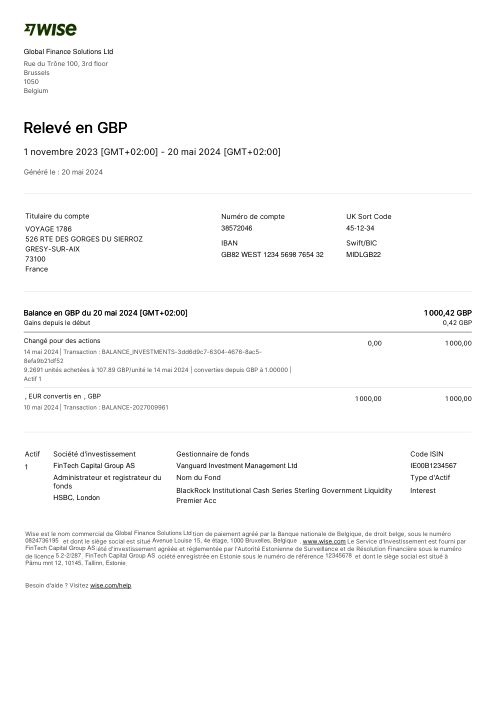
In holofin, l'estrazione degli estratti conto è una delle nostre attività principali e la eseguiamo in produzione. Istituti di credito, contabili e team finanziari ci consegnano estratti conto di centinaia di banche diverse e si aspettano di ricevere indietro ogni transazione, esattamente, senza nulla di inventato e nulla di omesso.
L'estrazione si trova all'inizio di questa pipeline, quindi i suoi errori non rimangono mai isolati. Una riga mancante o inventata non toglie semplicemente un punto al punteggio di accuratezza. Diventa un saldo che non quadra, una decisione di solvibilità basata su un numero che non è mai stato sulla pagina, un libro mastro di cui nessuno a valle può fidarsi. Un estratto conto è booleano: o è completamente corretto, o è una passività.
Quindi volevamo sapere con quanta affidabilità i migliori modelli di oggi svolgano effettivamente questo compito, non su una demo selezionata ad hoc, ma su estratti conto reali, valutati nel modo in cui li valuta un team finanziario, dove l'unica cosa che conta è se l'intero estratto conto regge. Abbiamo costruito un benchmark per scoprirlo.
Il dataset47 estratti conto reali, uno per banca
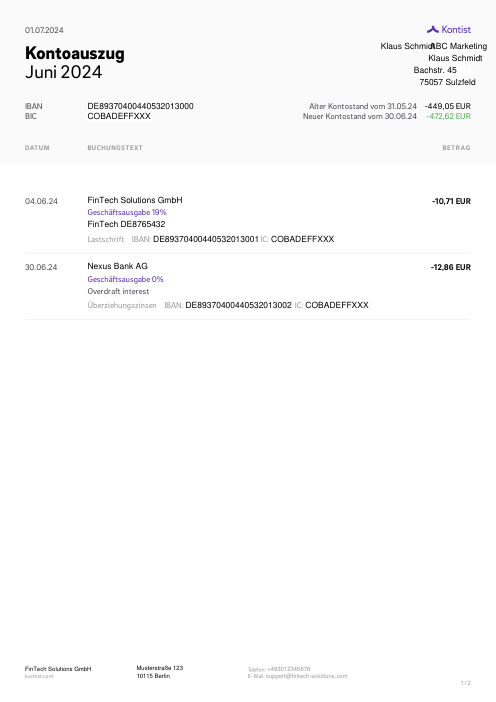
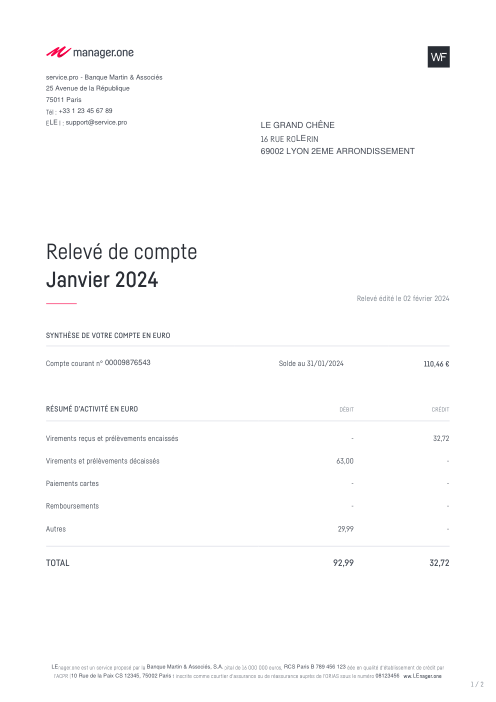
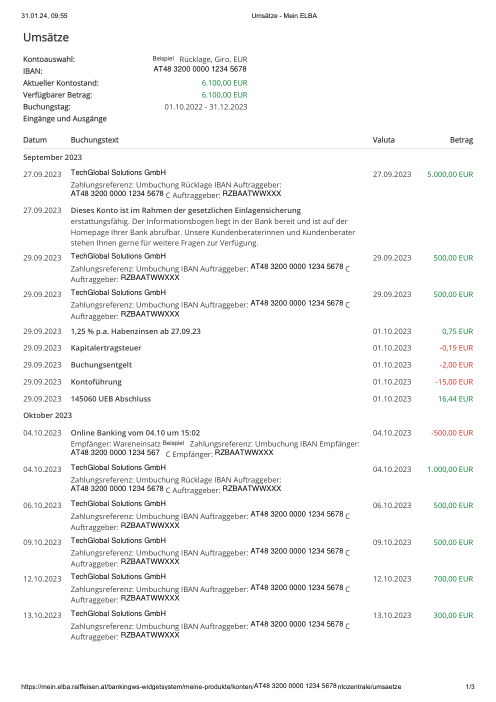
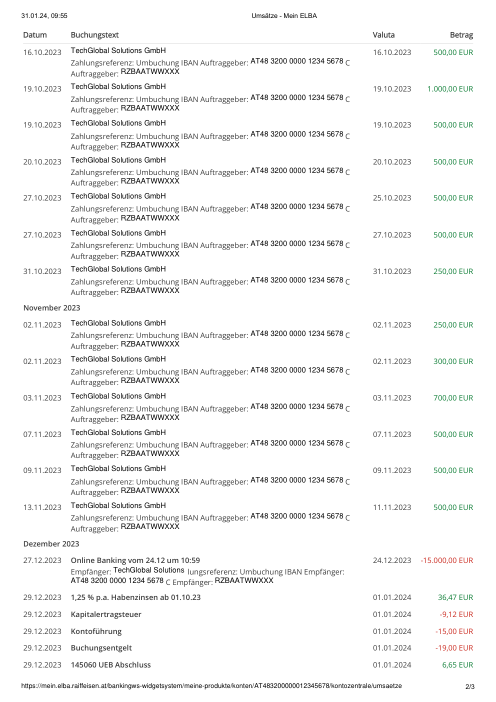
Ogni estratto conto è reale, poi anonimizzato in modo che layout, tabelle e totali sopravvivano, ma i nomi e i numeri siano sintetici: grandi banche francesi, banche tedesche, neobanche ed EMI, ognuna con la propria idea di come dovrebbe apparire una tabella delle transazioni. Le etichette gold sono state verificate a mano rispetto ai PDF originali.
Ogni estratto conto è reale, poi anonimizzato in modo che layout, tabelle e totali sopravvivano ma nomi e numeri siano sintetici. Clicca su qualsiasi pagina per ingrandire; passa a Per banca per filtrare.
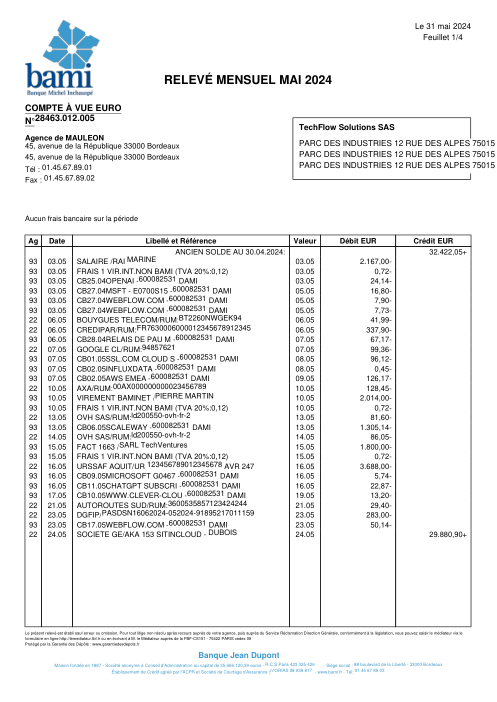
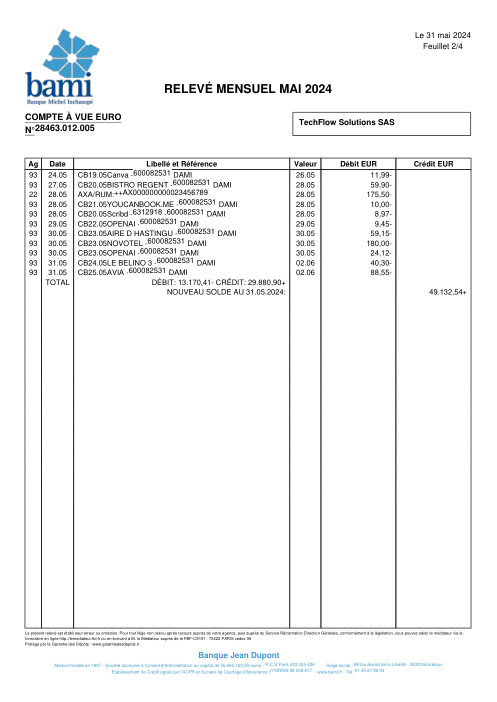
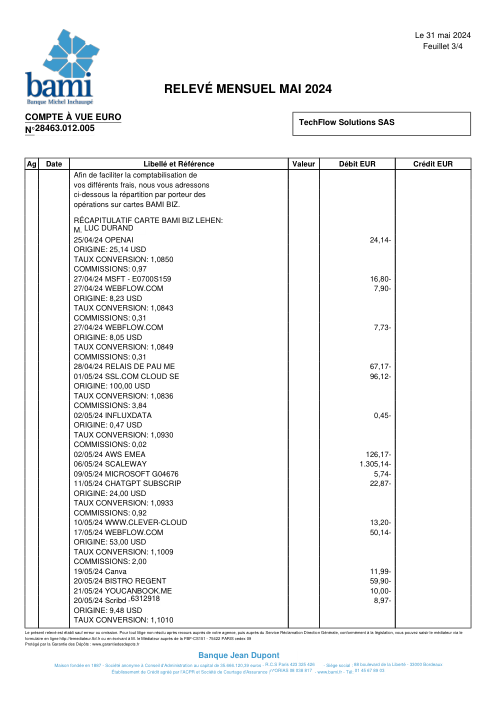


