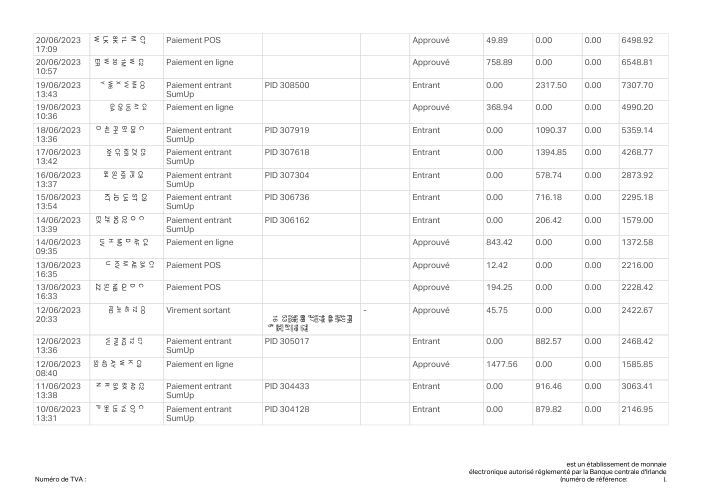
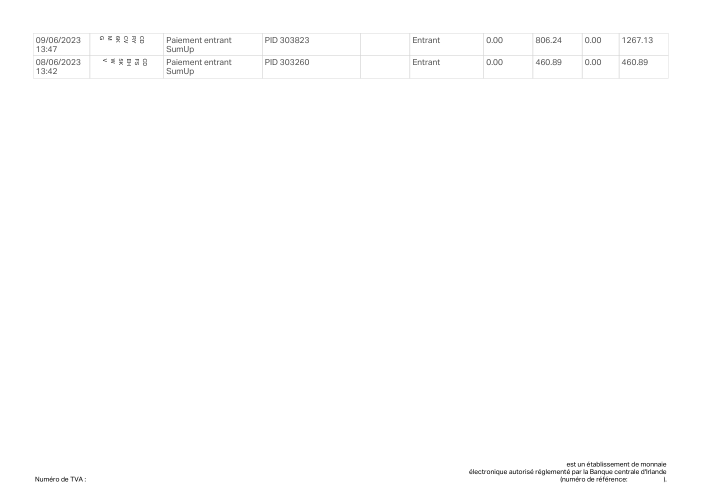
En holofin, la extracción de extractos bancarios es uno de nuestros trabajos principales, y lo ejecutamos en producción. Prestamistas, contables y equipos financieros nos entregan extractos de cientos de bancos diferentes y esperan que cada transacción sea devuelta, exactamente, sin nada inventado y sin omitir nada.
La extracción se sitúa en la parte más frontal de ese pipeline, por lo que sus errores nunca