Eine Wirtschaftsprüferin öffnet Ihr Extraktionsergebnis für eine Bilanz. Das Modell zeigt eine Genauigkeit pro Zelle von 99,2 %. Beeindruckend. Dann summiert sie die Aktiva-Spalte von Hand, wie es Prüfer eben tun, und erhält eine Zahl, die um eine Zeile verschoben ist. Die Aktiva entsprechen nicht mehr den Passiva plus Eigenkapital. Die Bilanz geht nicht auf.
Die 0,8 %, bei denen sich das Modell geirrt hat, waren kein Tippfehler in einer Fußnote. Es war die Gesamtsumme.
Das ist der stille Skandal der Tabellen-Extraktion im Finanzwesen. Wir wissen das aus Erfahrung, denn wir haben unsere ersten Pipelines gebaut, um genau diesen Scores hinterherzujagen: Benchmarks, die eine Tabelle als ein Raster von Zeichenketten (strings) bewerten, während die einzige Frage, die für einen Finanzleser wirklich zählt, nie gestellt wird. Gehen die Zahlen immer noch auf? Die Metriken, die die leaderboards dominieren, sind mathematisch blind für Fehler, die Karrieren ruinieren.
Was Benchmarks wirklich messen
Wenn Sie nach einem Modell zur Tabellen-Extraktion gesucht haben, haben Sie die Scores gesehen. TEDS. Cell-match accuracy. Grid similarity. Sie laufen alle auf dieselbe Idee hinaus: Die vorhergesagte Tabelle mit der Referenztabelle (ground-truth) abgleichen, die Zellen durchgehen und zählen, wie viele übereinstimmen.
TEDS (Tree-Edit-Distance Similarity) ist am beliebtesten. Es wandelt jede Tabelle in einen Baum aus Zeilen und Zellen um und misst, wie viele Änderungen nötig sind, um den einen Baum in den anderen zu transformieren. Je weniger Änderungen, desto höher der Score. Es ist eine wirklich geniale Metrik, und sie wurde entwickelt, um eine wirklich nützliche Frage zu beantworten: Ist das in etwa die richtige Tabelle, mit in etwa der richtigen Form und dem richtigen Text?
Diese Frage ist völlig in Ordnung für eine Literaturrecherche oder das Scraping von Wikipedia. Es ist die falsche Frage für eine Kapitalflussrechnung.
Denn so behandelt jede dieser Metriken eine Zahl: als eine Zeichenkette (string). Die Zelle 1,234.56 ist für den Evaluator sechs Glyphen in einer Box. Er hat keine Ahnung, dass diese Box die Summe der vier Boxen darüber sein soll. Er hat keine Ahnung, dass der Wert in der Zeile "Total assets" eine strukturelle Bedeutung trägt, die der Wert in "Misc. accruals" nicht hat. Jede Zelle ist denselben Bruchteil des Scores wert, und der Score ist ein Durchschnitt.
Im Finanzwesen sind Fehler nie gleichmäßig verteilt. Und der Durchschnitt verbirgt genau den Ort, an dem Sie hinsehen müssen.
Vier Wege, wie ein Score von 99 % Ihnen trotzdem falsche Zahlen liefert
Hier sind die Fehlermodi, die eine String-Similarity-Metrik nicht sehen kann. Jeder von ihnen erzielt einen großartigen Score und ruiniert Ihren Tag.
1. Die verrutschte Spalte
Eine mehrspaltige Finanztabelle zeigt "2023" und "2022" nebeneinander. Der Extraktor liest die Geometrie leicht falsch und verschiebt jeden Wert der Vorjahresspalte um eine Zelle nach unten. Nun ist jede Zahl aus 2022 der falschen Zeile zugeordnet.
Für eine cell-match-Metrik ist fast nichts passiert. Dieselben strings sind vorhanden, in fast denselben Zellen. TEDS zuckt kaum mit der Wimper. Für einen Leser sind absolut alle Zahlen des Vorjahres falsch, und die darauf aufgebaute Abweichungsanalyse ist reine Fiktion.
