Une auditrice ouvre votre résultat d'extraction pour un bilan. Le modèle affiche une précision par cellule de 99,2 %. Impressionnant. Puis elle fait le total de la colonne des actifs à la main, comme le font les auditeurs, et obtient un chiffre décalé d'une ligne. Les actifs ne sont plus égaux au passif plus les capitaux propres. Le bilan ne s'équilibre pas.
Les 0,8 % sur lesquels le modèle s'est trompé n'étaient pas une faute de frappe dans une note de bas de page. C'était le total.
C'est le scandale silencieux de l'extraction de tableaux en finance. Nous le savons d'expérience, car nous avons construit nos premiers pipelines pour courir exactement après ces scores : des benchmarks qui évaluent un tableau comme une grille de chaînes de caractères (strings), alors que la seule question qui importe vraiment à un lecteur financier n'est jamais posée. Les chiffres tiennent-ils toujours la route ? Les métriques qui dominent les leaderboards sont, mathématiquement, aveugles aux erreurs qui brisent des carrières.
Ce que les benchmarks mesurent réellement
Si vous avez cherché un modèle d'extraction de tableaux, vous avez vu les scores. TEDS. Cell-match accuracy. Grid similarity. Ils se résument tous à la même idée : aligner le tableau prédit avec le tableau de référence (ground-truth), parcourir les cellules et compter combien correspondent.
TEDS (Tree-Edit-Distance Similarity) est le plus populaire. Il transforme chaque tableau en un arbre de lignes et de cellules et mesure combien de modifications sont nécessaires pour transformer un arbre en l'autre. Moins il y a de modifications, plus le score est élevé. C'est une métrique véritablement ingénieuse, et elle a été conçue pour répondre à une question véritablement utile : est-ce à peu près le bon tableau, avec à peu près la bonne forme et le bon texte ?
Cette question est très bien pour une revue de littérature ou un scraping de Wikipedia. C'est la mauvaise question pour un tableau des flux de trésorerie.
Car voici comment chacune de ces métriques traite un nombre : comme une chaîne de caractères (string). La cellule 1,234.56 est, pour l'évaluateur, six glyphes dans une boîte. Il n'a aucune idée que cette boîte est censée être la somme des quatre boîtes au-dessus d'elle. Il n'a aucune idée que la valeur dans la ligne étiquetée "Total assets" est porteuse d'une importance structurelle que la valeur dans "Misc. accruals" n'a pas. Chaque cellule vaut la même fraction du score, et le score est une moyenne.
En finance, les erreurs ne sont jamais réparties uniformément. Et la moyenne cache exactement l'endroit où vous devez regarder.
Quatre façons dont un score de 99 % vous donne quand même de faux chiffres
Voici les modes de défaillance qu'une métrique de similarité de chaînes ne peut pas voir. Chacun d'entre eux obtient un score magnifique et ruine votre journée.
1. La colonne qui a glissé
Un tableau financier à plusieurs colonnes présente "2023" et "2022" côte à côte. L'extracteur lit la géométrie de manière légèrement erronée et décale chaque valeur de la colonne de l'année précédente d'une cellule vers le bas. Désormais, chaque chiffre de 2022 est attribué à la mauvaise ligne.
Pour une métrique de correspondance de cellules (cell-match), il ne s'est presque rien passé. Les mêmes chaînes sont présentes, dans presque les mêmes cellules. TEDS bronche à peine. Pour un lecteur, absolument tous les chiffres de l'année précédente sont faux, et l'analyse des écarts construite par-dessus n'est que pure fiction.
L'état financier source
Le genre d'état financier qu'un extracteur reçoit réellement : une cellule d'en-tête fusionnée sur les deux colonnes d'années, une colonne de notes, des lignes de section sur toute la largeur, des sous-éléments indentés et des points de suite. Évident pour un humain, un champ de mines pour un parseur qui doit décider quel chiffre appartient à quelle ligne et à quelle année. Chaque chiffre ici est correct.
