una pregunta. Las finanzas siempre estuvieron haciendo una diferente.
Lo que preguntan los benchmarks
“¿Es esta aproximadamente la tabla correcta?”
- Un string de glifos en una caja
- Vale lo mismo que cualquier otra celda
- Promediada en un solo número
- Sumas y subtotales
- Signos y negativos entre paréntesis
- Desplazamientos de decimales y locale
- Encabezados huérfanos
Lo que preguntan las finanzas
“¿Esta tabla cuadra?”
- Σ partidas = subtotal = total
- Activos = pasivos + patrimonio
- Débitos = créditos
- Saldo de cierre = próxima apertura*
- Sin anotación de ground truth
- Se ejecuta en un documento en vivo
Una tabla que no cuadra no es un 99% correcta. Es un 0% confiable. No hay crédito parcial en un estado financiero que no cuadra.
Cómo pensamos sobre esto en Holofin
Convertir documentos financieros caóticos en números sobre los que puedes basar una decisión es nuestro verdadero trabajo. El problema de las métricas anterior no es académico para nosotros. Es la diferencia entre la demostración de un modelo y un sistema que un auditor aprobará.
Algunos principios se derivan de tomar esto en serio:
- Reconciliar, no asemejar. No consideramos que una tabla esté extraída hasta que obedece su propia aritmética. Los totales deben sumar. Los balances generales deben cuadrar. Los períodos deben avanzar correctamente. La semejanza con una referencia es una conveniencia de desarrollo. La reconciliación es el verdadero contrato.
- Un número no es un string. Cada valor lleva su tipo, su signo, su locale y su moneda, analizados deliberadamente, no inferidos por cómo resultó estar puntuado.
(1.234,56)es un mil doscientos negativo, y lo tratamos de esa manera desde la primera pasada. - Restricciones sobre vibras. Cuando la aritmética no cuadra, no es una molestia de redondeo que deba suprimirse. Es una señal. La sacamos a la luz, probamos estrategias de extracción alternativas y la escalamos para revisión en lugar de enviar una respuesta incorrecta con confianza.
- Procedencia por número. Cada valor extraído lleva su página, su bounding box y su linaje de encabezados, para que un revisor pueda hacer clic en cualquier número y volver a los píxeles exactos de donde provino. Una cifra que no puedes rastrear es una cifra que no puedes defender.
Esta es también la razón por la que somos cuidadosos con los números que publicamos. Vemos más de un 97% de precisión zero-shot en documentos financieros comunes, y construimos las herramientas para atrapar ese último par de puntos porcentuales en lugar de fingir que no existen, porque en finanzas ese último par de puntos porcentuales es precisamente donde vive el total.
Cierre
La industria construyó métricas de extracción de tablas para responder "¿es esta aproximadamente la tabla correcta?". Las finanzas siempre estuvieron haciendo una pregunta diferente: "¿estos números cuadran?"
Un modelo puede pasar la primera prueba y fallar la segunda en la única fila que importa, y la puntuación nunca te lo dirá. Así que deja de calificar las tablas financieras por cómo se ven. Califícalas por si cuadran.
Si tu extractor alguna vez ha pasado un benchmark y aun así te ha entregado un estado financiero que no cuadraba, ya sabes qué número estaba mal. Era el total. Siempre es el total.
Artículos relacionados

Detección de fraude documental: Lo que un PDF no puede ocultar
Solíamos pensar que el fraude documental era un problema visual. Fuentes incorrectas. Columnas desalineadas. Un logotipo que se sentía ligeramente incorrecto. Construimos controles en torno a lo que ven los humanos, porque lo que ven los humanos era todo lo que teníamos.

Cuando los documentos contraatacan
Página 1: Resumen de cuenta, dos columnas. Página 15: Misma cuenta, tres columnas, nombres de encabezado diferentes. Página 47: Un escaneo con una mancha de café. Página 89: La página de totales, que hace referencia a transacciones que extrajiste hace 70 páginas.

El rastro de auditoría invisible
Un auditor abre tu archivo de exportación, encuentra un saldo de cierre de 47.500 € y saca el PDF de origen. Página 3, esquina inferior derecha: 47.000 €. Un número diferente. "¿De dónde viene la diferencia? ¿Quién lo cambió?"