se quedan ahí. Una fila faltante o inventada no solo resta un punto a la puntuación de precisión. Se convierte en un balance que no cuadra, una decisión de viabilidad económica basada en un número que nunca estuvo en la página, un libro mayor en el que nadie más adelante puede confiar. Un extracto bancario es booleano: o es completamente correcto, o es un riesgo.
Así que queríamos saber con qué fiabilidad hacen esto realmente los mejores modelos actuales, no en una demo seleccionada a mano, sino en extractos reales, evaluados de la forma en que los evalúa un equipo financiero, donde lo único que cuenta es si todo el extracto cuadra. Construimos un benchmark para averiguarlo.
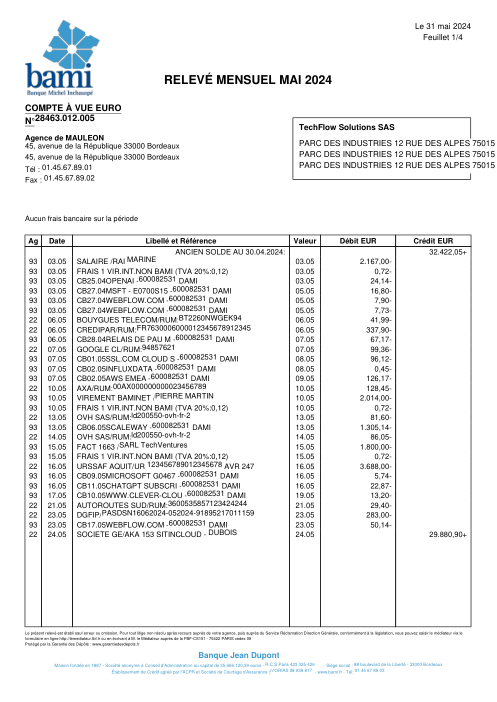
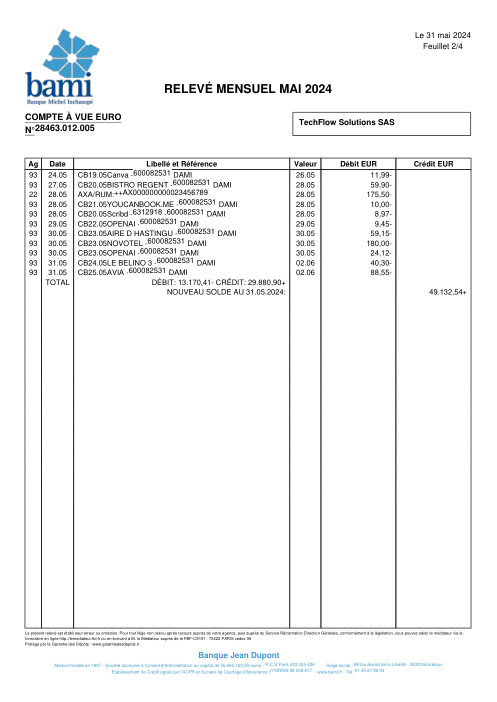
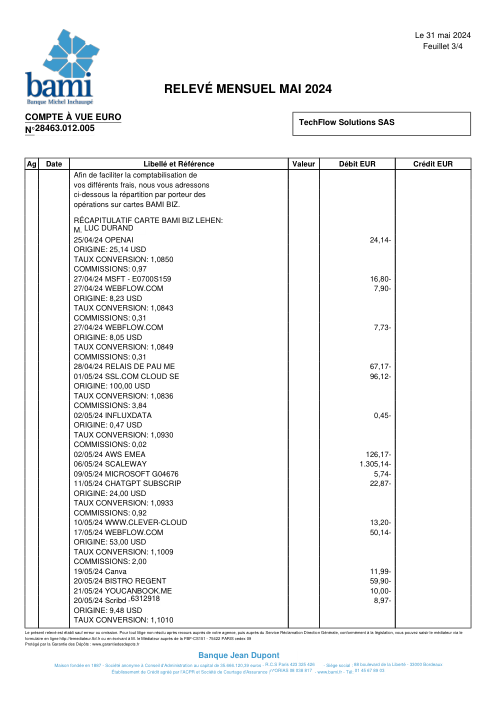
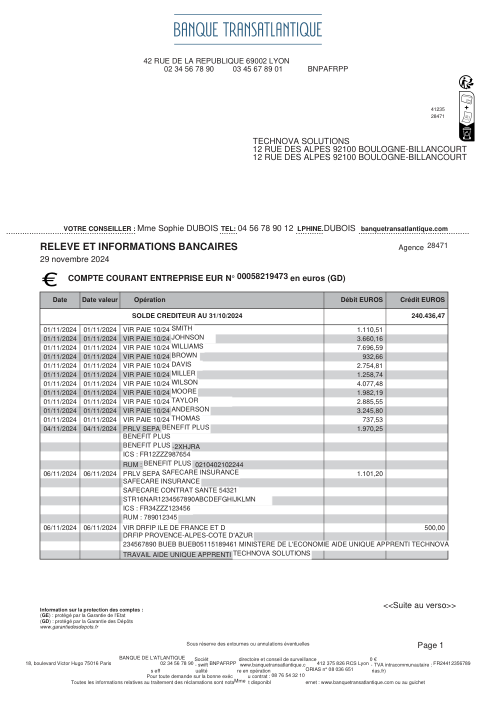
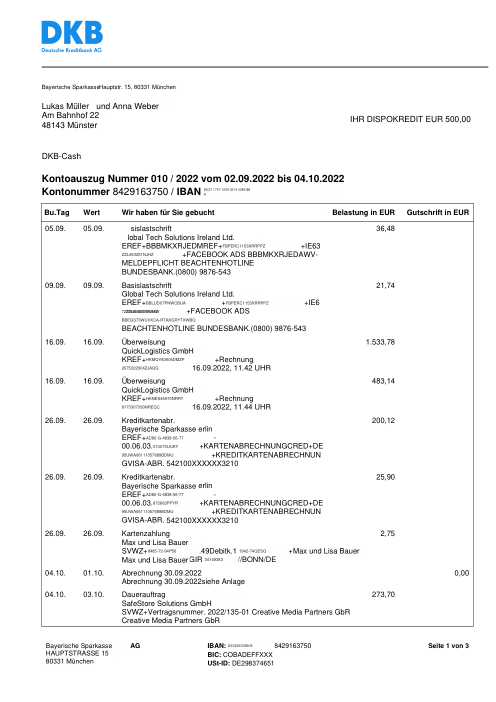
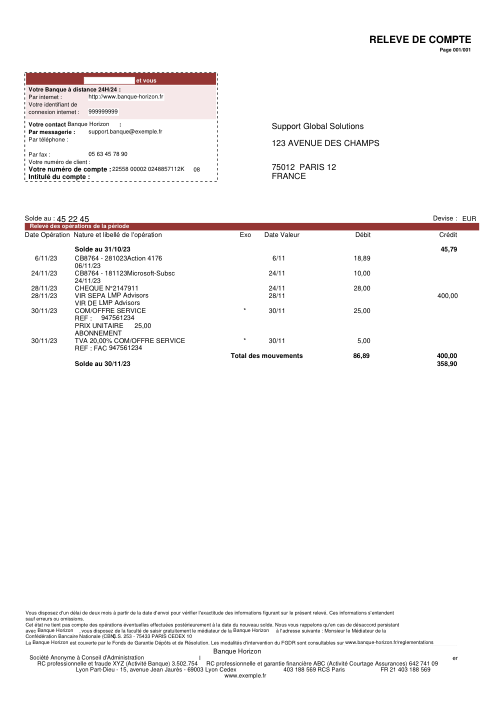
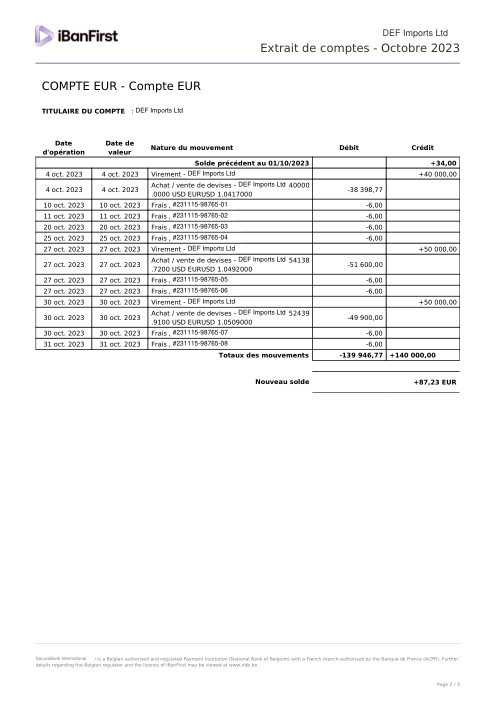