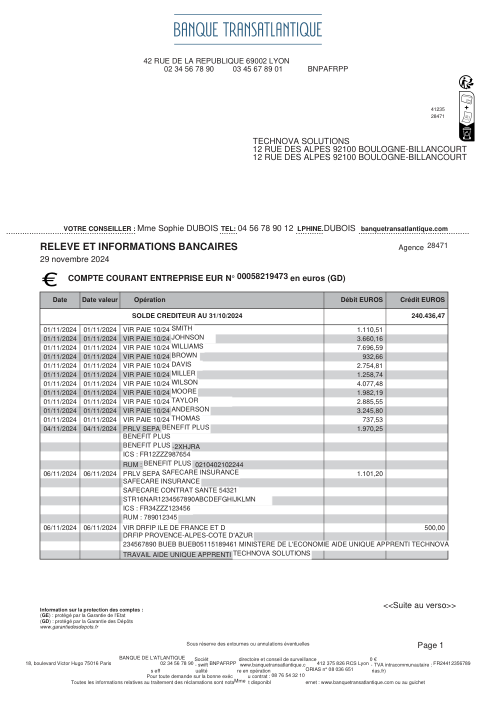
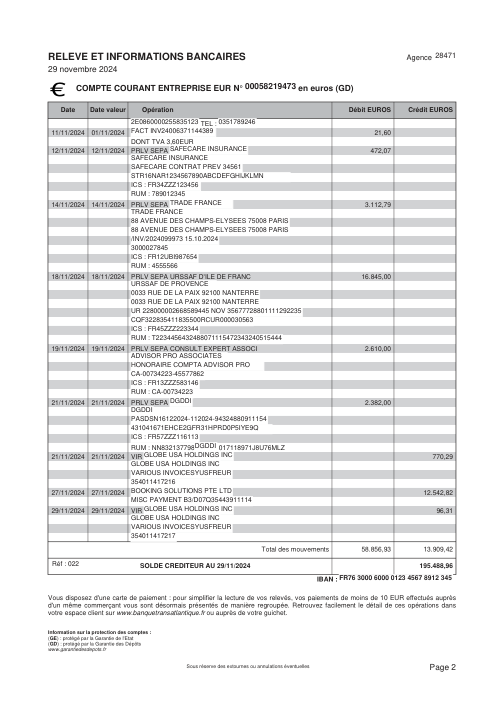