Der ursprüngliche Jahresabschluss
Die Art von Jahresabschluss, die ein Extraktor tatsächlich erhält: eine verbundene Kopfzelle über beide Jahres-Spalten, eine Anmerkungsspalte, Abschnittszeilen über die gesamte Breite, eingerückte Unterpunkte und Füllpunkte. Für einen Menschen offensichtlich, ein Minenfeld für einen Parser, der entscheiden muss, welche Zahl zu welcher Zeile und zu welchem Jahr gehört. Jede Zahl hier ist korrekt.
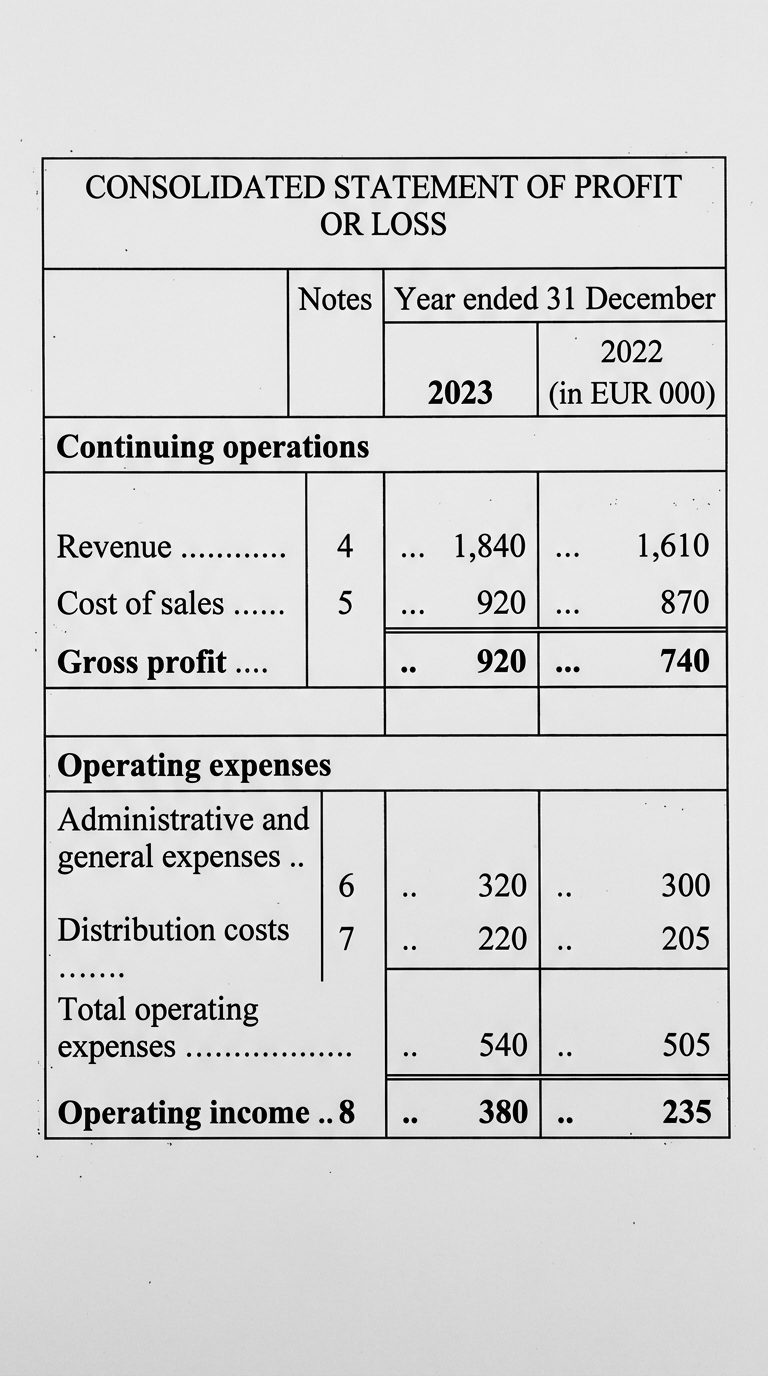
Die verrutschte Spalte
Die Spalte 2023 wurde korrekt extrahiert. Jeder Wert der Spalte 2022 ist eine Zeile zu tief gelandet, sodass sich jede Zahl des Vorjahres nun in der falschen Zeile befindet. Das Label zeigt Ihnen, zu wem die Zahl gehört, die tatsächlich in dieser Zelle gelandet ist.