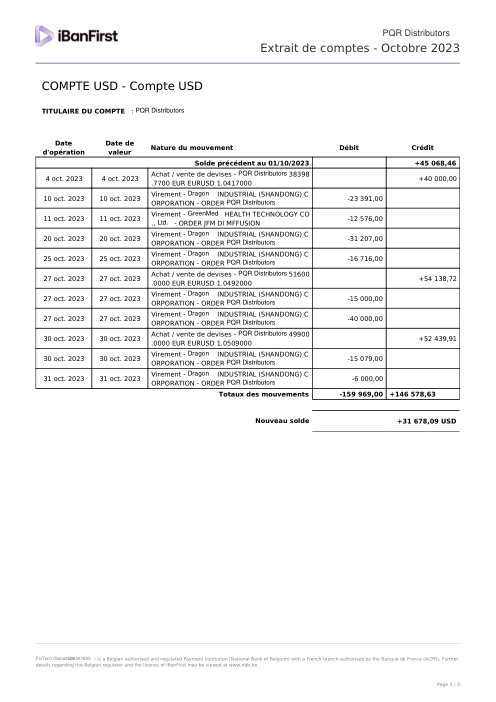
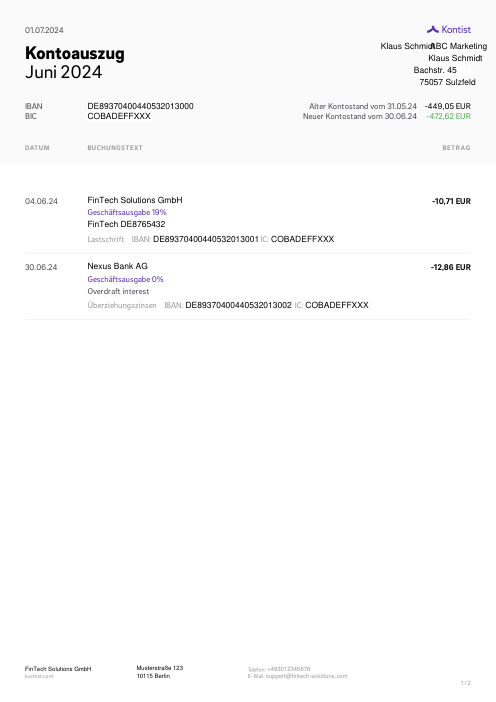
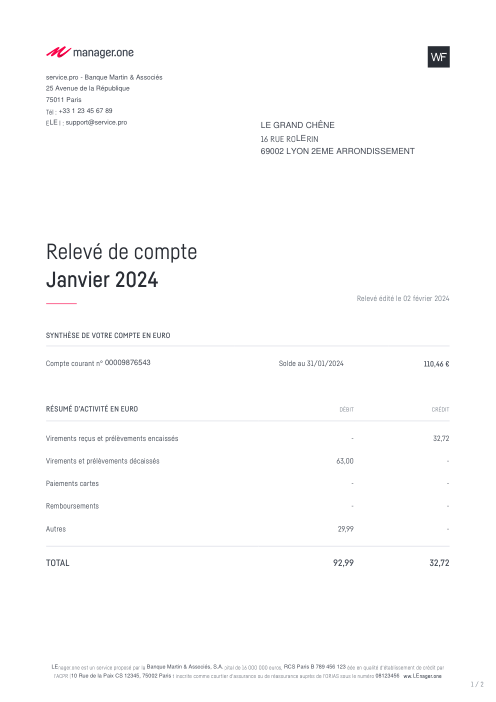
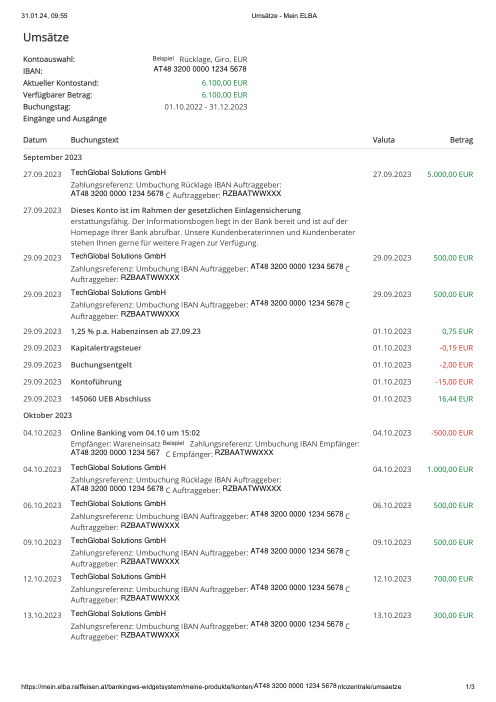
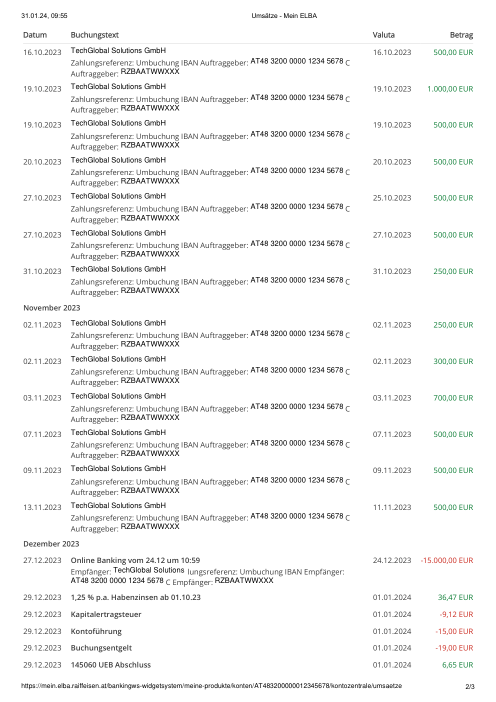
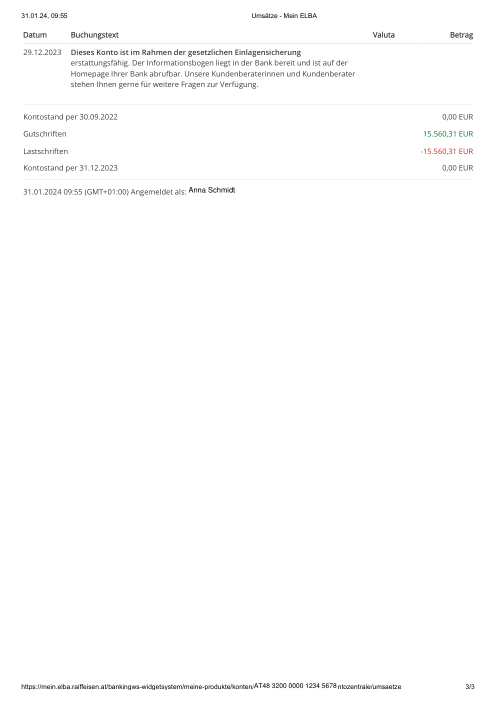
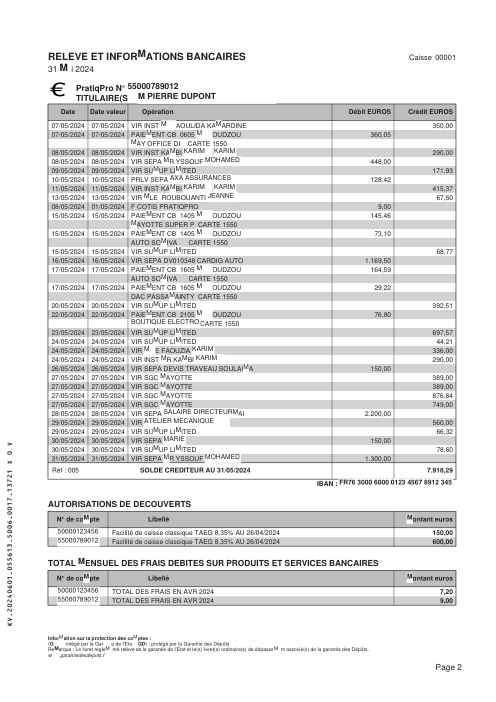
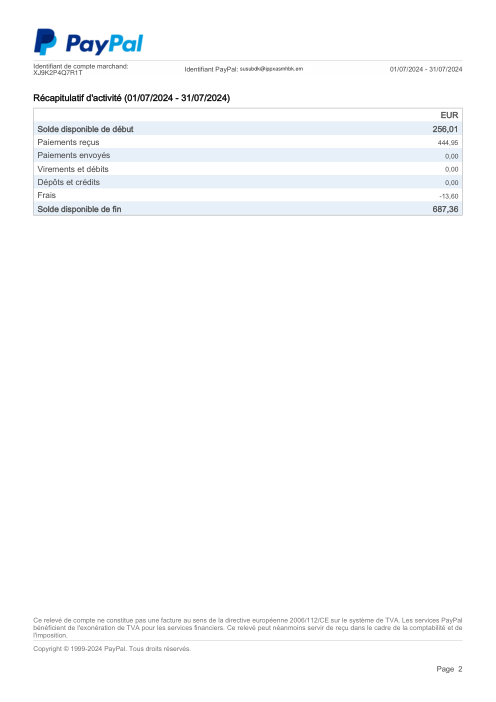
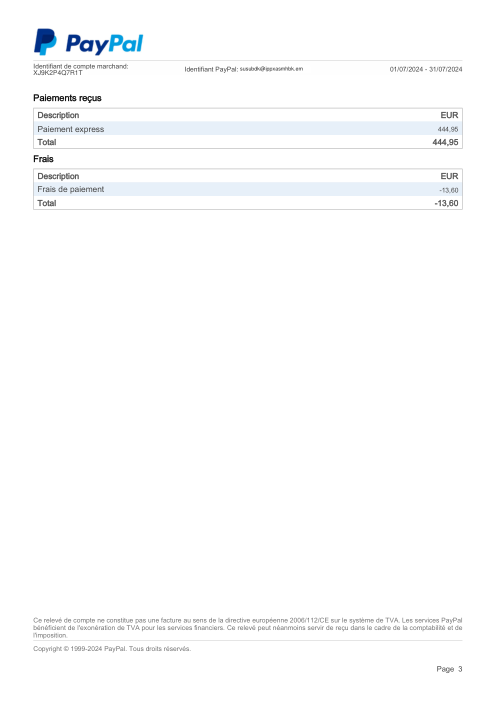
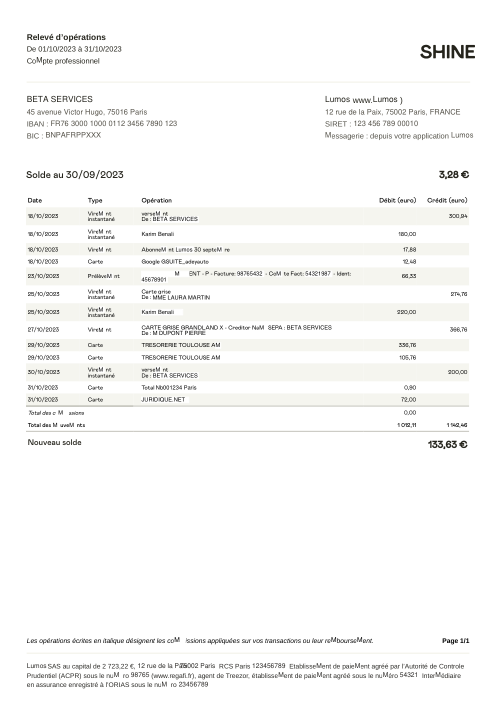
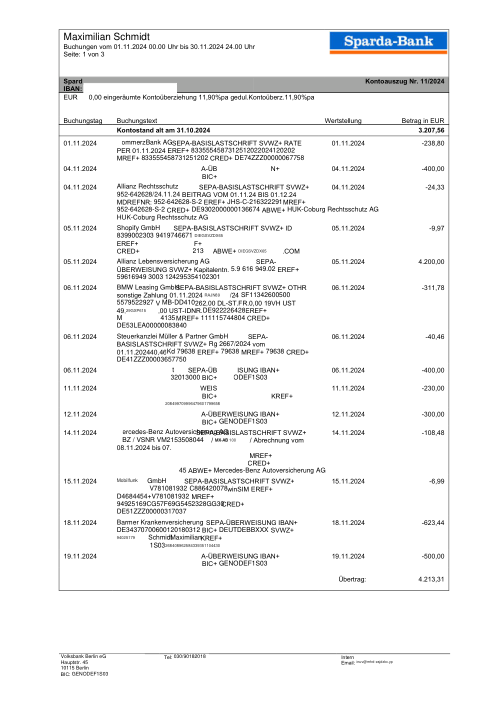
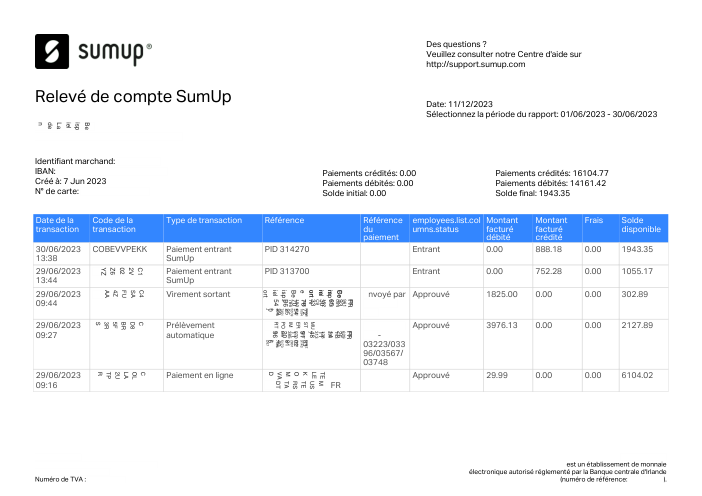