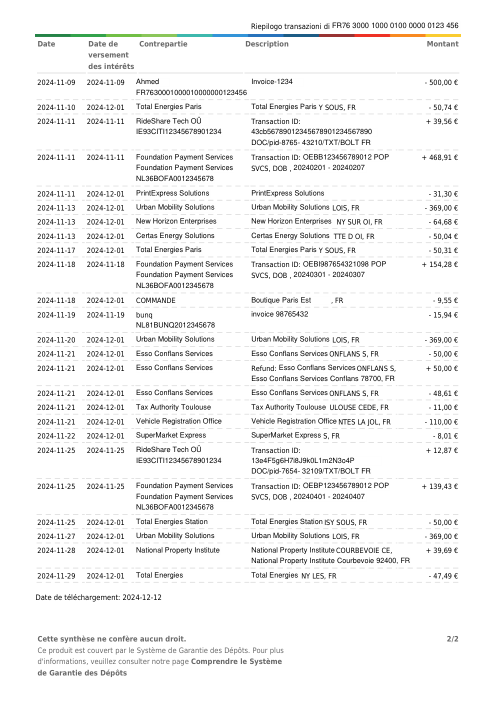









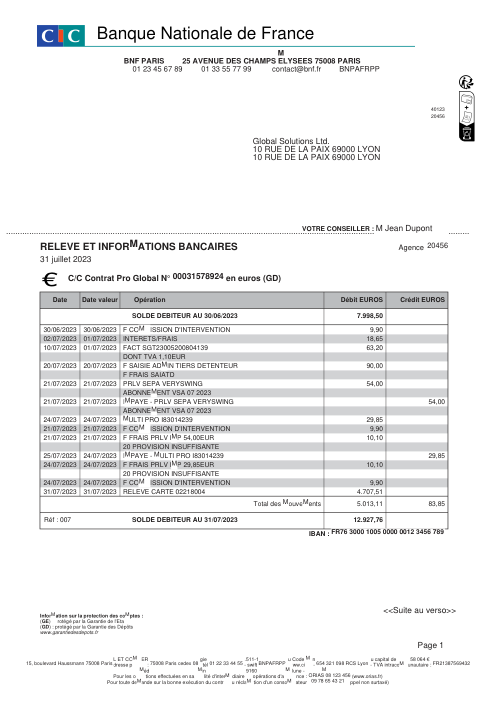
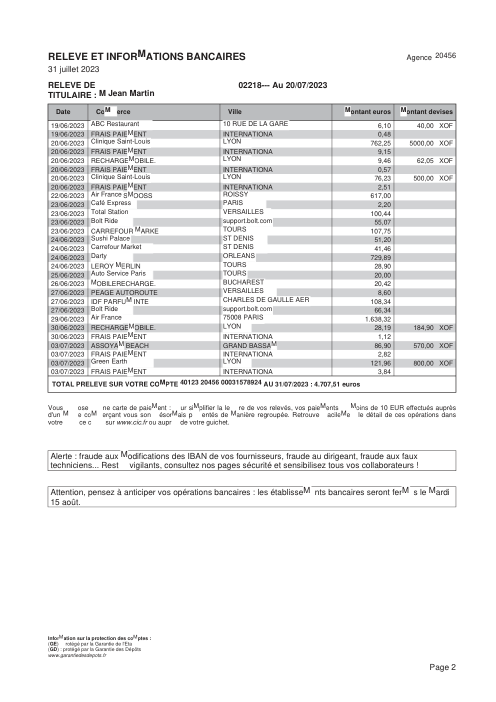