| Buchungszeile | 2022 — im Dokument | 2022 — wie extrahiert |
|---|---|---|
| Umsatzerlöse | 1,610 | —verlorener Wert |
| Umsatzkosten | 870 | 1,610von Umsatzerlöse |
| Bruttomarge | 740 | 870von Umsatzkosten |
| Opex | 505 | 740von Bruttomarge |
| Betriebsergebnis | 235 | 505von Opex |
2. Das verschobene Dezimalzeichen
Ein deutscher Jahresabschluss schreibt 1.234,56. Das Modell, trainiert in einer Welt, in der das Komma Tausender trennt, „korrigiert“ es freundlicherweise zu 1,234.56 oder, noch schlimmer, entfernt die Trennzeichen und gibt 123456 zurück.
Die Ziffern sind alle da. Die String-Similarity ist begeistert. Der Wert ist um den Faktor hundert falsch. Wechseln Sie zu einem französischen Jahresabschluss, bei dem das Tausendertrennzeichen ein Leerzeichen ist, und dasselbe Modell teilt eine Zahl in drei.
Das locale ist keine Formatierung. Das locale ist Arithmetik. Ein Komma an der falschen Stelle ist keine Stilentscheidung, es ist eine andere Zahl.
3. Die verirrte Kopfzeile
Die Zahlen werden perfekt extrahiert. Jede Ziffer ist korrekt. Aber die Spaltenüberschrift "Restated" (Angepasst) wurde mit der danebenliegenden zusammengeführt, sodass nun unmöglich zu erkennen ist, welche Zahlen zur Anpassung gehören und welche die Originale sind. Die Zellen stimmen mit der ground-truth überein. Die Bedeutung jedoch überlebt das nicht.
Eine Tabelle, in der die Zahlen richtig und die Kopfzeilen falsch sind, ist nicht zu 95 % korrekt. Es ist ein Haufen korrekter Zahlen ohne jede Ahnung, was sie zählen. Im Finanzwesen ist eine Zahl ohne ihr Label keine Information. Es ist Rauschen, das zufällig numerisch ist.
4. Das Negativ, das positiv wurde
Buchhalter schreiben negative Zahlen so: (1,200). Viele Extraktoren lesen die Klammern als Dekoration und geben 1,200 zurück. Eine Rückstellung wird zu einem Vermögenswert. Ein Mittelabfluss wird zu einem Mittelzufluss.
Ein einziges Zeichen. Das Vorzeichen des Cashflows. Die Metrik zählt die Ziffern als Übereinstimmung und geht zum nächsten Punkt über.
Warum die Metrik das Problem buchstäblich nicht sehen kann
Erkennen Sie das Muster. In allen obigen Fällen ist die Tabelle strukturell korrekt und arithmetisch kaputt. Die Zeilen sind da, die Spalten sind da, die strings sind nah dran. Die Struktur hat bestanden. Die Arithmetik ist durchgefallen. Und der Score kann den Unterschied nicht erkennen, weil er die Arithmetik von vornherein nie gemessen hat.
Das Dokument, das der Benchmark bewertet
Eine Anmerkung zum Umsatz direkt aus einem Bericht: verbundene Jahres-Kopfzeile, Anmerkungsspalte, nummerierte Zeilen. Ein Modell wird jede Zahl perfekt lesen und Ihnen trotzdem eine Gesamtsumme liefern, die nicht der Summe entspricht.
