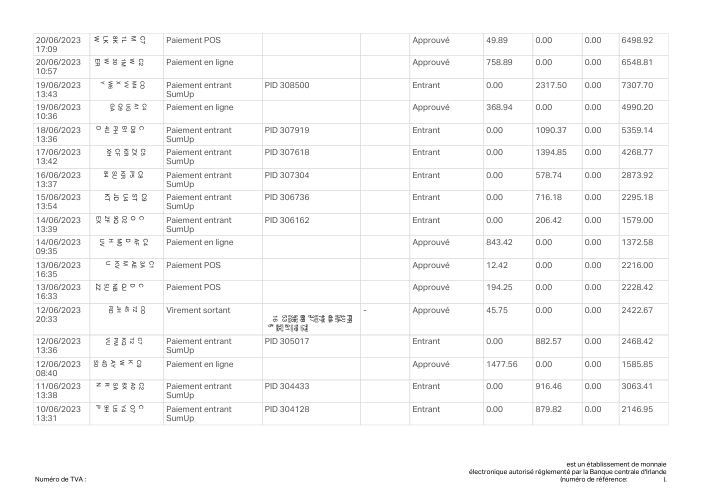
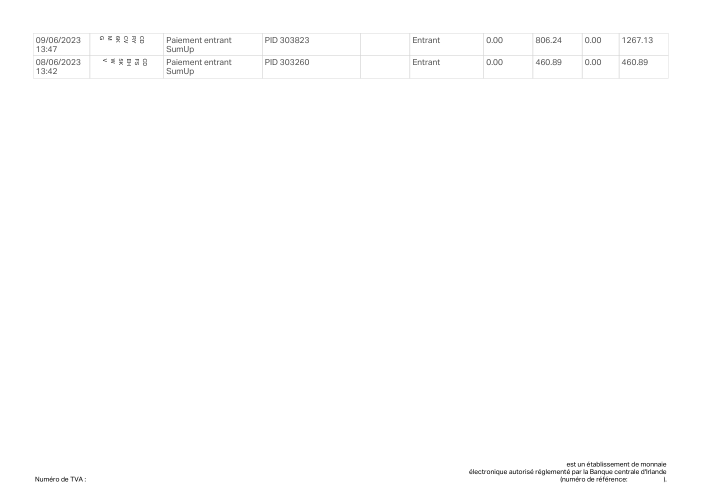
Chez holofin, l'extraction de relevés bancaires est l'un de nos cœurs de métier, et nous la faisons tourner en production. Les prêteurs, les comptables et les équipes financières nous confient des relevés provenant de centaines de banques différentes et s'attendent à récupérer chaque transaction, exactement, sans rien inventer ni omettre.
L'extraction se situe tout au début de cette pipeline, ses erreurs ne restent donc jamais isolées. Une ligne