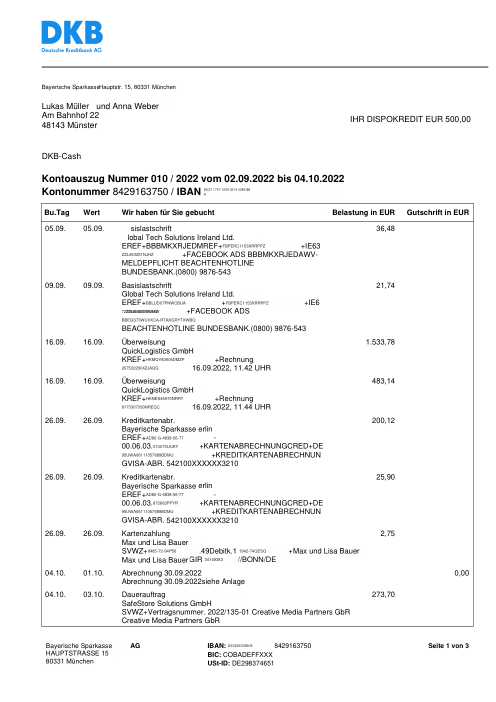


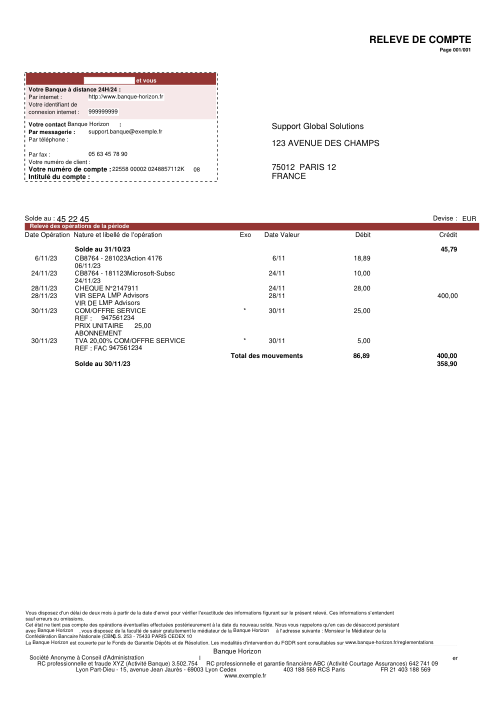








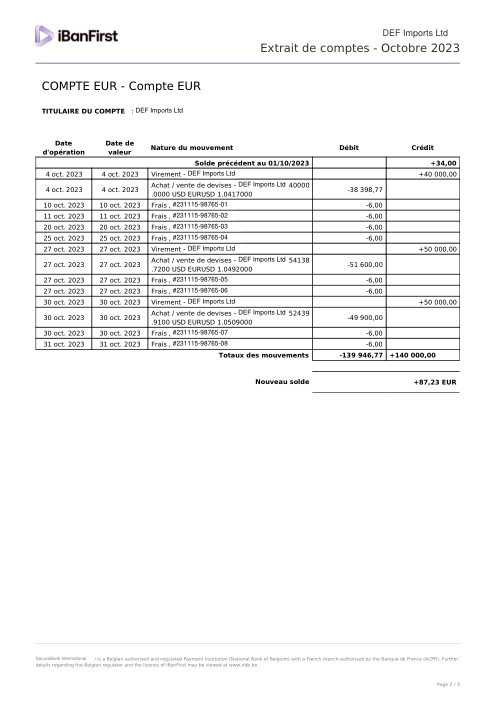
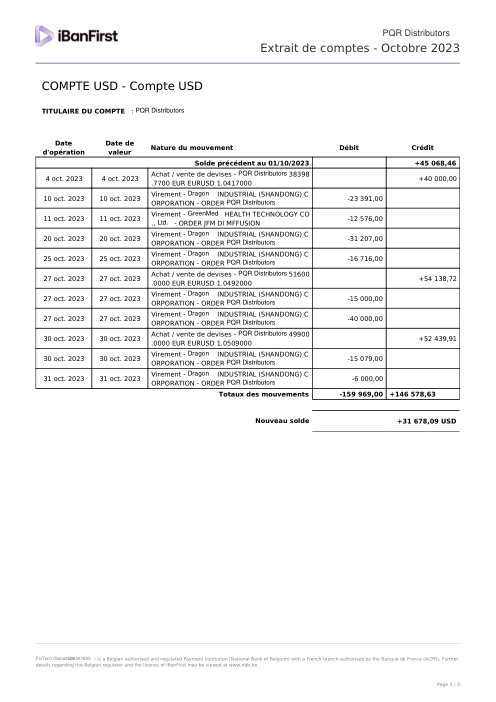