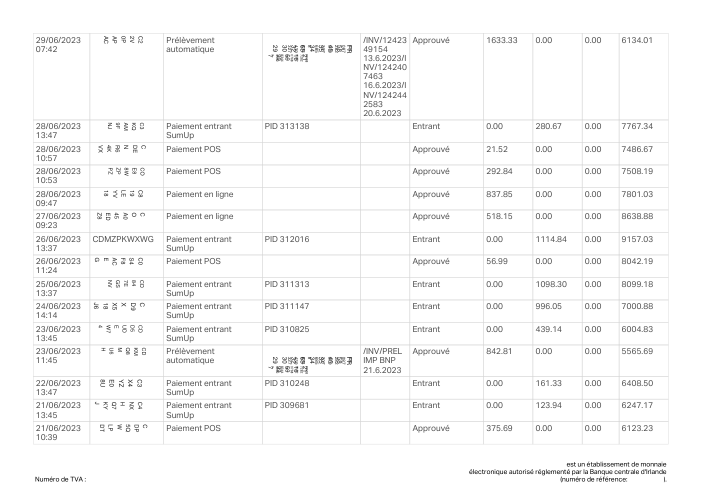
El dataset47 extractos reales, uno por banco
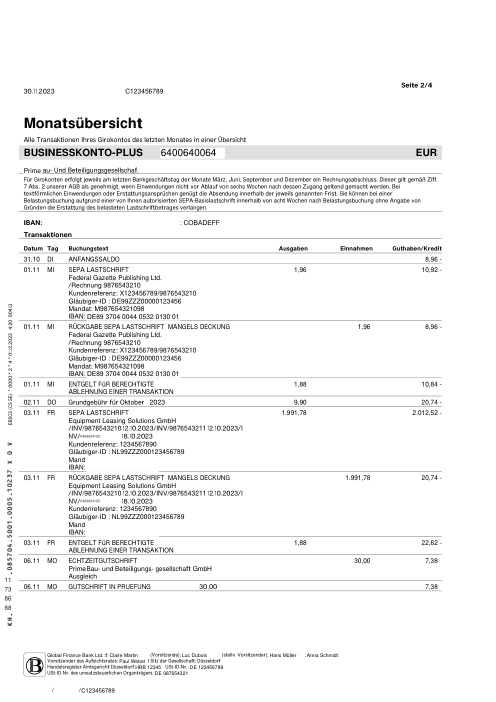
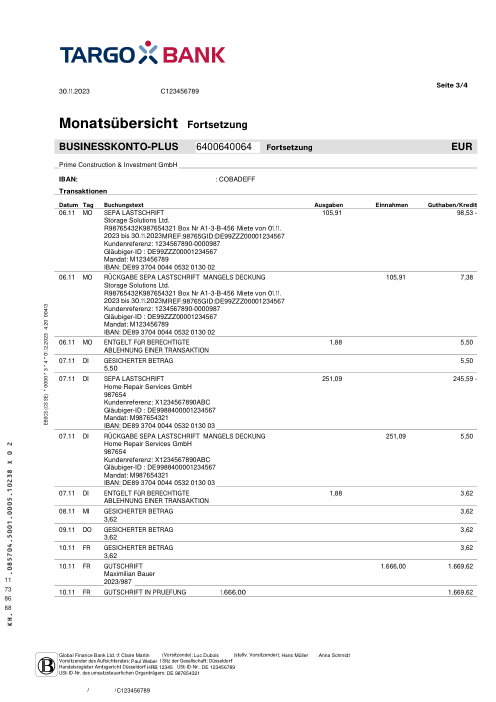
Cada extracto es real, luego anonimizado para que el diseño, las tablas y los totales sobrevivan, pero los nombres y números son sintéticos: grandes bancos franceses, bancos alemanes, neobancos y EMIs, cada uno con su propia idea de cómo debería ser una tabla de transacciones. Las etiquetas gold se verificaron a mano contra los PDFs de origen.