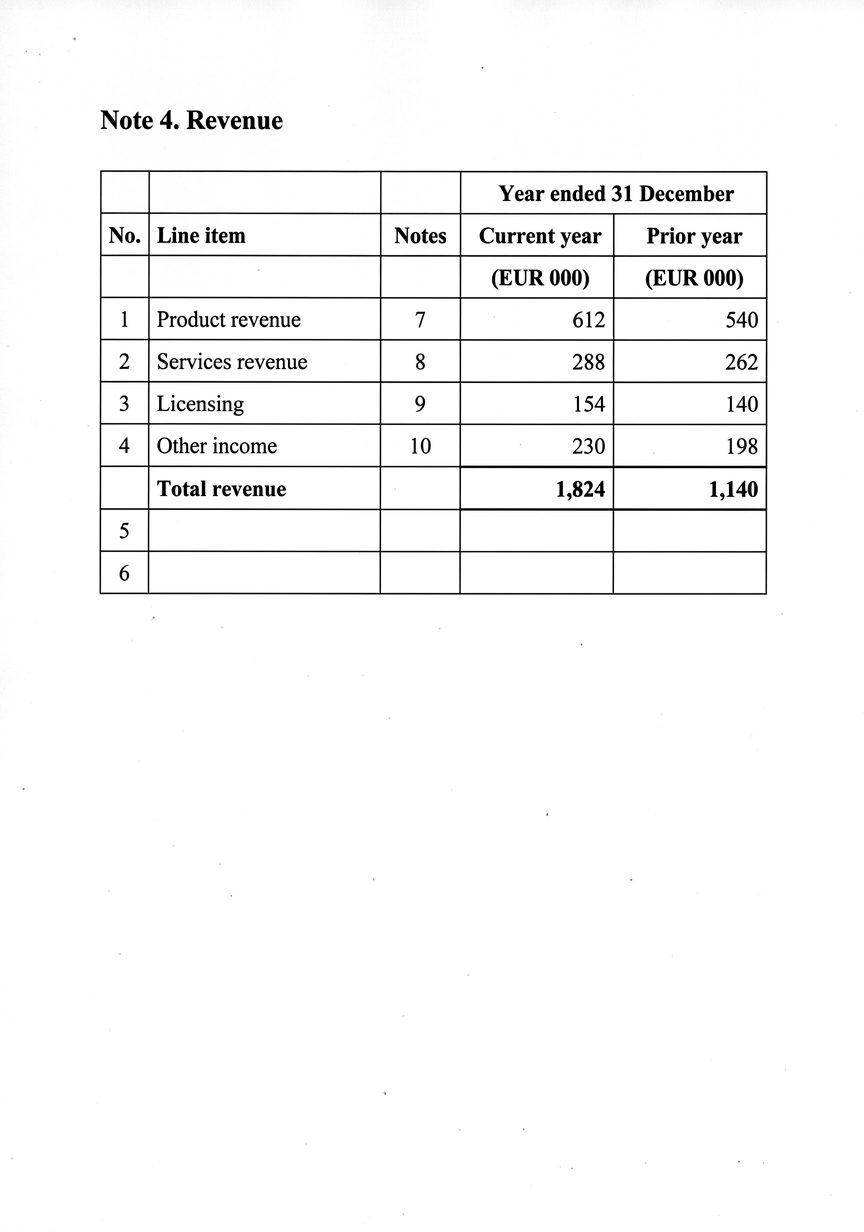
Die Struktur hat bestanden. Die Arithmetik ist durchgefallen.
Jede Zelle stimmt mit der Referenz überein, also verdient sich jede ihren grünen Haken. Aber addieren Sie die vier Zeilen und sie ergeben 1,284 — und nicht die 1,824, die in der Summenzeile gedruckt sind. Eine String-Metrik hat keine Möglichkeit, diese Abweichung zu sehen.
| Buchungszeile | Betrag (€000) |
|---|---|
| Produkterlöse | 612 |
| Dienstleistungserlöse | 288 |
| Lizenzen | 154 |
| Sonstige Erlöse | 230 |
| Summe der vier Zeilen | 1,284 |
| Gesamtumsatz (wie gedruckt) | 1,824Δ 540 |
Das ist kein Tuning-Problem. Sie können es nicht lösen, indem Sie bestimmte Zellen stärker gewichten, denn die Metrik hat keine Repräsentation der Beziehungen, auf die es ankommt. Sie weiß nicht, dass eine Spalte ihrer Gesamtsumme entsprechen muss. Sie weiß nicht, dass die Aktiva den Passiva plus Eigenkapital entsprechen. Sie weiß nicht, dass der Schlussbestand dieses Quartals der Anfangsbestand des nächsten Quartals ist. Für einen String-Similarity-Score sind eine Bilanz und eine Take-away-Speisekarte dieselbe Art von Objekt: ein Raster aus Text.
Die Information, die eine Finanztabelle finanziell macht, nämlich die Einschränkungen zwischen den Zahlen, ist genau die Information, die diese Benchmarks wegwerfen, noch bevor die Evaluierung überhaupt beginnt.
Sie erhalten also Modelle, die das leaderboard dominieren, denen man aber immer noch keine Gewinn- und Verlustrechnung (P&L) anvertrauen kann. Das leaderboard hat nie das getestet, was Sie brauchen.