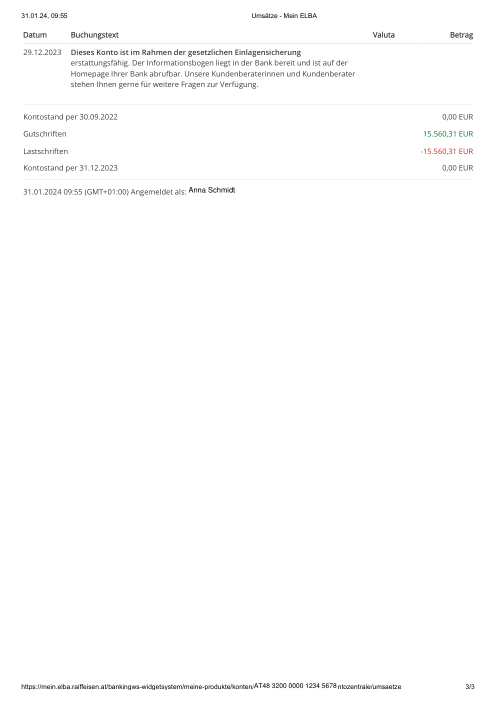


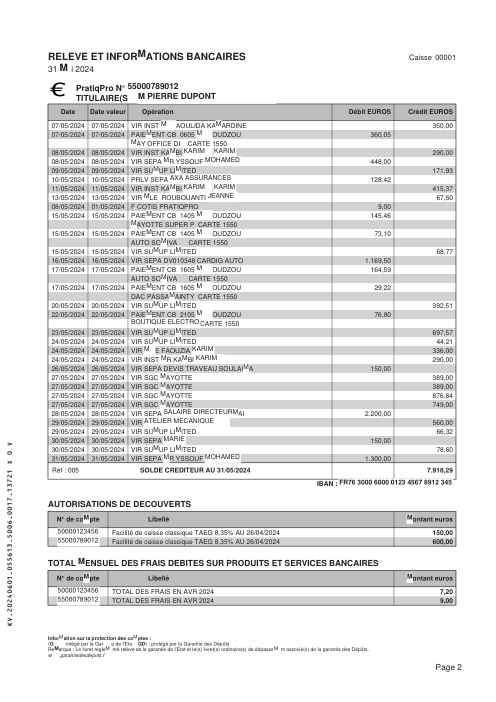


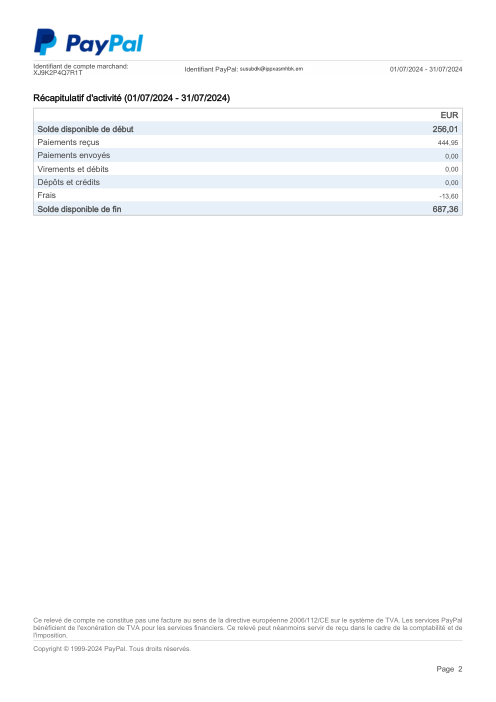
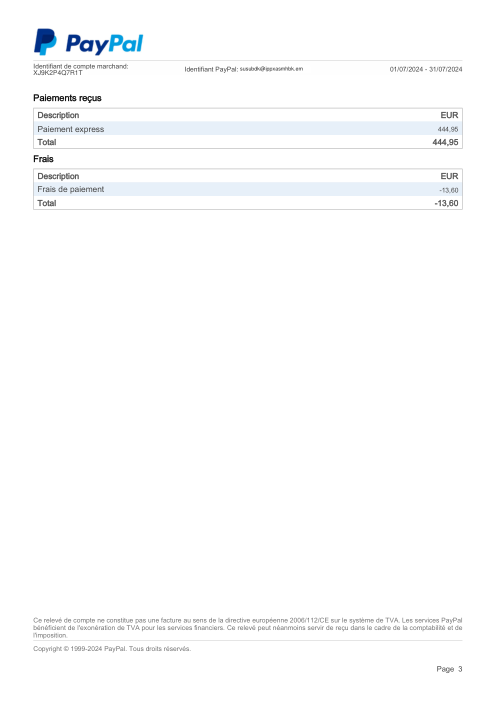
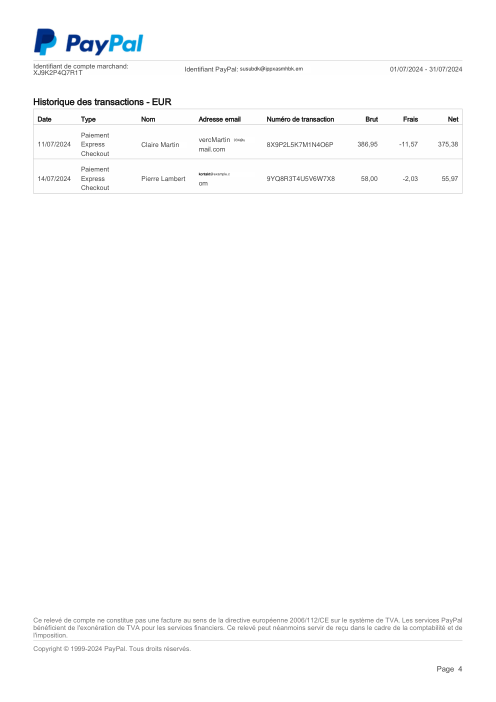