manquante ou inventée ne fait pas que amputer un score de précision d'un point. Elle devient un solde impossible à rapprocher, une décision de solvabilité basée sur un chiffre qui n'a jamais figuré sur la page, un grand livre auquel personne en aval ne peut se fier. Un relevé bancaire est booléen : soit il est entièrement correct, soit c'est un risque.
Nous voulions donc savoir avec quelle fiabilité les meilleurs modèles actuels accomplissent réellement cette tâche, non pas sur une démo triée sur le volet, mais sur de vrais relevés, évalués de la même manière qu'une équipe financière les évalue, où la seule chose qui compte est de savoir si l'ensemble du relevé tient la route. Nous avons construit un benchmark pour le découvrir.
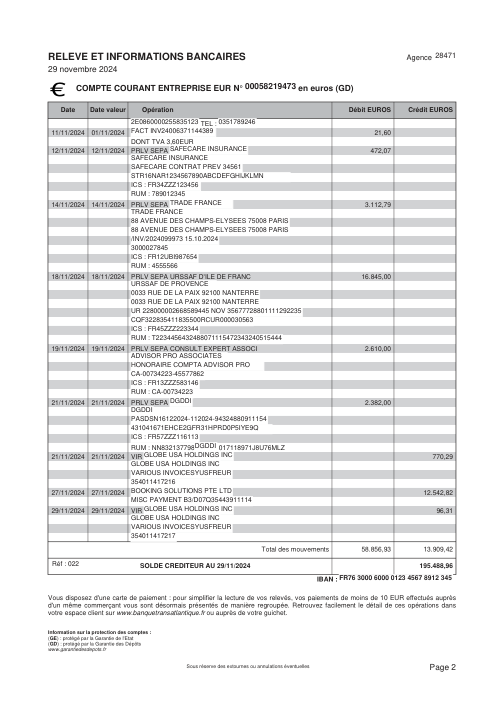
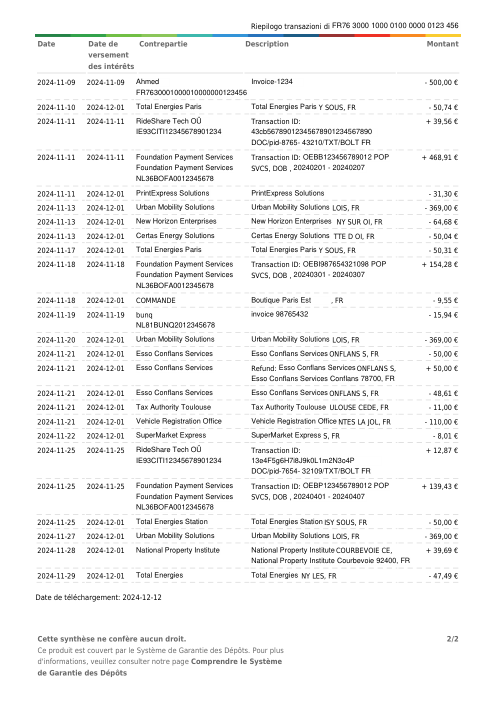
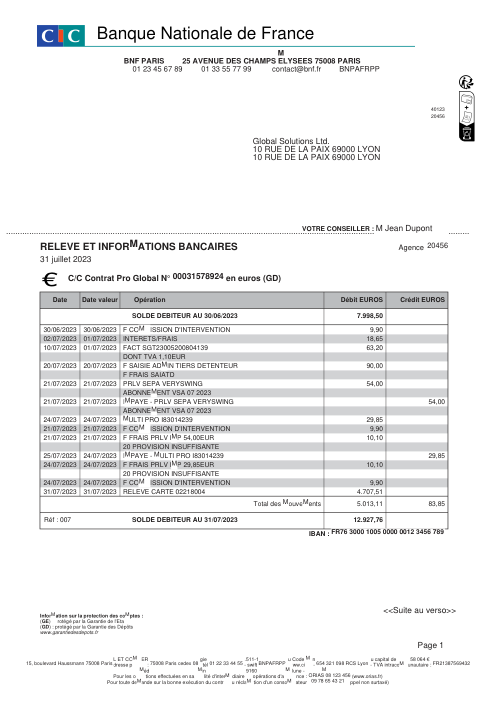
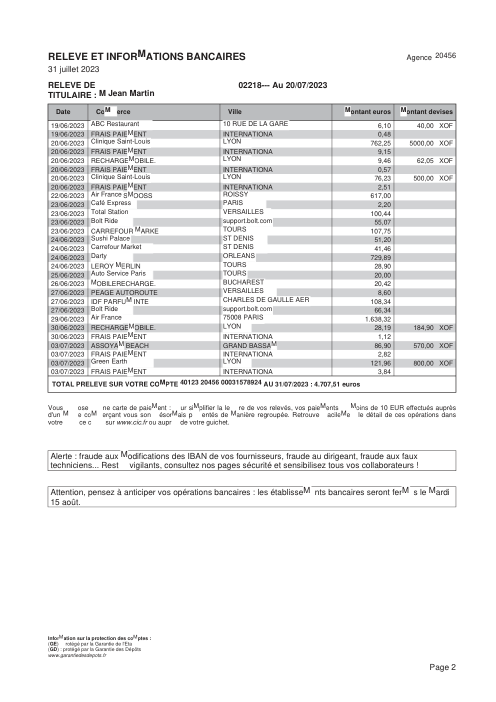
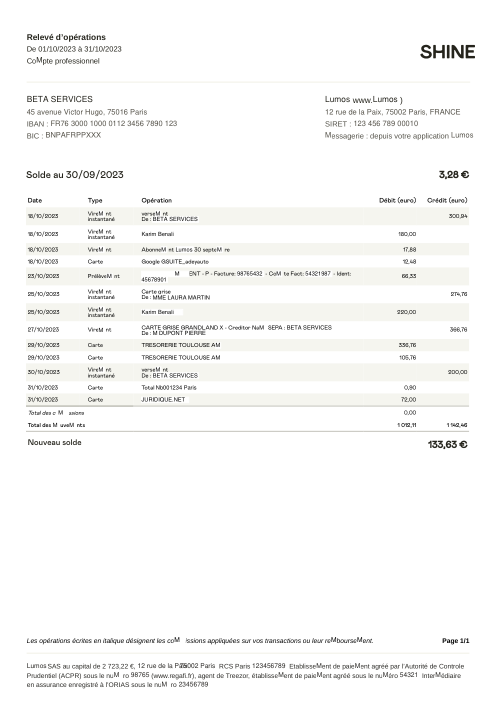
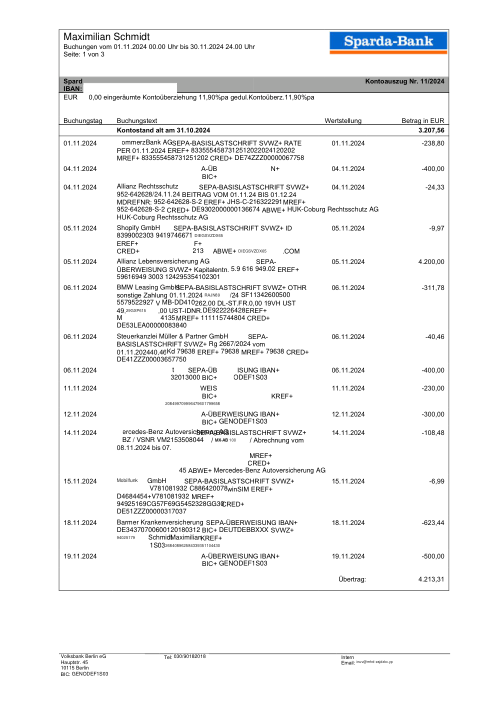
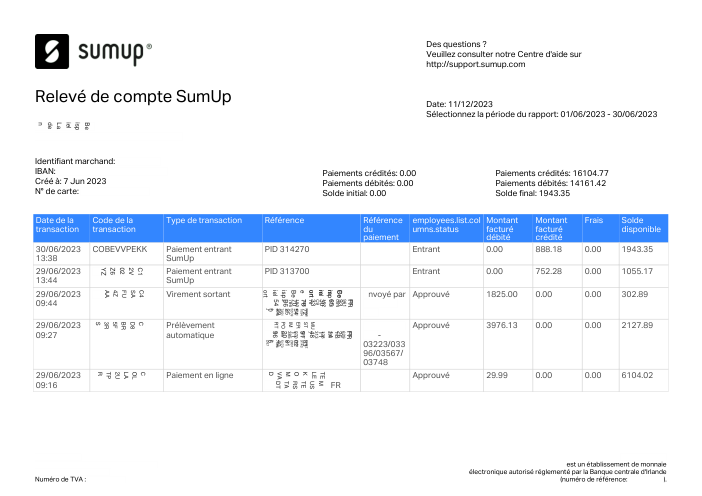
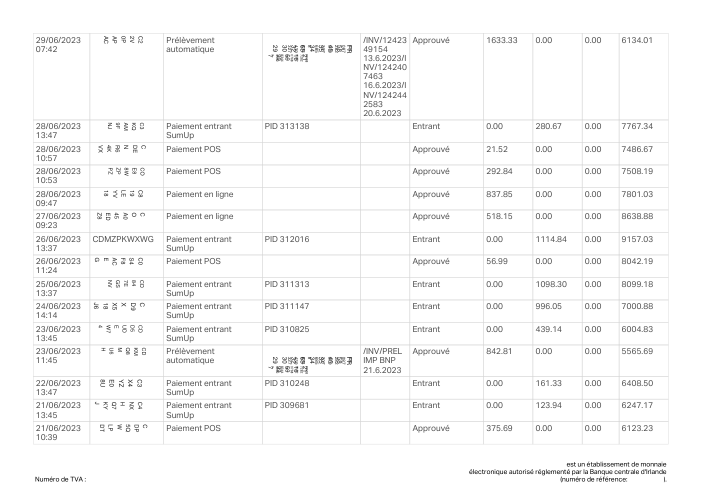