Die Metrik, die das Finanzwesen wirklich braucht
Hier ist der Perspektivenwechsel. Hören Sie auf zu fragen: „Wie ähnlich ist diese Tabelle der Referenztabelle?“. Fangen Sie an zu fragen: „Geht diese Tabelle auf?“
Ein Jahresabschluss ist kein unscharfes Artefakt, das man mit einem Prozentsatz bewertet. Es ist ein Gleichungssystem mit bekannten Invarianten:
- Die Zeilen summieren sich zu ihren Zwischensummen. Die Zwischensummen summieren sich zu ihren Gesamtsummen.
- In einer Bilanz entsprechen die Aktiva den Passiva plus Eigenkapital.
- Bei der doppelten Buchführung entsprechen die Sollbuchungen den Habenbuchungen.
- Ein Schlussbestand einer Periode entspricht dem Anfangsbestand der nächsten, sofern keine explizite Anpassung vorliegt.
- Eine Prozent-Spalte, die aus ihren Quellspalten neu berechnet wird, reproduziert sich selbst.
Das sind keine Heuristiken. Es ist die Definition eines korrekten Jahresabschlusses. Und sie geben Ihnen etwas, das ein Similarity-Score Ihnen niemals geben kann: eine binäre, dokumentinterne Überprüfung, die keine ground-truth erfordert. Die Tabelle stimmt ab (reconciles) oder sie tut es nicht. Wenn dies nicht der Fall ist, brauchen Sie keinen Annotator, der Ihnen sagt, dass etwas nicht stimmt. Die Arithmetik sagt es Ihnen.
In Pseudocode sieht der Test, der wirklich zählt, überhaupt nicht nach einer Edit-Distanz aus:
# Not: how close are these two grids of strings?
# But: does the extracted table obey its own arithmetic?
def reconciles(table):
for total_row in table.totals():
components = table.rows_feeding(total_row)
if abs(sum(components) - total_row.value) > tolerance:
return Fail(total_row, expected=sum(components), got=total_row.value)
if table.is_balance_sheet():
if abs(table.assets - (table.liabilities + table.equity)) > tolerance:
return Fail("balance sheet does not balance")
return Pass()
Das Schöne daran: Diese Überprüfung läuft auf einem einzelnen Dokument, ohne Referenzannotation, in der Produktion, auf dem echten Auszug, den Ihr Kunde gerade hochgeladen hat. Ein cell-match-Benchmark kann Ihnen nur sagen, wie sich ein Modell letzten Monat auf dem Testdatensatz von jemand anderem verhalten hat. Die Abstimmung (Reconciliation) sagt Ihnen, ob diese Zahl, diejenige, die gleich eine Kreditentscheidung beeinflussen wird, genau in diesem Moment vertrauenswürdig ist.
Zwei Fragen, zwei Metriken
Die Industrie hat Tabellenmetriken entwickelt, um eine Frage zu beantworten. Das Finanzwesen hat schon immer eine andere gestellt.
Was Benchmarks fragen
“Ist das in etwa die richtige Tabelle?”
- Eine Kette von Glyphen in einer Box
- Ist genauso viel wert wie jede andere Zelle
- Gemittelt zu einer einzigen Zahl
- Summen und Zwischensummen
- Vorzeichen und Negative in Klammern
- Verschiebungen von Dezimalstellen und locales
- Verwaiste Kopfzeilen
Was das Finanzwesen fragt
“Geht diese Tabelle auf?”
- Σ Zeilen = Zwischensumme = Gesamtsumme
- Aktiva = Passiva + Eigenkapital
- Soll = Haben
- Schlussbestand = nächster Anfangsbestand*
- Keine ground-truth-Annotation
- Läuft auf einem Live-Dokument
Eine Tabelle, die nicht aufgeht, ist nicht zu 99 % richtig. Sie ist zu 0 % verlässlich. Es gibt keine Teilpunkte für einen Jahresabschluss, der nicht aufgeht.
Wie wir das bei Holofin angehen
Chaotische Finanzdokumente in Zahlen zu verwandeln, auf die Sie eine Entscheidung stützen können, ist unser eigentliches Geschäft. Das obige Metrik-Problem ist für uns nicht akademisch. Es ist der Unterschied zwischen der Demo eines Modells und einem System, das ein Wirtschaftsprüfer validieren wird.