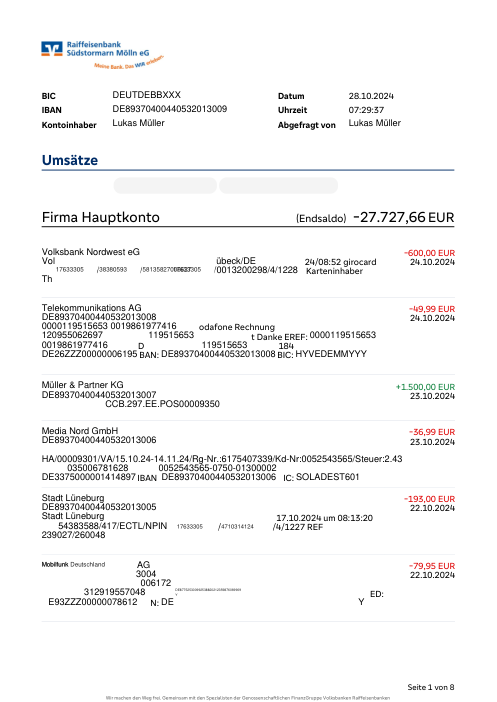


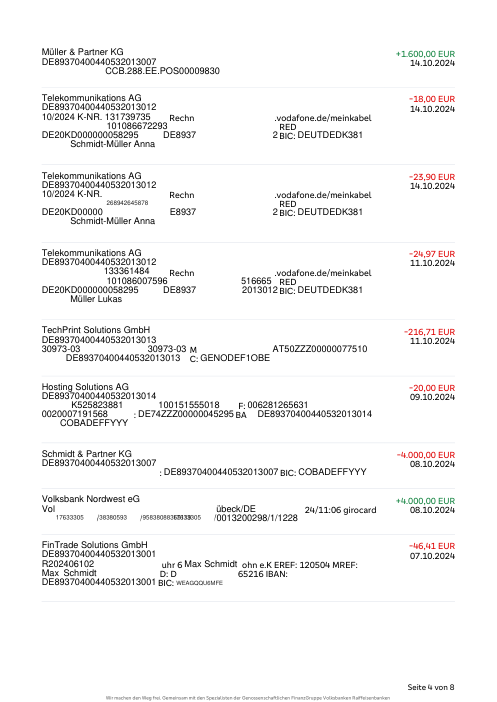


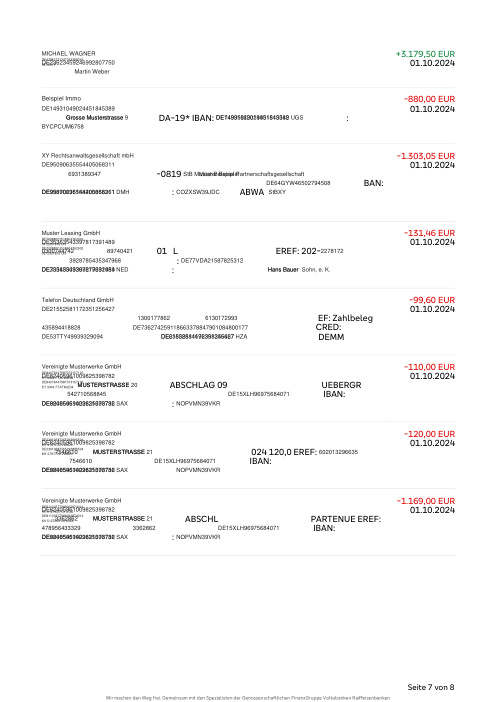





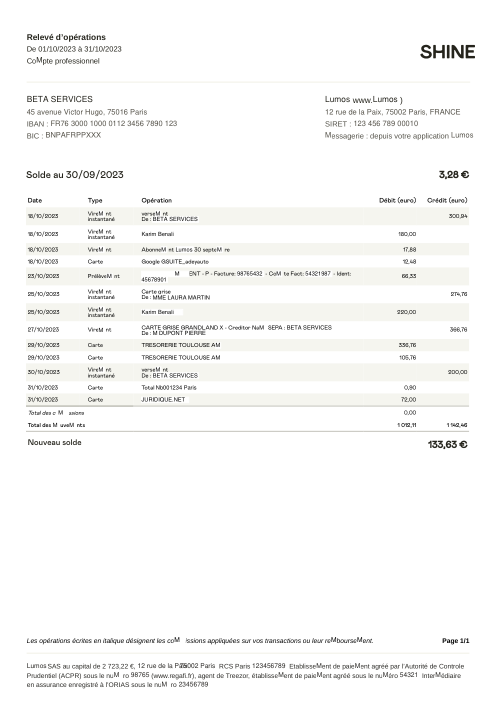
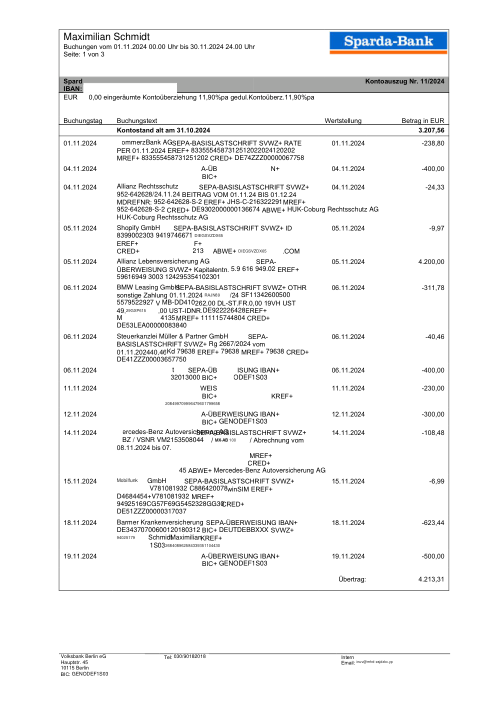