Le jeu de données47 vrais relevés, un par banque
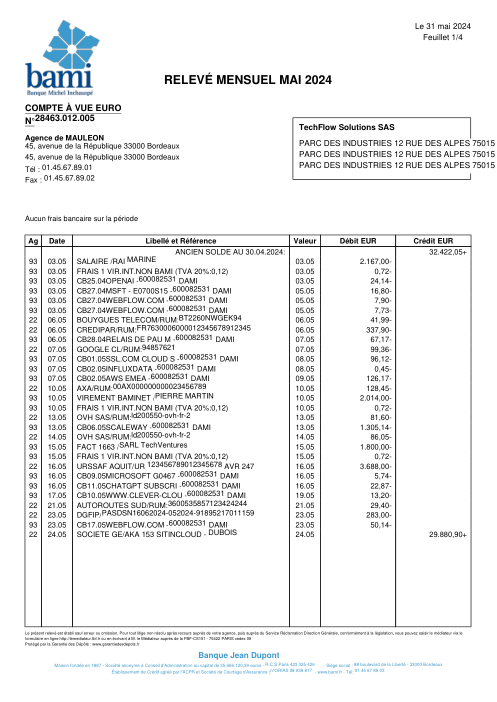
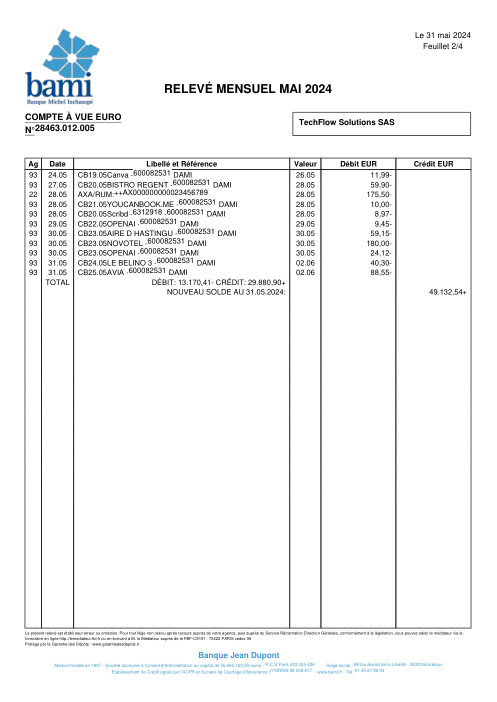
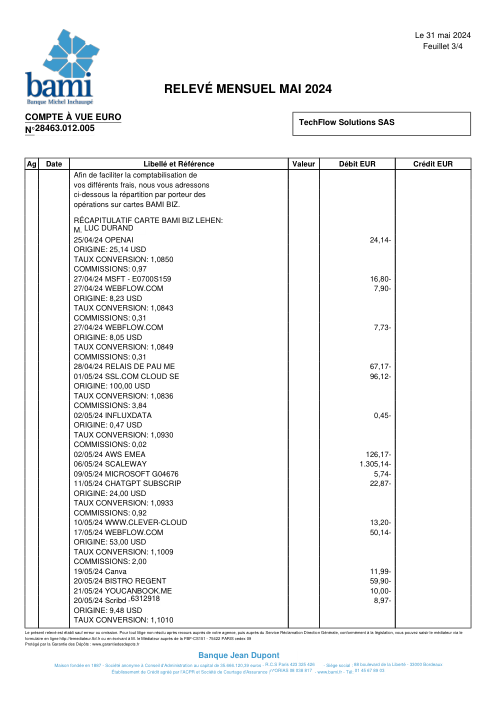
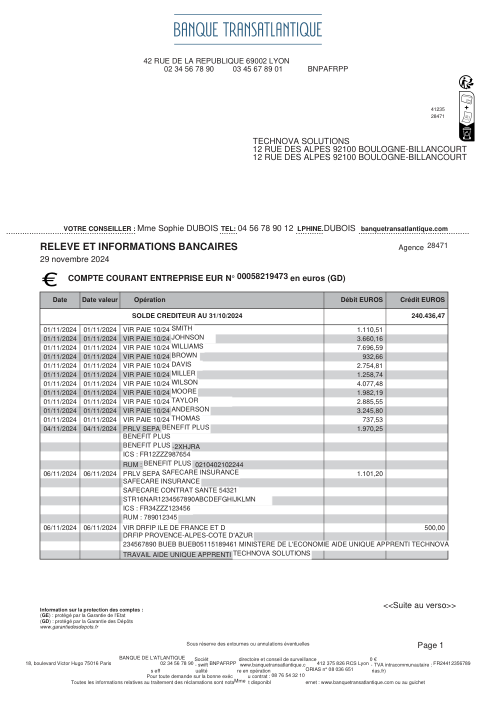
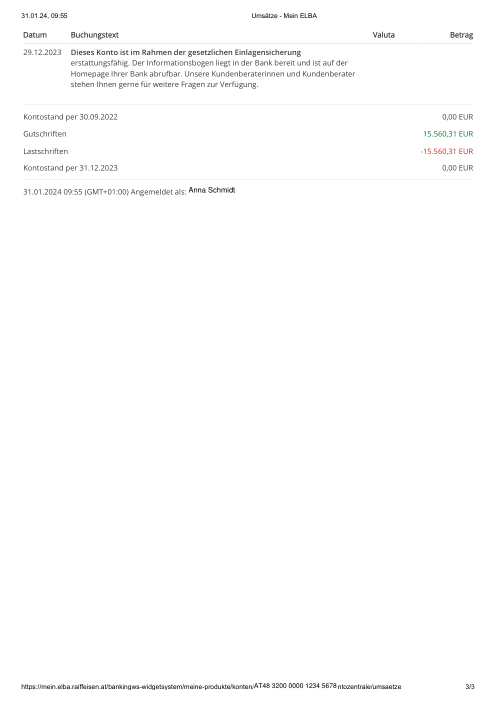
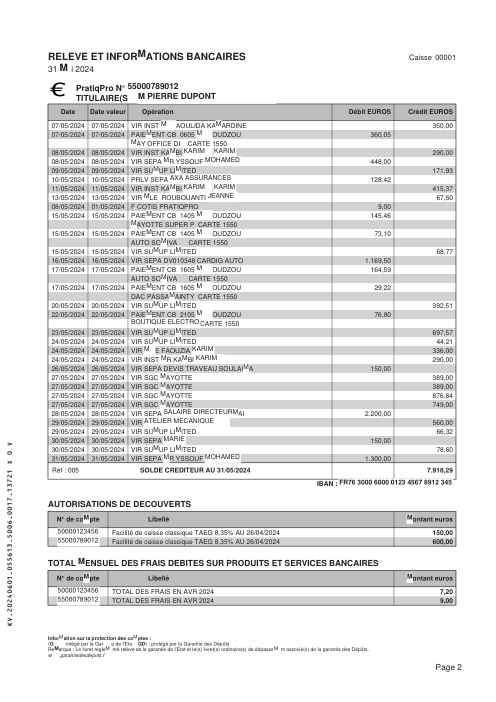
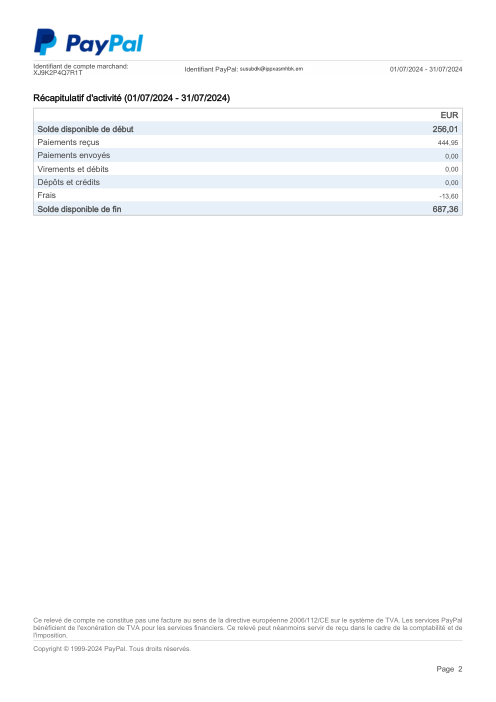
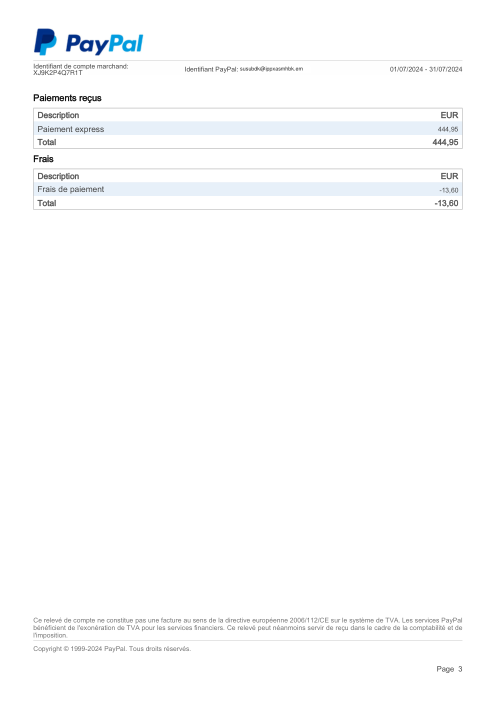
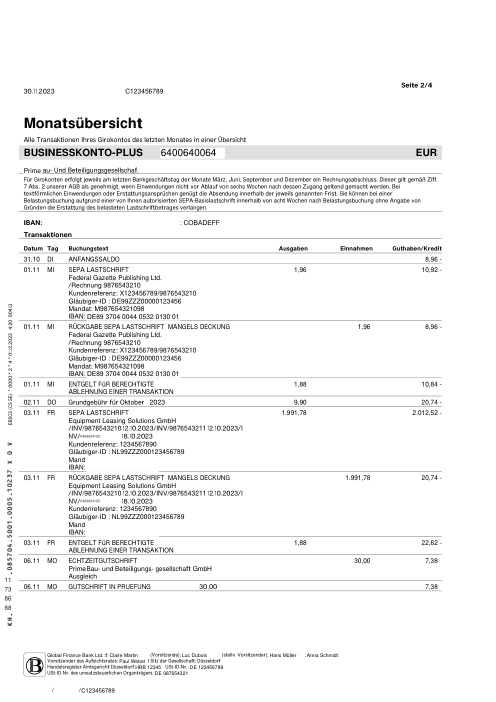
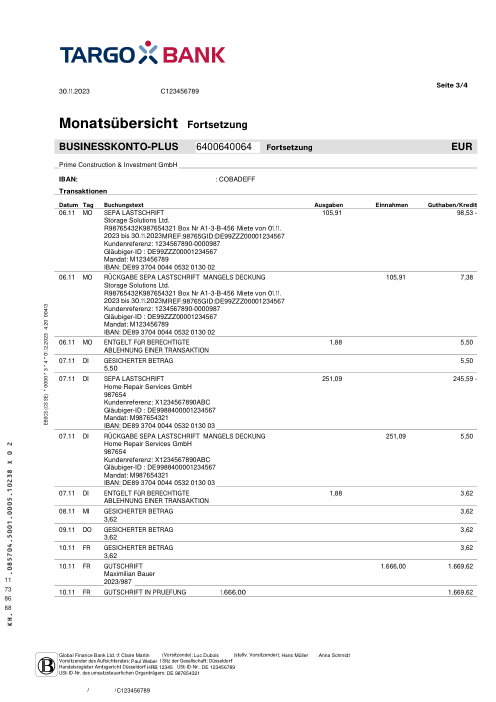
Chaque relevé est réel, puis anonymisé de sorte que la mise en page, les tableaux et les totaux survivent, mais les noms et les chiffres sont synthétiques : grandes banques françaises, banques allemandes, néobanques et EMI, chacune ayant sa propre idée de ce à quoi devrait ressembler un tableau de transactions. Les labels gold ont été vérifiés à la main par rapport aux PDF sources.
Chaque relevé est réel, puis anonymisé de sorte que la mise en page, les tableaux et les totaux survivent, mais les noms et les chiffres sont synthétiques. Cliquez sur n'importe quelle page pour zoomer ; passez à Par banque pour filtrer.