Cada extracto es real, luego anonimizado para que el diseño, las tablas y los totales sobrevivan pero los nombres y números son sintéticos. Haz clic en cualquier página para ampliar; cambia a Por banco para filtrar.











































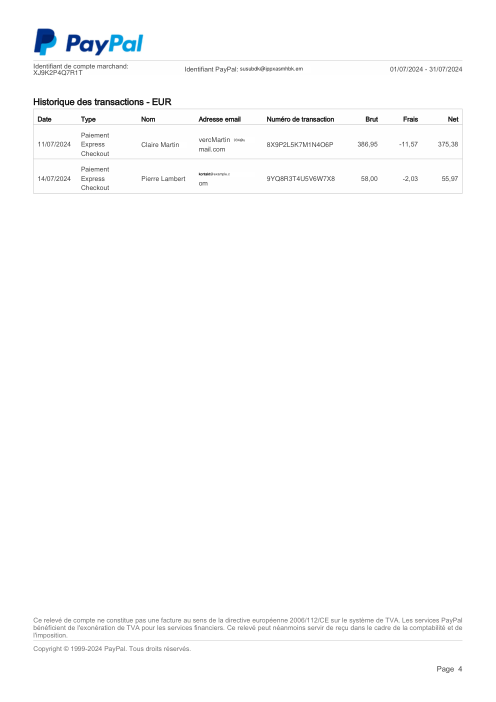


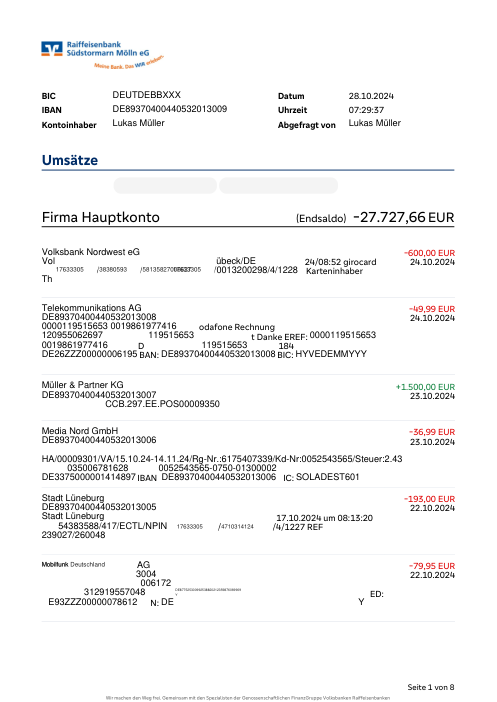


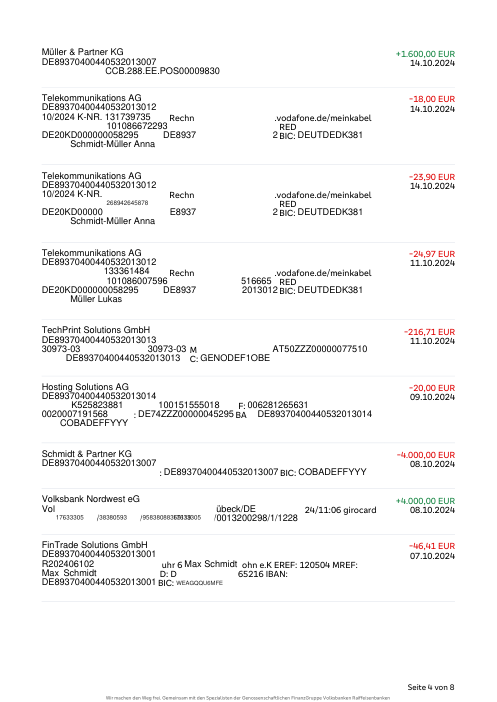


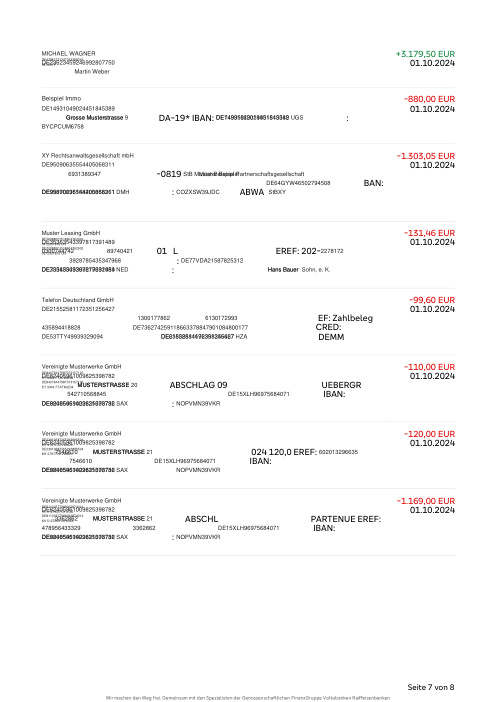











La precisión por fila es una métrica de vanidad
El número que le importa a un cliente no es "qué fracción de filas son correctas" sino "¿es correcto este extracto?". No son la misma métrica. Un extracto es correcto solo si cada fila lo es, por lo que una fila omitida o inventada hace fallar todo el documento.