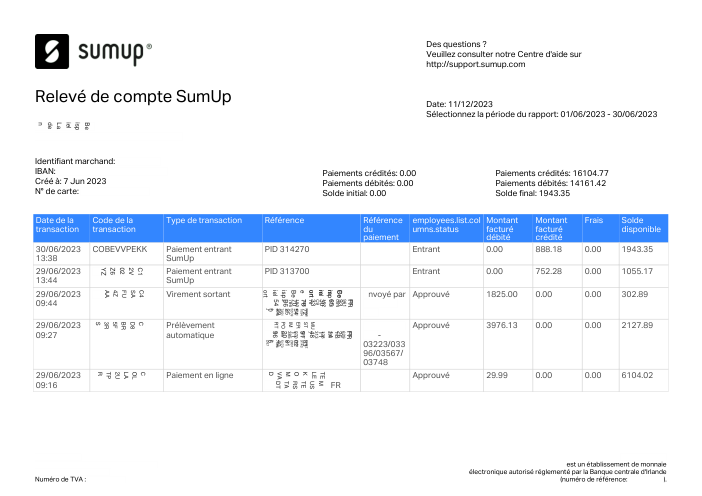
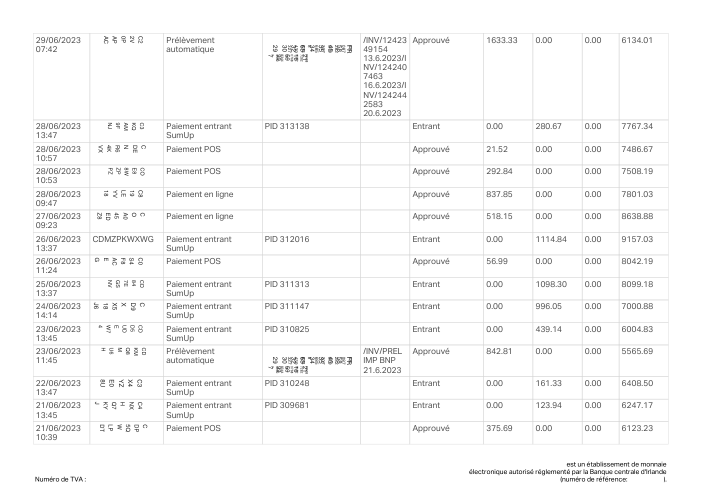
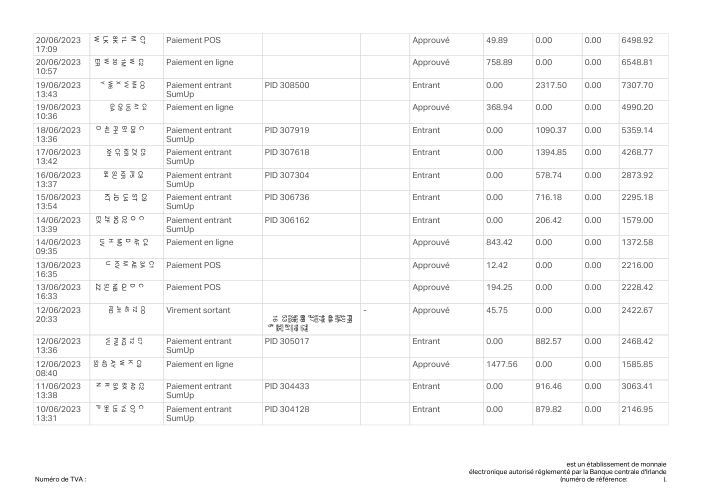
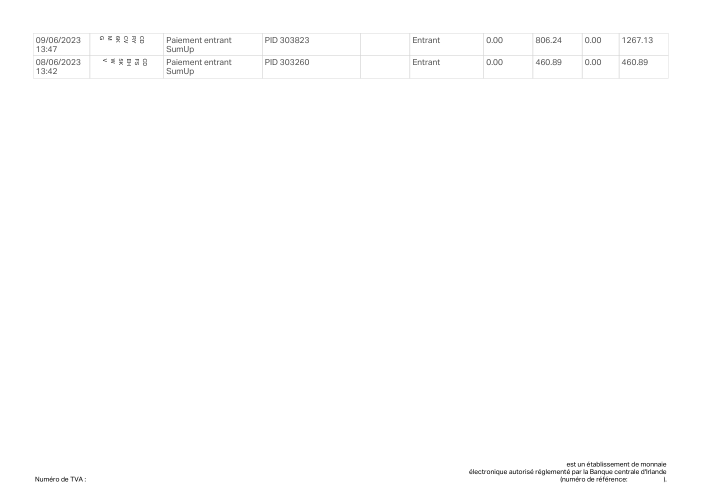

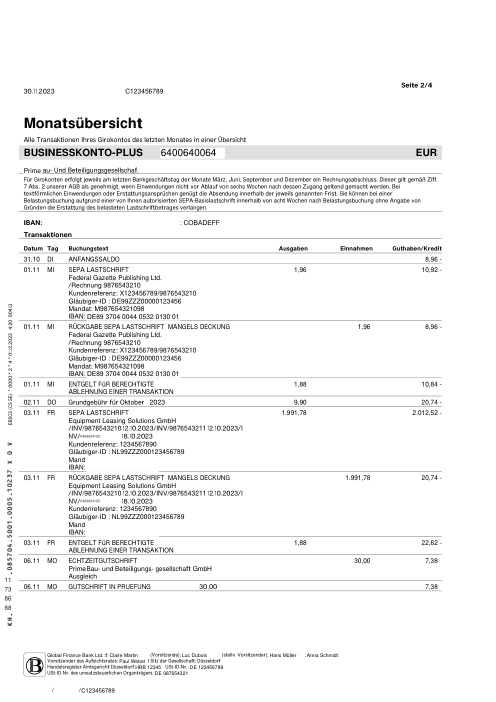
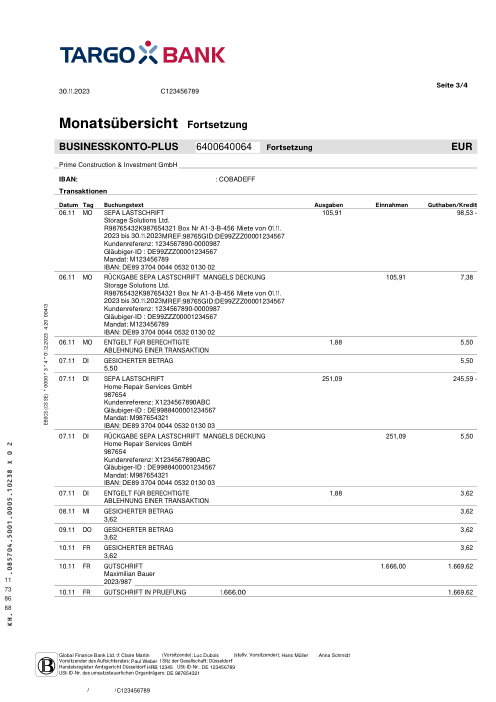