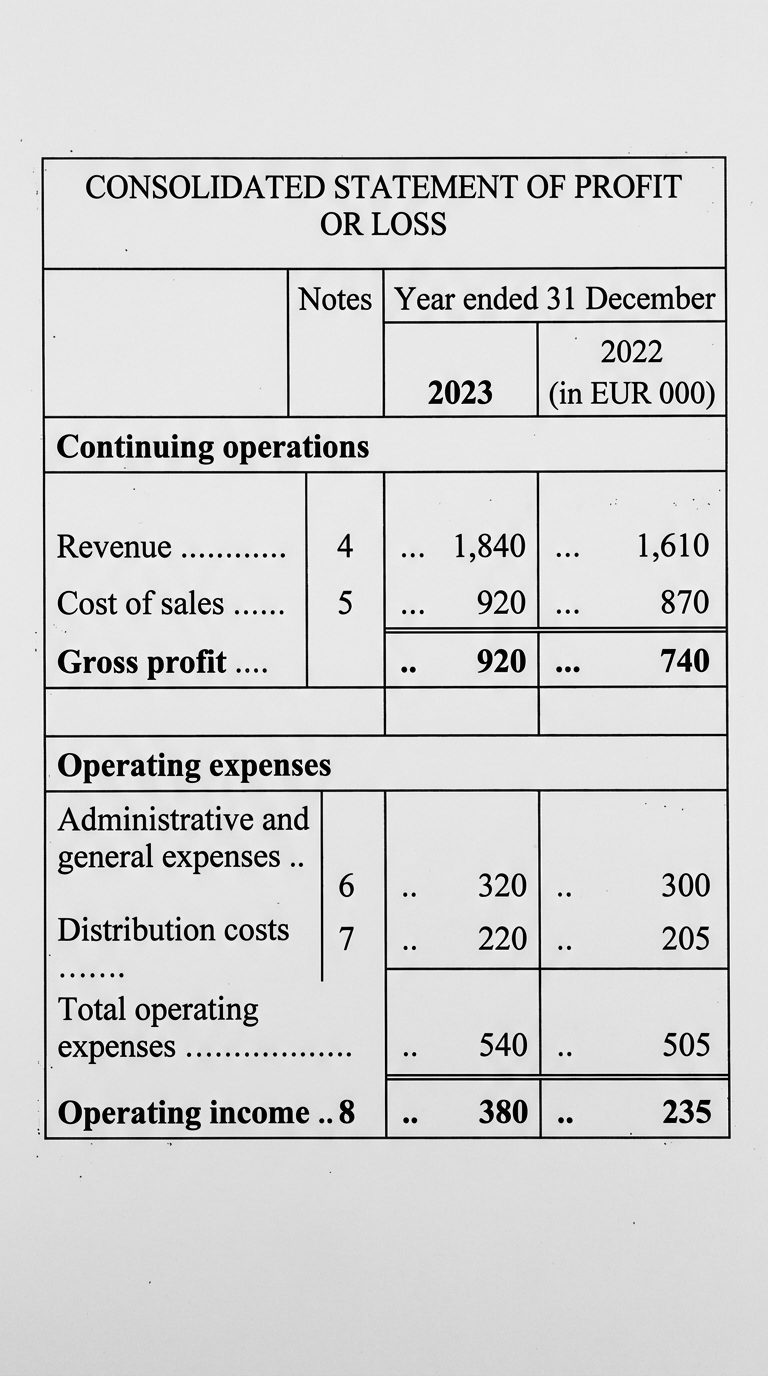
La colonne qui a glissé
La colonne 2023 a été extraite correctement. Chaque valeur de la colonne 2022 a atterri une ligne trop bas, de sorte que chaque chiffre de l'année précédente se trouve maintenant sur la mauvaise ligne. L'étiquette vous indique à qui appartient le chiffre qui a réellement atterri dans cette cellule.
| Ligne comptable | 2022 — dans le document | 2022 — tel qu'extrait |
|---|---|---|
| Chiffre d'affaires | 1,610 | —valeur perdue |
| Coût des ventes | 870 | 1,610du Chiffre d'affaires |
| Marge brute | 740 | 870du Coût des ventes |
| Opex | 505 | 740de la Marge brute |
| Résultat d'exploitation | 235 | 505des Opex |
2. La décimale qui s'est déplacée
Un état financier allemand écrit 1.234,56. Le modèle, entraîné dans un monde où la virgule sépare les milliers, le "corrige" gentiment en 1,234.56, ou pire, supprime les séparateurs et renvoie 123456.
Les chiffres sont tous là. La similarité de chaînes est ravie. La valeur est fausse d'un facteur cent. Passez à un état financier français, où le séparateur de milliers est un espace, et le même modèle divise un nombre en trois.
La locale n'est pas du formatage. La locale, c'est de l'arithmétique. Une virgule au mauvais endroit n'est pas un choix de style, c'est un nombre différent.