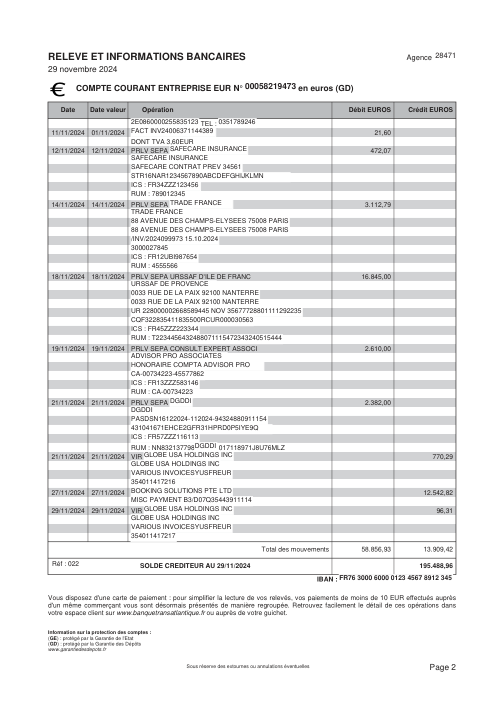
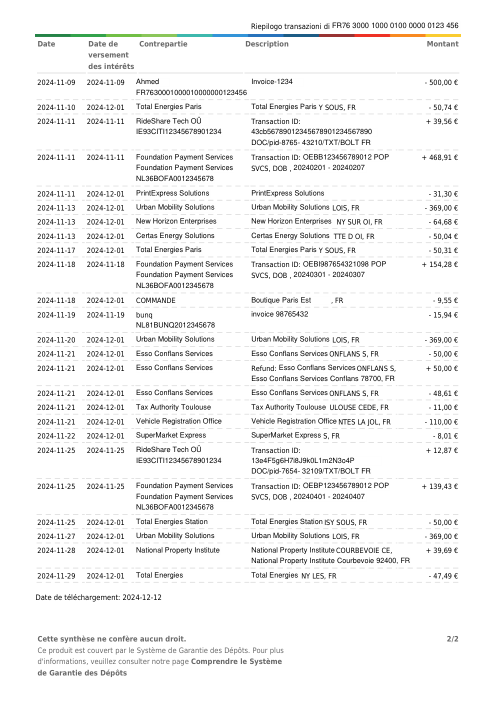
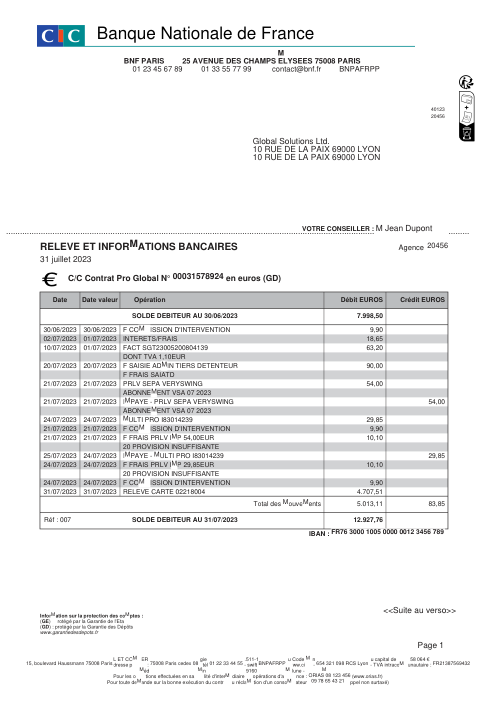
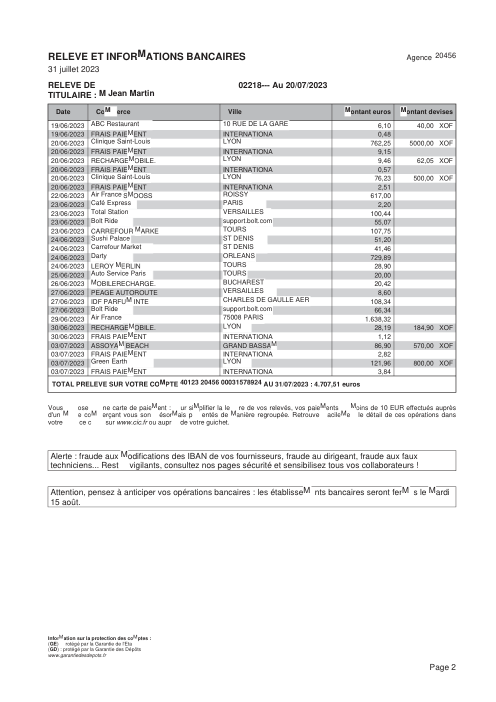
- Por extracto, no por fila. holofin extrae el 98% de los extractos con cero errores; el mejor modelo de frontera logra un 80%. En 44 documentos, holofin produjo una fila con error; los modelos de frontera produjeron 70–115 cada uno.
- La brecha es la invención, no la lectura. Todos los sistemas leen bien la página (recall 0.88–1.00). holofin inventa una fila en 44 extractos (0.1%); los modelos de frontera inventan el 8–10% de cada fila que devuelven.
- Una ventana más grande no es la solución. Pasar más páginas por llamada no sirve de nada; hacerlo por página es fiable porque limita la invención.