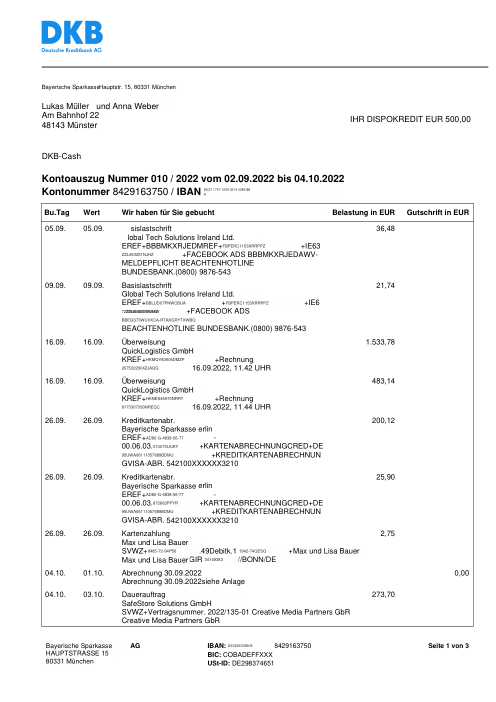


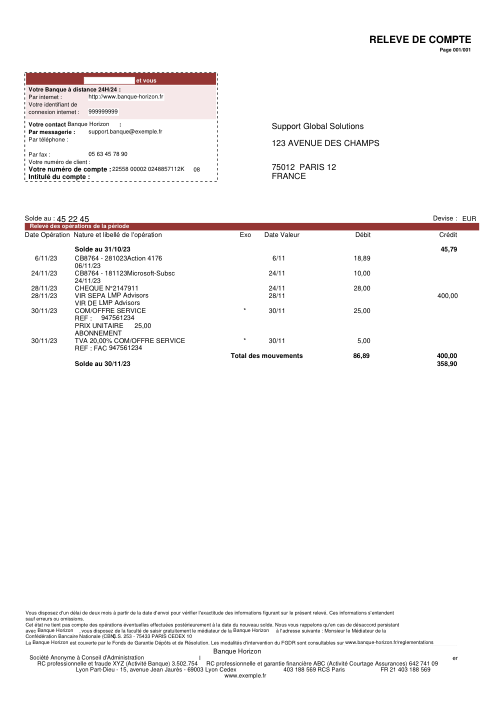








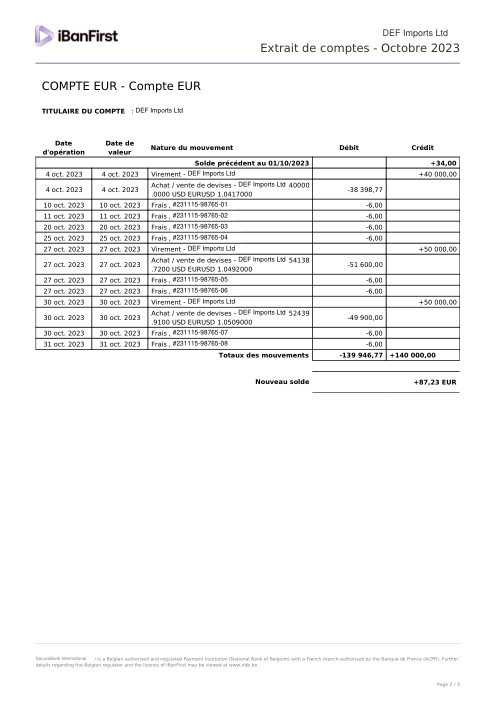
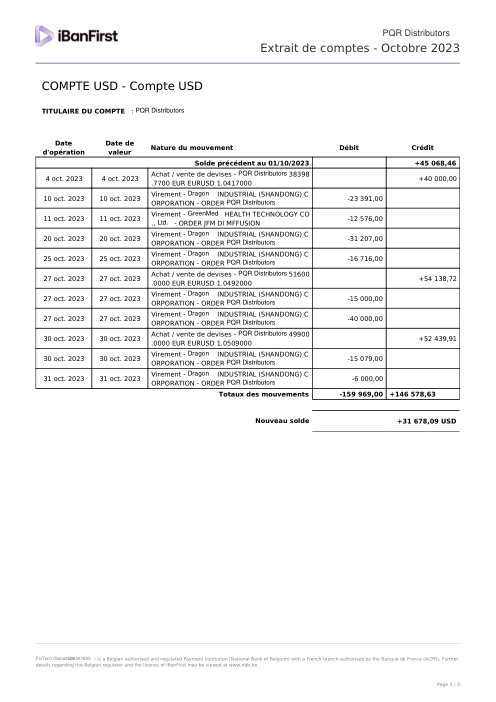










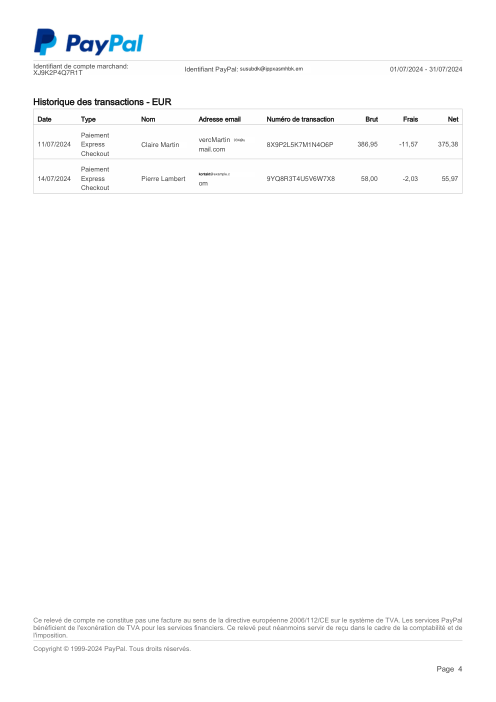


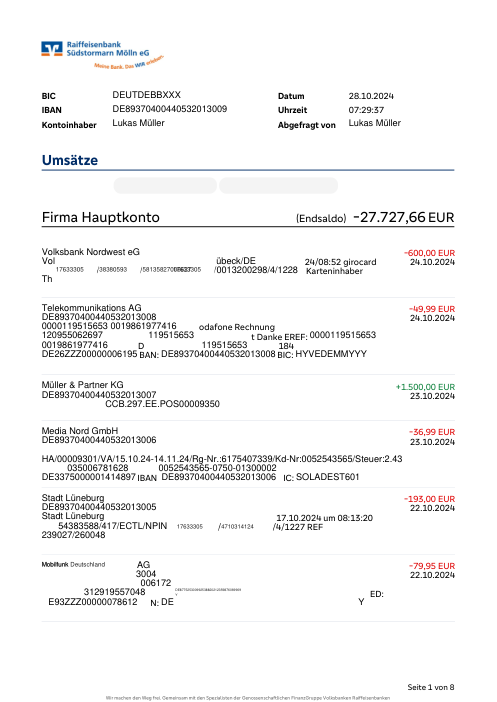


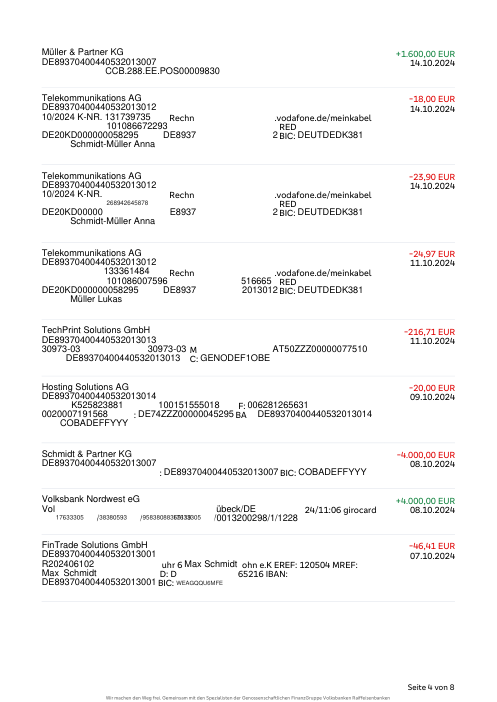


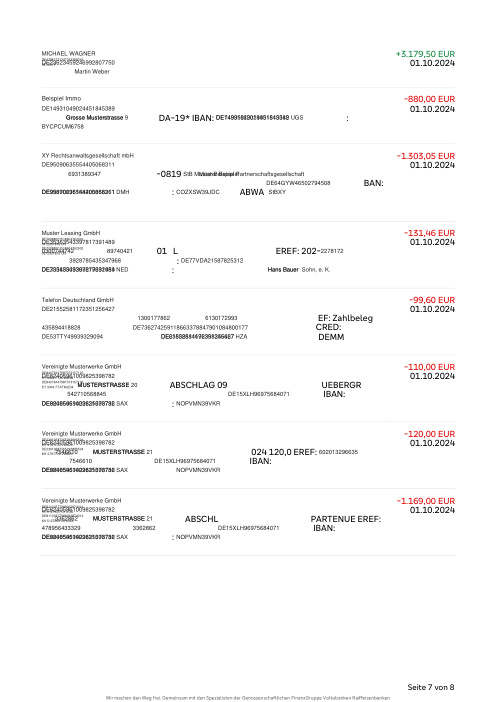











La précision par ligne est une vanity metric
Le chiffre qui compte pour un client n'est pas « quelle fraction des lignes est correcte » mais « ce relevé est-il correct ». Ce ne sont pas les mêmes métriques. Un relevé n'est correct que si chaque ligne l'est, donc une seule ligne manquante ou inventée fait échouer tout le document.
- Par relevé, pas par ligne. holofin extrait 98 % des relevés avec zéro erreur ; le meilleur modèle de pointe atteint 80 %. Sur 44 documents, holofin a produit une ligne erronée ; les modèles de pointe en ont produit 70–115 chacun.
- L'écart vient de l'invention, pas de la lecture. Chaque système lit bien la page (recall 0.88–1.00). holofin invente une ligne sur 44 relevés (0,1 %) ; les modèles de pointe inventent 8–10 % de chaque ligne qu'ils retournent.
- Une fenêtre plus grande n'est pas la solution. Fournir plus de pages par appel ne change rien ; le traitement par page est fiable car il limite l'invention.
Ce que nous avons découvert
Quatre lectures du même benchmark. La première place chaque système sur l'exhaustivité (a-t-il trouvé les lignes ?) par rapport à la précision (les lignes retournées sont-elles réelles ?). Le reste découle de cette arithmétique.
Chaque système trouve les lignes (exhaustivité, x). Ils diffèrent sur le nombre de lignes retournées qui existent réellement (précision, y). holofin se situe dans le coin supérieur droit ; les modèles de pointe chutent sur l'axe de précision à mesure qu'ils inventent. Modèles de pointe affichés par page.
Un relevé n'est correct que si chaque ligne l'est. Part des relevés extraits avec zéro erreur (aucune ligne manquante, aucune ligne inventée) par rapport au gold vérifié à la main. Le sous-label indique le total des lignes erronées sur l'ensemble des 44 documents : holofin en a fait une ; les modèles de pointe en ont fait des dizaines.