3. L'en-tête qui s'est égaré
Les chiffres sont extraits parfaitement. Chaque chiffre est correct. Mais l'en-tête de colonne "Restated" (Retraité) a été fusionné avec celui d'à côté, de sorte qu'il est désormais impossible de savoir quels chiffres correspondent au retraitement et lesquels sont les originaux. Les cellules correspondent à la vérité terrain (ground truth). Le sens, lui, n'y survit pas.
Un tableau où les chiffres sont justes et les en-têtes sont faux n'est pas correct à 95 %. C'est une pile de chiffres corrects sans aucune idée de ce qu'ils comptent. En finance, un nombre sans son étiquette n'est pas une donnée. C'est du bruit qui s'avère être numérique.
4. Le négatif devenu positif
Les comptables écrivent les nombres négatifs ainsi : (1,200). De nombreux extracteurs lisent les parenthèses comme une décoration et renvoient 1,200. Une provision devient un actif. Une sortie de fonds devient une entrée.
Un seul caractère. Le signe du flux de trésorerie. La métrique compte les chiffres comme une correspondance et passe à autre chose.
Pourquoi la métrique ne peut littéralement pas voir le problème
Remarquez le schéma. Dans tous les cas ci-dessus, le tableau est structurellement correct et arithmétiquement cassé. Les lignes sont là, les colonnes sont là, les chaînes sont proches. La structure a réussi. L'arithmétique a échoué. Et le score ne peut pas faire la différence, car il n'a jamais mesuré l'arithmétique pour commencer.
Le document que le benchmark évalue
Une note sur le chiffre d'affaires tirée directement d'un rapport : en-tête d'année fusionné, colonne de notes, lignes numérotées. Un modèle lira chaque chiffre parfaitement et vous donnera quand même un total qui ne correspond pas à la somme.
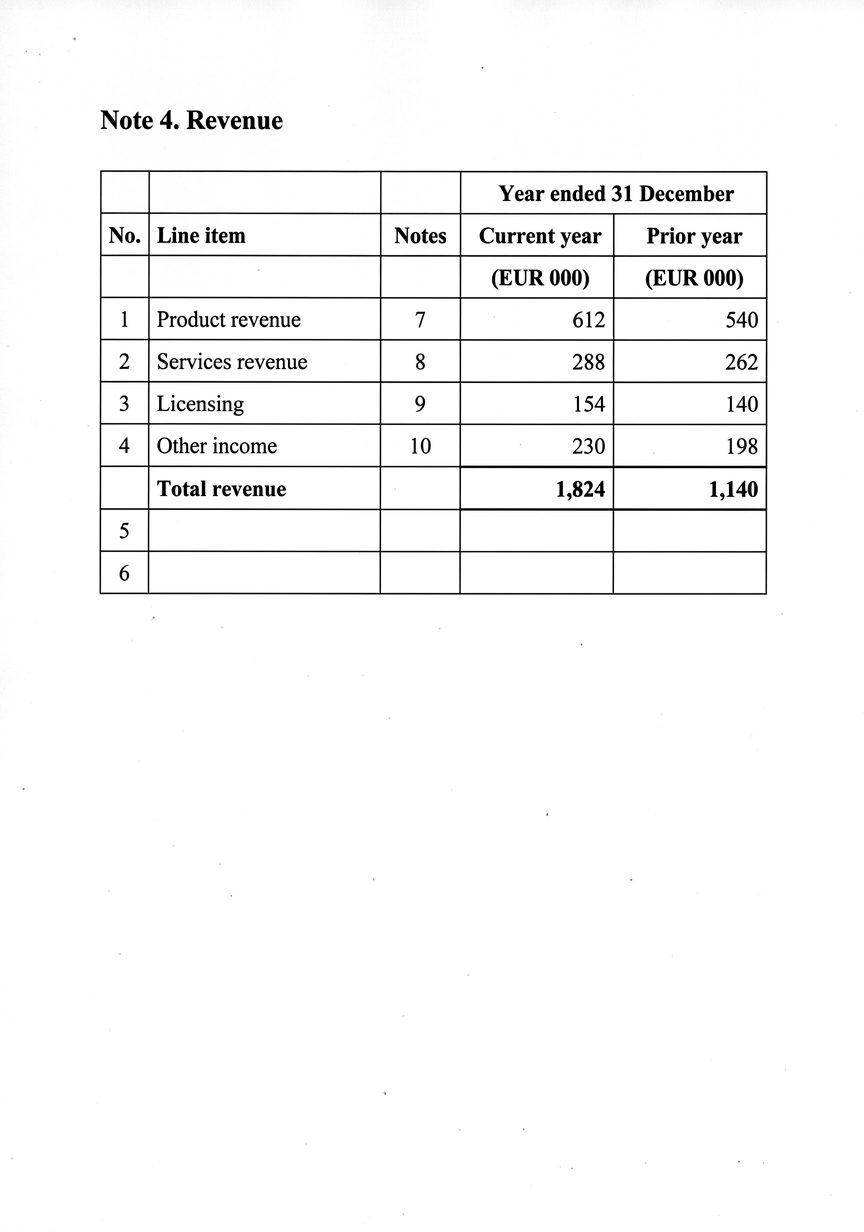
La structure a réussi. L'arithmétique a échoué.