Lo que encontramos
Cuatro lecturas del mismo benchmark. La primera sitúa a cada sistema en completitud (¿encontró las filas?) frente a precisión (¿son reales las filas que devolvió?). El resto sigue la aritmética a partir de ahí.
Todos los sistemas encuentran las filas (completitud, x). Difieren en cuántas de las filas que devuelven existen realmente (precisión, y). holofin se sitúa en la esquina superior derecha; los modelos de frontera caen en el eje de precisión a medida que inventan. Modelos de frontera mostrados por página.
Un extracto es correcto solo si cada fila lo es. Porcentaje de extractos extraídos con cero errores (sin filas omitidas, sin filas inventadas) frente al gold verificado a mano. La sub-etiqueta es el total de filas con errores en los 44 documentos: holofin cometió uno; los modelos de frontera cometieron docenas.
Porcentaje de transacciones devueltas que no existen en la página. Una fila inventada cuadra con un balance incorrecto y parece plausible: el fallo silencioso. Modelos de frontera mostrados en su mejor configuración (por página).
holofin se ejecuta una página a la vez y lidera todos los ejes. Para los modelos de frontera, pasar más páginas por llamada no sirve de nada: el recall baja un poco, la precision sube un poco, dos páginas suele ser el punto óptimo. La brecha que importa es la que hay hasta la barra verde.
Sin agregados tras los que esconderse. Este es el recuento bruto de filas con errores (omitidas +
inventadas, vs gold) en cada extracto, por modelo, en la configuración por página. Lee la columna de holofin
de arriba a abajo: está vacía. · = limpio; números = errores en ese documento.
La destrucción silenciosa de la fila inventada
No es un fallo al leer la tinta en la página. Si una transacción está visiblemente impresa, todos los modelos la encuentran. El problema es lo que encuentran cuando la transacción no está ahí. Hay una diferencia operativa masiva entre una fila omitida y una inventada. Una fila omitida es molesta: el balance no cuadra y un operador detecta el hueco. Una fila inventada es un asesino silencioso. El modelo extrae un saldo acumulado, un subtotal o una fecha suelta y lo formatea como una transacción válida. Parece perfectamente plausible al hacerlo. Simplemente envenena la aritmética de forma lenta e invisible.
El gold es humano, no un modelo
No dejamos que un modelo evaluara a otros modelos. El ground truth se construyó a mano: en cada documento donde los sistemas discrepaban, una persona abría el PDF de origen y comprobaba las transacciones línea por línea. El benchmark puntúa frente a lo que está realmente impreso en la página, verificado por un humano, no frente a la opinión de otro modelo al respecto.
MetodologíaCómo está montado el benchmark
Los candidatos de frontera reciben imágenes de las páginas con un prompt de extracción genérico en tres tamaños de contexto. holofin es el pipeline de producción real (clasificar → OCR → extraer por página), operado a través de HTTP. Cada métrica es doc-macro: calculada por documento y luego promediada.
La comprobación obvia en producción es si las matemáticas de un extracto cuadran: saldo inicial + Σ transacciones = saldo final. Lo medimos, y es necesario pero no suficiente como métrica de verdad. Los extractos de GPT-5.5 cuadran 42/45 de las veces, y sin embargo sigue inventando ~8% de las filas frente a la página real; una fila inventada compensada por otro error sigue cuadrando, y un modelo que omite los saldos por completo (Gemini los dejó en blanco en 12 documentos) no se puede comprobar en absoluto. Un extracto puede pasar las matemáticas y seguir siendo incorrecto. Así que puntuamos cada transacción frente a un gold que fue verificado a mano contra el PDF de origen.
No necesitas una ventana más grande. Necesitas un arnés.
No resuelves la extracción pasando un PDF entero a un endpoint y pidiéndole a un modelo que tenga cuidado. En holofin esa es la descripción del trabajo. Construimos la jaula dentro de la cual corre la inteligencia:
- Estructura antes que semántica. El OCR determinista y la geometría construyen primero el contexto de la página. Los prompts capturan bien el significado y mal la estructura visual.
- Limitar el problema. Procesamos estrictamente por página, nunca pidiéndole a un modelo que mantenga un libro mayor entero en la memoria de trabajo.
- Restricciones > intuición. Reglas contables estrictas deciden qué cuenta como una transacción antes de que un resultado se finalice.
Una vez que has escrito suficiente andamiaje para estar seguro (la redundancia del OCR, la geometría delimitadora, los parsers estrictos, las conciliaciones), el modelo ya no es el héroe. Es el especialista al que llamas para disputas y casos límite. El trabajo no es eliminar las partes aburridas; es construir cosas aburridas para que la magia tenga algo sólido sobre lo que sostenerse.
Artículos relacionados

Tu extractor de tablas aprobó. Los números no.
Una auditora abre el resultado de tu extracción de un balance general. El modelo reporta una precisión de celdas del 99.2%. Impresionante. Luego, suma la columna de activos a mano, como hacen los auditores, y el resultado es un número desfasado por una fila. Los activos ya no equivalen a los pasivos más el patrimonio. El estado financiero no cuadra.

Detección de fraude documental: Lo que un PDF no puede ocultar
Solíamos pensar que el fraude documental era un problema visual. Fuentes incorrectas. Columnas desalineadas. Un logotipo que se sentía ligeramente incorrecto. Construimos controles en torno a lo que ven los humanos, porque lo que ven los humanos era todo lo que teníamos.

Cuando los documentos contraatacan
Página 1: Resumen de cuenta, dos columnas. Página 15: Misma cuenta, tres columnas, nombres de encabezado diferentes. Página 47: Un escaneo con una mancha de café. Página 89: La página de totales, que hace referencia a transacciones que extrajiste hace 70 páginas.