Einige Prinzipien ergeben sich daraus, dies ernst zu nehmen:
- Abstimmen (Reconcile), nicht ähneln. Wir betrachten eine Tabelle nicht als extrahiert, solange sie nicht ihrer eigenen Arithmetik gehorcht. Gesamtsummen müssen der Summe entsprechen. Bilanzen müssen aufgehen. Perioden müssen aneinander anschließen. Die Ähnlichkeit mit einer Referenz ist eine Annehmlichkeit in der Entwicklung. Die Abstimmung ist der eigentliche Vertrag.
- Eine Zahl ist kein string. Jeder Wert trägt seinen Typ, sein Vorzeichen, sein locale und seine Währung, die bewusst geparst und nicht daraus abgeleitet werden, wie er punktiert wurde.
(1.234,56)ist ein negatives Eintausendzweihundert, und wir behandeln es vom ersten Durchlauf an so. - Einschränkungen statt Eindrücke (vibes). Wenn die Arithmetik nicht aufgeht, ist das keine Rundungsunannehmlichkeit, die man unterdrücken sollte. Es ist ein Signal. Wir heben es hervor, probieren alternative Extraktionsstrategien aus und eskalieren zur Überprüfung, anstatt selbstbewusst eine falsche Antwort zu liefern.
- Eine Herkunft pro Zahl. Jeder extrahierte Wert trägt seine Seite, seine bounding box und die Abstammung seiner Kopfzeile, sodass ein Prüfer auf jede beliebige Zahl klicken kann, um zu den genauen Pixeln zurückzukehren, aus denen sie stammt. Eine Zahl, die Sie nicht zurückverfolgen können, ist eine Zahl, die Sie nicht verteidigen können.
Das ist auch der Grund, warum wir vorsichtig mit den Zahlen sind, die wir veröffentlichen. Wir beobachten eine zero-shot-Genauigkeit von über 97 % bei gängigen Finanzdokumenten, und wir bauen die Werkzeuge, um die letzten Prozente abzufangen, anstatt so zu tun, als gäbe es sie nicht, denn im Finanzwesen sind diese letzten Prozente genau dort, wo sich die Gesamtsumme befindet.
Fazit
Die Industrie hat Metriken zur Tabellen-Extraktion entwickelt, um zu beantworten: „Ist das in etwa die richtige Tabelle?“. Das Finanzwesen hat schon immer eine andere Frage gestellt: „Gehen diese Zahlen auf?“
Ein Modell kann den ersten Test bestehen und beim zweiten bei der einzigen Zeile durchfallen, auf die es ankommt, und der Score wird es Ihnen nie sagen. Hören Sie also auf, Finanztabellen nach ihrem Aussehen zu bewerten. Bewerten Sie sie nach ihrer Fähigkeit, aufzugehen.
Wenn Ihr Extraktor schon einmal einen Benchmark bestanden hat und Ihnen gleichzeitig einen Jahresabschluss geliefert hat, der nicht aufging, wissen Sie bereits, welche Zahl falsch war. Es war die Gesamtsumme. Es ist immer die Gesamtsumme.
Verwandte Artikel

Dokumentenbetrug erkennen: Was ein PDF nicht verbergen kann
Früher dachten wir, Dokumentenbetrug sei ein visuelles Problem. Falsche Schriftarten. Verschobene Spalten. Ein Logo, das nicht ganz stimmig wirkte. Wir bauten Prüfungen basierend auf dem, was Menschen sehen, denn das war alles, was wir hatten.

Wenn Dokumente zurückschlagen
Seite 1: Kontoübersicht, zwei Spalten. Seite 15: Dasselbe Konto, drei Spalten, andere Überschriften. Seite 47: Ein Scan mit einem Kaffeefleck. Seite 89: Die Seite mit den Summen, die sich auf Transaktionen beziehen, die Sie vor 70 Seiten extrahiert haben.

Der unsichtbare Audit-Trail
Ein Wirtschaftsprüfer öffnet Ihre Exportdatei, findet einen Endsaldo von 47.500 € und ruft das Quell-PDF auf. Seite 3, unten rechts: 47.000 €. Eine andere Zahl. "Woher kommt die Differenz? Wer hat das geändert?"