L'accuratezza per riga è una vanity metric
Il numero che conta per un cliente non è "quale frazione di righe è corretta" ma "questo estratto conto è corretto". Non sono la stessa metrica. Un estratto conto è corretto solo se ogni riga lo è, quindi una riga mancata o inventata fa fallire l'intero documento.
- Per estratto conto, non per riga. holofin estrae il 98% degli estratti conto con zero errori; il miglior modello di frontiera arriva all'80%. Su 44 documenti holofin ha prodotto una riga errata; i modelli di frontiera ne hanno prodotte 70–115 ciascuno.
- Il divario è l'invenzione, non la lettura. Ogni sistema legge bene la pagina (recall 0.88–1.00). holofin inventa una riga su 44 estratti conto (0.1%); i modelli di frontiera inventano l'8–10% di ogni riga che restituiscono.
- Una finestra più ampia non è la soluzione. Fornire più pagine per chiamata è inutile; l'approccio per pagina è affidabile perché limita le invenzioni.
Cosa abbiamo scoperto
Quattro letture dello stesso benchmark. La prima posiziona ogni sistema in base alla completezza (ha trovato le righe?) rispetto all'accuratezza (le righe restituite sono reali?). Il resto segue l'aritmetica da lì.
Ogni sistema trova le righe (completezza, x). Differiscono su quante delle righe restituite esistano realmente (accuratezza, y). holofin si trova nell'angolo in alto a destra; i modelli di frontiera scendono lungo l'asse dell'accuratezza man mano che inventano. Modelli di frontiera mostrati per pagina.
Un estratto conto è corretto solo se ogni riga lo è. Percentuale di estratti conto estratti con zero errori (nessuna riga omessa, nessuna riga inventata) rispetto al gold verificato a mano. La sotto-etichetta indica le righe errate totali su tutti i 44 documenti: holofin ne ha prodotta una; i modelli di frontiera ne hanno prodotte a dozzine.
Percentuale di transazioni restituite che non esistono sulla pagina. Una riga inventata porta a un saldo errato e sembra plausibile: il fallimento silenzioso. Modelli di frontiera mostrati nella loro impostazione migliore (per pagina).
holofin elabora una pagina alla volta e domina ogni asse. Per i modelli di frontiera, fornire più pagine per chiamata è inutile: la recall scende leggermente, la precision sale leggermente, due pagine sono spesso il punto di equilibrio. Il divario che conta è quello rispetto alla barra verde.
Nessun aggregato dietro cui nascondersi. Questo è il conteggio grezzo delle righe errate (omesse + inventate, rispetto al gold) su ogni estratto conto, per modello, con l'impostazione per pagina. Leggi la colonna di holofin dall'alto verso il basso: è vuota. · = pulito; numeri = errori su quel documento.
La distruzione silenziosa della riga inventata
Non è un'incapacità di leggere l'inchiostro sulla pagina. Se una transazione è visibilmente stampata, ogni modello la trova. Il problema è cosa trovano quando la transazione non c'è. C'è un'enorme differenza operativa tra una riga omessa e una inventata. Una riga omessa è fastidiosa: il saldo non quadra e un operatore nota il buco. Una riga inventata è un killer silenzioso. Il modello estrae un saldo parziale, un subtotale o una data isolata e li formatta come una transazione valida. Sembra perfettamente plausibile mentre lo fa. Semplicemente avvelena lentamente e invisibilmente l'aritmetica.
Il gold è umano, non un modello
Non abbiamo lasciato che un modello valutasse altri modelli. La ground truth è stata costruita a mano: su ogni documento in cui i sistemi erano in disaccordo, una persona ha aperto il PDF originale e ha controllato le transazioni riga per riga. Il benchmark valuta rispetto a ciò che è effettivamente stampato sulla pagina, verificato da un essere umano, non rispetto all'opinione di un altro modello.
MetodologiaCome è strutturato il benchmark
I candidati di frontiera ricevono immagini delle pagine con un prompt di estrazione generico a tre dimensioni di contesto. holofin è la vera pipeline di produzione (classificazione → OCR → estrazione per pagina), guidata tramite HTTP. Ogni metrica è doc-macro: calcolata per documento, poi mediata.
L'ovvio controllo in produzione è se la matematica di un estratto conto quadra: saldo iniziale + Σ transazioni = saldo finale. Lo abbiamo misurato, ed è necessario ma non sufficiente come metrica di verità. Gli estratti conto di GPT-5.5 quadrano 42 volte su 45, eppure inventa ancora circa l'8% delle righe rispetto alla pagina reale; una riga inventata compensata da un altro errore fa comunque quadrare i conti, e un modello che omette del tutto i saldi (Gemini li ha lasciati in bianco su 12 documenti) non può essere controllato affatto. Un estratto conto può superare il test matematico ed essere comunque sbagliato. Quindi valutiamo ogni transazione rispetto al gold che è stato verificato a mano sul PDF originale.
Non ti serve una finestra più grande. Ti serve un'impalcatura.
Non risolvi l'estrazione passando un intero PDF a un endpoint e chiedendo a un modello di fare attenzione. In holofin questa è la descrizione del lavoro. Costruiamo la gabbia all'interno della quale corre l'intelligenza:
- Struttura prima della semantica. L'OCR deterministico e la geometria costruiscono prima il contesto della pagina. I prompt catturano bene il significato e male la struttura visiva.
- Delimitare il problema. Elaboriamo rigorosamente per pagina, senza mai chiedere a un modello di mantenere un intero libro mastro nella memoria di lavoro.
- Vincoli > sensazioni. Rigide regole contabili decidono cosa conta come transazione prima che un risultato venga mai finalizzato.
Una volta scritta un'impalcatura sufficiente per essere al sicuro (la ridondanza dell'OCR, la geometria di delimitazione, i parser rigorosi, le riconciliazioni), il modello non è più l'eroe. È lo specialista che chiami per le dispute e i casi limite. Il lavoro non è eliminare le parti noiose; è costruire cose noiose in modo che la magia abbia qualcosa di solido su cui poggiare.
Articoli correlati

Il tuo estrattore di tabelle ha superato il test. I numeri no.
Una revisore apre il tuo risultato di estrazione per uno stato patrimoniale. Il modello mostra una precisione per cella del 99,2%. Impressionante. Poi calcola il totale della colonna delle attività a mano, come fanno i revisori, e ottiene un numero sfasato di una riga. Le attività non sono più uguali alle passività più il patrimonio netto. Il bilancio non quadra.

Rilevamento frodi documentali: Cosa un PDF non può nascondere
Pensavamo che la frode documentale fosse un problema visivo. Font sbagliati. Colonne disallineate. Un logo che sembrava leggermente fuori posto. Abbiamo costruito controlli basati su ciò che gli umani vedono, perché ciò che gli umani vedono era tutto ciò che avevamo.

Quando i documenti si ribellano
Pagina 1: Riepilogo conto, due colonne. Pagina 15: Stesso conto, tre colonne, nomi delle intestazioni diversi. Pagina 47: Una scansione con una macchia di caffè. Pagina 89: La pagina dei totali, che fa riferimento a transazioni estratte 70 pagine fa.