Part des transactions retournées qui n'existent pas sur la page. Une ligne inventée se rapproche d'un solde erroné et semble plausible : l'échec silencieux. Modèles de pointe affichés à leur meilleur paramètre (par page).
holofin traite une page à la fois et domine tous les axes. Pour les modèles de pointe, fournir plus de pages par appel ne change rien : le recall baisse un peu, la précision augmente un peu, deux pages est souvent le point d'équilibre. L'écart qui compte est celui avec la barre verte.
Aucun agrégat derrière lequel se cacher. Voici le décompte brut des lignes erronées (manquantes + inventées, vs gold) sur chaque relevé, par modèle, avec le paramètre par page. Lisez la colonne de holofin de haut en bas : elle est vide. · = propre ; nombres = erreurs sur ce document.
La destruction silencieuse de la ligne inventée
Ce n'est pas un échec de lecture de l'encre sur la page. Si une transaction est visiblement imprimée, chaque modèle la trouve. Le problème est ce qu'ils trouvent quand la transaction n'y est pas. Il y a une différence opérationnelle massive entre une ligne manquante et une ligne inventée. Une ligne manquante est ennuyeuse : le solde ne correspond pas et un opérateur repère l'écart. Une ligne inventée est un tueur silencieux. Le modèle récupère un solde courant, un sous-total ou une date isolée et le formate comme une transaction valide. Cela semble parfaitement plausible. Cela empoisonne simplement l'arithmétique, lentement et de manière invisible.
Le gold est humain, pas un modèle
Nous n'avons pas laissé un modèle évaluer d'autres modèles. La vérité terrain (ground truth) a été construite à la main : sur chaque document où les systèmes étaient en désaccord, une personne a ouvert le PDF source et vérifié les transactions ligne par ligne. Le benchmark évalue par rapport à ce qui est réellement imprimé sur la page, vérifié par un humain, et non par rapport à l'opinion d'un autre modèle.
MéthodologieComment le benchmark est conçu
Les modèles de pointe candidats reçoivent des images de pages avec un prompt d'extraction générique à trois tailles de contexte. holofin est la véritable pipeline de production (classification → OCR → extraction par page), pilotée via HTTP. Chaque métrique est doc-macro : calculée par document, puis moyennée.
La vérification de production évidente est de savoir si les calculs d'un relevé tombent juste : solde d'ouverture + Σ transactions = solde de clôture. Nous l'avons mesuré, et c'est nécessaire mais non suffisant comme métrique de vérité. Les relevés de GPT-5.5 se rapprochent 42/45 du temps, pourtant il invente toujours ~8 % des lignes par rapport à la page réelle ; une ligne inventée compensée par une autre erreur tombe toujours juste, et un modèle qui omet entièrement les soldes (Gemini les a laissés vides sur 12 documents) ne peut pas être vérifié du tout. Un relevé peut réussir les calculs et être quand même faux. Nous évaluons donc chaque transaction par rapport au gold qui a été vérifié à la main avec le PDF source.
Vous n'avez pas besoin d'une plus grande fenêtre. Vous avez besoin d'un cadre de contrôle.
On ne résout pas l'extraction en passant un PDF entier à un endpoint et en demandant à un modèle de faire attention. Chez holofin, c'est la description du poste. Nous construisons la cage dans laquelle l'intelligence s'exécute :
- La structure avant la sémantique. L'OCR déterministe et la géométrie construisent d'abord le contexte de la page. Les prompts capturent bien le sens et mal la structure visuelle.
- Délimiter le problème. Nous traitons strictement par page, sans jamais demander à un modèle de conserver un grand livre entier dans sa mémoire de travail.
- Contraintes > vibes. Des règles comptables strictes décident de ce qui compte comme une transaction avant même qu'un résultat ne soit finalisé.
Une fois que vous avez écrit suffisamment d'échafaudages pour être en sécurité (la redondance OCR, la géométrie de délimitation, les parsers stricts, les rapprochements), le modèle n'est plus le héros. C'est le spécialiste que vous appelez pour les litiges et les cas particuliers (edge cases). Le travail ne consiste pas à éliminer les parties ennuyeuses ; il consiste à construire des choses ennuyeuses pour que la magie ait une base solide sur laquelle s'appuyer.
Articles connexes

Votre extracteur de tableaux a réussi le test. Pas les chiffres.
Une auditrice ouvre votre résultat d'extraction pour un bilan. Le modèle affiche une précision par cellule de 99,2 %. Impressionnant. Puis elle fait le total de la colonne des actifs à la main, comme le font les auditeurs, et obtient un chiffre décalé d'une ligne. Les actifs ne sont plus égaux au passif plus les capitaux propres. Le bilan ne s'équilibre pas.

Détection de fraude documentaire : ce qu'un PDF ne peut pas cacher
Nous pensions que la fraude documentaire était un problème visuel. Mauvaises polices. Colonnes mal alignées. Un logo qui semblait légèrement décalé. Nous avons construit des vérifications basées sur ce que les humains voient, car ce que les humains voient était tout ce que nous avions.

Quand les documents contre-attaquent
Page 1 : Résumé du compte, deux colonnes. Page 15 : Même compte, trois colonnes, noms d'en-tête différents. Page 47 : Un scan avec une tache de café. Page 89 : La page des totaux, qui fait référence à des transactions que vous avez extraites il y a 70 pages.