Chaque cellule correspond à la référence, donc chacune gagne sa coche verte. Mais additionnez les quatre lignes et elles totalisent 1,284 — et non les 1,824 imprimés sur la ligne de total. Une métrique de chaînes de caractères n'a aucun moyen de voir cet écart.
| Ligne comptable | Montant (€000) |
|---|---|
| Revenus des produits | 612 |
| Revenus des services | 288 |
| Licences | 154 |
| Autres revenus | 230 |
| Somme des quatre lignes | 1,284 |
| Chiffre d'affaires total (tel qu'imprimé) | 1,824Δ 540 |
Ce n'est pas un problème de réglage. Vous ne pouvez pas le résoudre en pondérant plus lourdement certaines cellules, car la métrique n'a aucune représentation des relations qui comptent. Elle ne sait pas qu'une colonne doit correspondre à son total. Elle ne sait pas que les actifs sont égaux au passif plus les capitaux propres. Elle ne sait pas que le solde de clôture de ce trimestre est le solde d'ouverture du trimestre suivant. Pour un score de similarité de chaînes, un bilan et un menu de vente à emporter sont le même type d'objet : une grille de texte.
L'information qui rend un tableau financier financier, à savoir les contraintes entre les nombres, est exactement l'information que ces benchmarks jettent avant même que l'évaluation ne commence.
Vous obtenez donc des modèles qui dominent le leaderboard mais à qui l'on ne peut toujours pas confier un compte de résultat (P&L). Le leaderboard n'a jamais testé ce dont vous avez besoin.
La métrique dont la finance a réellement besoin
Voici le changement de perspective. Arrêtez de demander "à quel point ce tableau est-il similaire au tableau de référence". Commencez à demander "ce tableau s'équilibre-t-il ?"
Un état financier n'est pas un artefact flou que l'on évalue avec un pourcentage. C'est un système d'équations avec des invariants connus :
- Les lignes s'additionnent pour former leurs sous-totaux. Les sous-totaux s'additionnent pour former leurs totaux.
- Dans un bilan, les actifs sont égaux au passif plus les capitaux propres.
- Dans les données en partie double, les débits sont égaux aux crédits.
- Un solde de clôture d'une période est égal au solde d'ouverture de la suivante, en l'absence de retraitement explicite.
- Une colonne de pourcentages, recalculée à partir de ses colonnes sources, se reproduit elle-même.
Ce ne sont pas des heuristiques. C'est la définition d'un état financier correct. Et elles vous donnent quelque chose qu'un score de similarité ne pourra jamais vous donner : une vérification binaire, interne au document, qui ne nécessite aucune vérité terrain (ground truth). Le tableau se réconcilie ou il ne se réconcilie pas. Quand ce n'est pas le cas, vous n'avez pas besoin d'un annotateur pour vous dire que quelque chose cloche. L'arithmétique vous le dit.
En pseudo-code, le test qui compte vraiment ne ressemble en rien à une distance d'édition :
# Not: how close are these two grids of strings?
# But: does the extracted table obey its own arithmetic?
def reconciles(table):
for total_row in table.totals():
components = table.rows_feeding(total_row)
if abs(sum(components) - total_row.value) > tolerance:
return Fail(total_row, expected=sum(components), got=total_row.value)
if table.is_balance_sheet():
if abs(table.assets - (table.liabilities + table.equity)) > tolerance:
return Fail("balance sheet does not balance")
return Pass()
La beauté de la chose : cette vérification s'exécute sur un document unique, sans annotation de référence, en production, sur le vrai relevé que votre client vient de télécharger. Un benchmark de similarité de cellules ne peut que vous dire comment un modèle s'est comporté sur le jeu de test de quelqu'un d'autre le mois dernier. La réconciliation vous dit si ce chiffre, celui qui est sur le point d'influencer une décision de crédit, est digne de confiance en ce moment même.
Deux questions, deux métriques
L'industrie a construit des métriques de tableaux pour répondre à une question. La finance en a toujours posé une autre.
