Documents to Reliable Data.
Without friction.
Holofin combines computer vision and agentic AI to deliver the most accurate document data extraction pipeline for your toughest use cases.
Build Document Pipelines
You Can Trust.
Deploy intelligent document processing with custom pipelines, precision extraction, and validation rules.
Document received
Routes by document type
Slack notification

Bank Statement

Invoice
ID Document

Medical Record
Classification
Bank Statement

Combined Statements
47 pages • 3 accounts
FR76 1234***
Q1 • 5p
FR76 9876***
Q4 • 18p
FR76 1234***
Q2-Q3 • 24p
Split by IBAN + Period
3 documents
Structured Data
6 fields extracted
Balance equation check
SIRET format validation
Date range validation
All validations passed
3/3 rules
Every value traceable to source
100% grounded
Document received
Routes by document type
Slack notification
Bank Statement
Invoice
ID Document
Medical Record
Classification
Bank Statement
Combined Statements
47 pages • 3 accounts
FR76 1234***
Q1 • 5p
FR76 9876***
Q4 • 18p
FR76 1234***
Q2-Q3 • 24p
Split by IBAN + Period
3 documents
Structured Data
6 fields extracted
Balance equation check
SIRET format validation
Date range validation
All validations passed
3/3 rules
Every value traceable to source
100% grounded
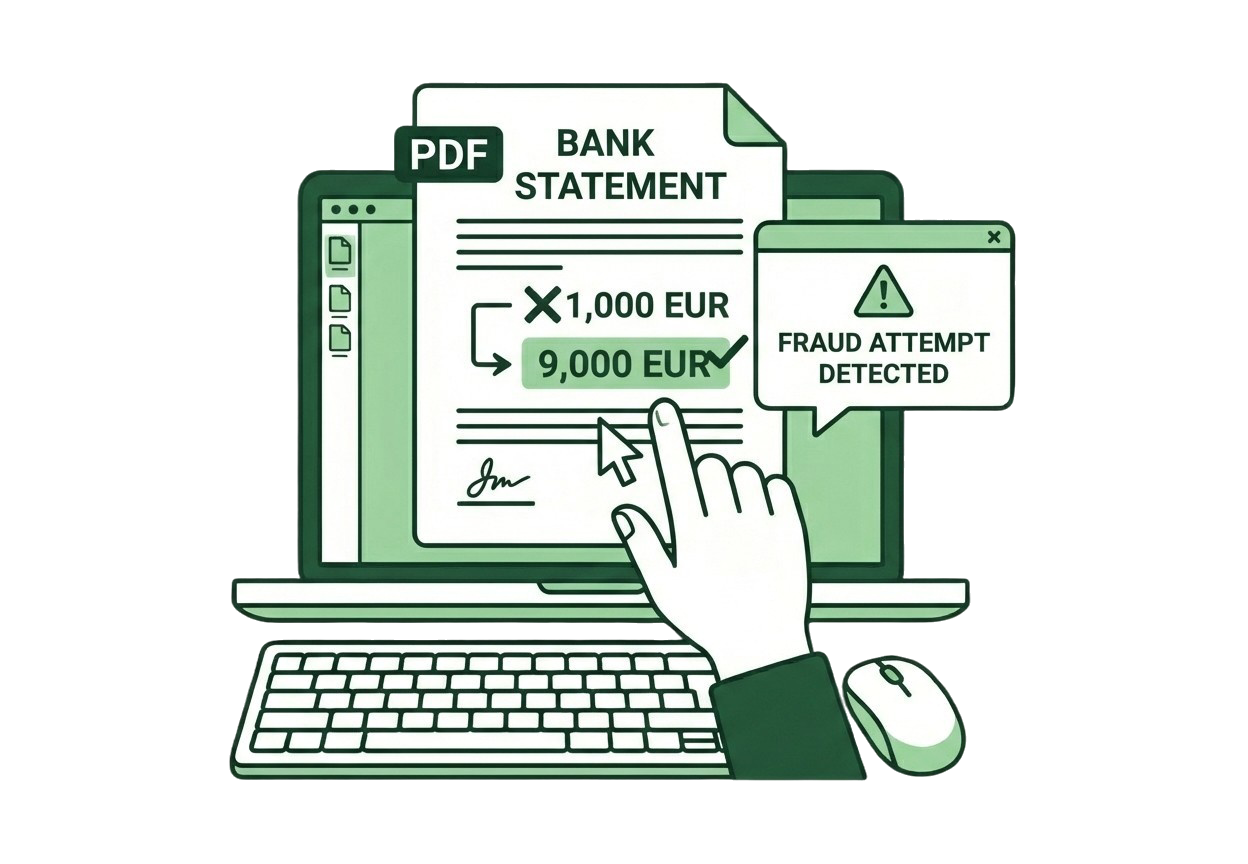
Built-in Forensics
Detect Fraud
Before You Extract.
70 forensic detectors analyze metadata, fonts, structure, and pixel patterns across 6 domains. Cross-domain corroboration means fewer false positives and verdicts you can act on.
How it works
Extract Documents
Like a Human
At Machine Scale
A multi-pass pipeline combining OCR, layout analysis, and vision models for superior accuracy and deep document understanding.
Traditional OCR
Holofin first applies precision OCR to read and extract characters within each zone, building a complete textual representation of the document.
Layout Recognition
Vision-language models recognize granular page components—text, titles, tables—converting unstructured visuals into a structured digital framework.
Structured Output
Fine-tuned models synthesize text and layout into clean, standardized formats, while an agentic pass detects and corrects mistakes like a human editor.
Traditional OCR
Holofin first applies precision OCR to read and extract characters within each zone, building a complete textual representation of the document.
Layout Recognition
Vision-language models recognize granular page components—text, titles, tables—converting unstructured visuals into a structured digital framework.
Structured Output
Fine-tuned models synthesize text and layout into clean, standardized formats, while an agentic pass detects and corrects mistakes like a human editor.
Hover over each step to see how documents transform through the pipeline
Built for Production
Enterprise-grade performance you can rely on

98%+
Extraction Accuracy
Zero-shot precision

20x
Faster Processing
vs manual workflow

100K+
Documents / Month
Production scale

99.9%
Uptime SLA
Reliability
Built for Your
Industry Challenges
Proven solutions across finance, logistics, insurance, and more.
Supported Documents
Export to your backend
 SAP
SAP Oracle
Oracle Sage
Sage QuickBooks
QuickBooks Xero
Xero Excel
Excel Google Sheets
Google Sheets Snowflake
Snowflake Salesforce
Salesforce Odoo
Odoo Dynamics 365SAPOracleSageQuickBooksXeroExcelGoogle SheetsSnowflakeSalesforceOdooDynamics 365
Dynamics 365SAPOracleSageQuickBooksXeroExcelGoogle SheetsSnowflakeSalesforceOdooDynamics 365Trusted by Teams
Building the Future
Holofin enabled us to process loan applications automatically, freeing our risk analysts to focus on complex cases. We now respond to clients in hours instead of days.
Head of Operations at Lending Broker, France