Ce que demandent les benchmarks
“Est-ce à peu près le bon tableau ?”
- Une chaîne de glyphes dans une boîte
- Vaut la même chose que n'importe quelle autre cellule
- Moyennée en un seul nombre
- Sommes et sous-totaux
- Signes et négatifs entre parenthèses
- Décalages de décimales et de locales
- En-têtes orphelins
Ce que demande la finance
“Ce tableau s'équilibre-t-il ?”
- Σ lignes = sous-total = total
- Actifs = passif + capitaux propres
- Débits = crédits
- Solde de clôture = prochaine ouverture*
- Aucune annotation de vérité terrain (ground-truth)
- S'exécute sur un document en direct
Un tableau qui ne s'équilibre pas n'est pas juste à 99 %. Il est fiable à 0 %. Il n'y a pas de point de complaisance pour un état financier qui ne s'équilibre pas.
Comment nous concevons cela chez Holofin
Transformer des documents financiers chaotiques en chiffres sur lesquels vous pouvez baser une décision est notre véritable métier. Le problème de métrique ci-dessus n'est pas académique pour nous. C'est la différence entre la démo d'un modèle et un système qu'un auditeur validera.
Quelques principes découlent du fait de prendre cela au sérieux :
- Réconcilier, pas ressembler. Nous ne considérons pas un tableau comme extrait tant qu'il n'obéit pas à sa propre arithmétique. Les totaux doivent correspondre à la somme. Les bilans doivent s'équilibrer. Les périodes doivent s'enchaîner. La ressemblance avec une référence est une commodité de développement. La réconciliation est le véritable contrat.
- Un nombre n'est pas une chaîne de caractères. Chaque valeur porte son type, son signe, sa locale et sa devise, parsés délibérément, et non déduits de la façon dont elle a été ponctuée.
(1.234,56)est un mille deux cents négatif, et nous le traitons ainsi dès le premier passage. - Des contraintes plutôt que des impressions (vibes). Lorsque l'arithmétique ne s'équilibre pas, ce n'est pas un désagrément d'arrondi à supprimer. C'est un signal. Nous le mettons en évidence, essayons des stratégies d'extraction alternatives et escaladons pour révision plutôt que de livrer une mauvaise réponse avec assurance.
- Une provenance par nombre. Chaque valeur extraite porte sa page, sa bounding box et le lignage de son en-tête, de sorte qu'un réviseur peut cliquer sur n'importe quel nombre pour remonter aux pixels exacts dont il provient. Un chiffre que vous ne pouvez pas tracer est un chiffre que vous ne pouvez pas défendre.
C'est aussi pourquoi nous sommes prudents quant aux chiffres que nous publions. Nous observons une précision zero-shot de plus de 97 % sur les documents financiers courants, et nous construisons les outils pour attraper les derniers pourcentages plutôt que de prétendre qu'ils n'existent pas, car en finance, ces derniers pourcentages sont précisément là où se trouve le total.
Conclusion
L'industrie a construit des métriques d'extraction de tableaux pour répondre à "est-ce à peu près le bon tableau". La finance a toujours posé une question différente : "ces chiffres tiennent-ils la route ?"
Un modèle peut réussir le premier test et échouer au second sur la seule ligne qui compte, et le score ne vous le dira jamais. Alors arrêtez d'évaluer les tableaux financiers sur leur apparence. Évaluez-les sur leur capacité à s'équilibrer.
Si votre extracteur a déjà réussi un benchmark tout en vous remettant un état financier qui ne s'équilibrait pas, vous savez déjà quel chiffre était faux. C'était le total. C'est toujours le total.
Articles connexes

Détection de fraude documentaire : ce qu'un PDF ne peut pas cacher
Nous pensions que la fraude documentaire était un problème visuel. Mauvaises polices. Colonnes mal alignées. Un logo qui semblait légèrement décalé. Nous avons construit des vérifications basées sur ce que les humains voient, car ce que les humains voient était tout ce que nous avions.

Quand les documents contre-attaquent
Page 1 : Résumé du compte, deux colonnes. Page 15 : Même compte, trois colonnes, noms d'en-tête différents. Page 47 : Un scan avec une tache de café. Page 89 : La page des totaux, qui fait référence à des transactions que vous avez extraites il y a 70 pages.

La piste d'audit invisible
Un auditeur ouvre votre fichier d'export, trouve un solde de clôture de 47 500 € et sort le PDF source. Page 3, coin inférieur droit : 47 000 €. Un chiffre différent. « D'où vient la différence ? Qui l'a modifié ? »